Data-driven 2021: Predictions for a new year in data, analytics and AI
DataKitchen
JANUARY 4, 2021
The post Data-driven 2021: Predictions for a new year in data, analytics and AI first appeared on DataKitchen.

DataKitchen
JANUARY 4, 2021
The post Data-driven 2021: Predictions for a new year in data, analytics and AI first appeared on DataKitchen.

Cloudera
JANUARY 6, 2021
Introduction. Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. For data professionals that want to make use of data stored in HBase the recent upstream project “hbase-connectors” can be used with PySpark for basic operations.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Teradata
JANUARY 5, 2021
By leveraging data to create a 360 degree view of its citizenry, government agencies can create more optimal experiences & improve outcomes such as closing the tax gap or improving quality of care.

Team Data Science
JANUARY 8, 2021
Big Data has become the dominant innovation in all high-performing companies. Notable businesses today focus their decision-making capabilities on knowledge gained from the study of big data. Big Data is a collection of large data sets, particularly from new sources, providing an array of possibilities for those who want to work with data and are enthusiastic about unraveling trends in rows of new, unstructured data.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

Start Data Engineering
JANUARY 6, 2021
What is backfilling ? Setup Prerequisites Apache Airflow - Execution Day Backfill Conclusion Further Reading References What is backfilling ? Backfilling refers to any process that involves modifying or adding new data to existing records in a dataset. This is a common use case in data engineering. Some examples can be a change in some business logic may need to be applied to an already processed dataset.

Confluent
JANUARY 7, 2021
At Zendesk, Apache Kafka® is one of our foundational services for distributing events among different internal systems. We have pods, which can be thought of as isolated cloud environments where […].
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

|

Data Engineering Podcast
JANUARY 4, 2021
Summary As more organizations are gaining experience with data management and incorporating analytics into their decision making, their next move is to adopt machine learning. In order to make those efforts sustainable, the core capability they need is for data scientists and analysts to be able to build and deploy features in a self service manner.

DataKitchen
JANUARY 6, 2021
Savvy executives maximize the value of every budgeted dollar. Decisions to invest in new tools and methods must be backed up with a strong business case. As data professionals, we know the value and impact of DataOps: streamlining analytics workflows, reducing errors, and improving data operations transparency. Being able to quantify the value and impact helps leadership understand the return on past investments and supports alignment with future enterprise DataOps transformation initiatives.

Teradata
JANUARY 3, 2021
Digital payments generate 90% of financial institutions’ useful customer data. How can they exploit its value? Find out more.

Cloudera
JANUARY 5, 2021
In my last two blogs ( Get to Know Your Retail Customer: Accelerating Customer Insight and Relevance, and Improving your Customer-Centric Merchandising with Location-based in-Store Merchandising ) we looked at the benefits to retail in building personalized interactions by accessing both structured and unstructured data from website clicks, email and SMS opens, in-store point sale systems and past purchased behaviors.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Data Council
JANUARY 7, 2021
Orchest is an open-source tool for creating data science pipelines. Its core value proposition is to make it easy to combine notebooks and scripts with a visual pipeline editor (“build”); to make your notebooks executable (“run”); and to facilitate experiments (“discover”).

DataKitchen
JANUARY 5, 2021
Remote working has revealed the inconsistency and fragility of workflow processes in many data organizations. The data teams share a common objective; to create analytics for the (internal or external) customer. Execution of this mission requires the contribution of several groups: data center/IT, data engineering, data science, data visualization, and data governance.

Teradata
JANUARY 7, 2021
The problem for regulators & for banks alike is agreeing what good data looks like & how to share it to create a modern, flexible, shared data model. Read more.

Rock the JVM
JANUARY 4, 2021
Explore one of the most essential concepts in pure functional programming: the Functor, a crucial but abstract idea that will challenge your understanding

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri

Silectis
JANUARY 3, 2021
If you’re new to data engineering or are a practitioner of a related field, such as data science, or business intelligence, we thought it might be helpful to have a handy list of commonly used terms available for you to get up to speed. This data engineering glossary is by no means exhaustive, but should provide some foundational context and information.
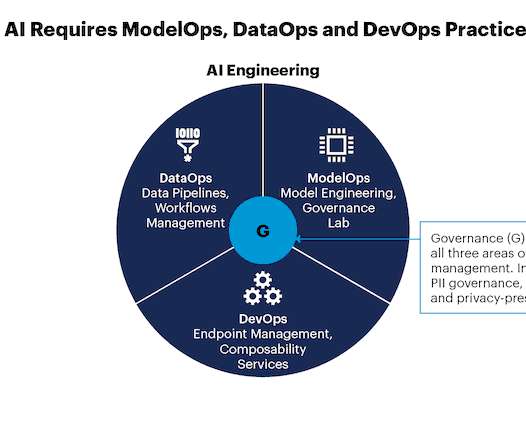
DataKitchen
JANUARY 2, 2021
In Gartner’s recent report, Operational AI Requires Data Engineering, DataOps, and Data-AI Role Alignment , Robert Thanaraj and Erick Brethenoux recognize that “organizations are not familiar with the processes needed to scale and promote artificial intelligence models from the prototype to the production stages; resulting in uncoordinated production deployment attempts.”.

Rock the JVM
JANUARY 4, 2021
Explore one of the most essential concepts in pure functional programming: the Functor, a crucial but abstract idea that will challenge your understanding

Expert insights. Personalized for you.






Let's personalize your content