This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a recap from the last article , Uber’s API Gateway provides an interface and acts as a single point of access for all of our back-end services to expose features and data to Mobile and 3rd party partners. Two … The post Scaling of Uber’s API gateway appeared first on Uber Engineering Blog.
Managing Apache Kafka® clusters can be tricky sometimes. To solve this problem, Confluent Control Center helps you easily manage and monitor your clusters and interact with other Confluent components, such […].
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight.
At the end of March, we released the first version of Cloudera SQL StreamBuilder as part of CSA 1.3. It enabled users to easily write, run and manage real-time SQL queries on streams from Apache Kafka with an exceptionally smooth user experience. . Since then, we have been working hard to expose the full power of Apache Flink SQL and the existing Data Warehousing tools in CDP to combine it into a state-of-the-art real-time analytics platform.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Summary Google pioneered an impressive number of the architectural underpinnings of the broader big data ecosystem. Now they offer the technologies that they run internally to external users of their cloud platform. In this episode Lak Lakshmanan enumerates the variety of services that are available for building your various data processing and analytical systems.
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. But which one of the celebrities should you entrust your information assets to? To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop?
Cloudera has been named as a Strong Performer in the Forrester Wave for Streaming Analytics, Q2 2021. We are excited to be recognized in this wave at, what we consider to be, such a strong position. We are proud to have been named as one of “ The 14 providers that matter most ” in streaming analytics. The report states that richness of analytics, development tool options and near-effortless scalability are what streaming analytics customers should look for in a provider. .
Summary The way to build maintainable software and systems is through composition of individual pieces. By making those pieces high quality and flexible they can be used in surprising ways that the original creators couldn’t have imagined. One such component that has gone above and beyond its originally envisioned use case is BookKeeper, a distributed storage system that is optimized for durability and speed.
For a modern, software-defined business, a platform for data in motion is critical to connecting every part of a vast digital architecture across an organization to harness the flow of […].
In the 1980s, American Airlines and its former president Robert Crandall started a revolution in airline pricing. Crandall is famous for many airline innovations that we use today, such as inventing the first frequent flier program and contributing to route optimization and central reservation system adoption. But he also pioneered yield management — the set of price optimization strategies that preceded revenue management.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
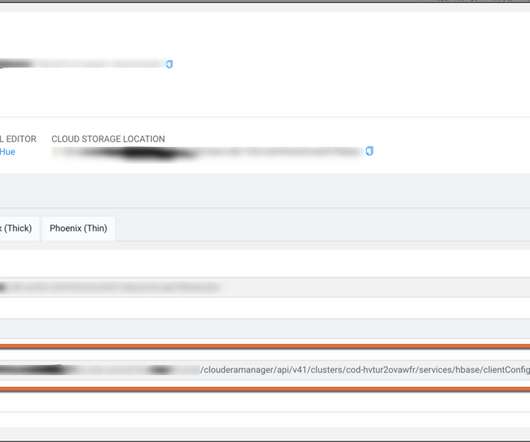
Apache Spark is a very popular analytics engine used for large-scale data processing. It is widely used for many big data applications and use cases. CDP Operational Database Experience Experience (COD) is a CDP Public Cloud service that lets you create and manage operational database instances and it is powered by Apache HBase and Apache Phoenix. .
This blog on Data Science vs. Data Engineering presents a detailed comparison between the two domains. The first two sections briefly overview the two domains and some significant differences. As we proceed further into the blog, you will find some statistics on data engineering vs. data science jobs and data engineering vs. data science salary, along with an in-depth comparison between the two roles- data engineer vs. data scientist.
Next.js is a super powerful tool for building scalable websites and web applications. Building dynamic web pages is no big thing with Next. I had a scenario pop up in which I wanted to generate and deliver JSON pages. I wanted to retrieve the data from elsewhere and then output it to a file that didn't have to change between builds. Limitations of Pages in Next.js Part of the reason Next is equal parts powerful and easy to use is a result of the opinions it brings along.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
If you have read our previous post focusing on the challenges of planning, launching and scaling IIOT use cases , you’ve narrowed down the business problems you’re trying to solve, and you have a plan that is both created by the implementation team and supported by executive management. Here’s a plan to make sure you’ve got it all down. . Think of these success factors like the legs of a kitchen table and the results that you desire, a bowl of homemade chicken soup.
With so much data being collected during the manufacturing & sales process, & augmented by connected vehicles, there are emerging opportunities for R&D teams to mine this data for new insights.
The chatbot market is anticipated to grow at a CAGR of 23.5% reaching USD 10.5 billion by end of 2026. Facebook has over 300,000 active chatbots. According to a Uberall report, 80 % of customers have had a positive experience using a chatbot. According to IBM, organizations spend over $1.3 trillion annually to address novel customer queries and chatbots can be of great help in cutting down the cost to as much as 30%.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
In October of 2020 Cloudera acquired Eventador and Cloudera Streaming Analytics (CSA) 1.3.0 was released early in 2021. It was the first release to incorporate SQL Stream Builder (SSB) from the acquisition, and brought rich SQL processing to the already robust Apache Flink offering. The team’s focus turned to bringing Flink Data Definition Language ( DDL) and the batch interface into SSB with that completed.
Financial crimes are here to stay. But fighting fraudsters isn’t just a matter of investing more money in analytics. Find out what your organization needs to catch a clever criminal.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
A sturdy data infrastructure coupled with a proficient workforce are pillars for an organization’s digital transformation efforts. . McKinsey lists building capabilities for the workforce of the future as one of five categories of factors improving the chances of a successful digital transformation. Investing the right amount in digital talent and scaling up workforce planning and talent development could make transformation success up to three times more likely. .
This article on Data Engineering: Perception vs. Reality will help you uncover various facts and trends surrounding one of the groundbreaking trends in today's market i.e. Data Engineering.
What Is Change Data Capture? Change data capture (CDC) is the process of recognising when data has been changed in a source system so a downstream process or system can action that change. A common use case is to reflect the change in a different target system so that the data in the systems stay in sync. There are many ways to implement a change data capture system, each of which has its benefits.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
Trino unlocks new entire workflows for Apache Superset, like querying NoSQL databases (MongoDB, Cassandra, and more) and joining data from multiple but separate databases.
The primary source of information about DataOps is from vendors (like DataKitchen) who sell enterprise software into the fast-growing DataOps market. There are over 70 vendors that would be happy to assist in your DataOps initiative. Here’s something you likely won’t hear from any of them (except us) – you can start your DataOps journey without buying any software.
This article on Meaningful Lead Engagement Through Product Usage Enrichment will highlight how placing customer usage data in the sales team’s hands unlocks their ability to have educated and well-timed conversations with potential customers.
Learn how four pharma companies are quickly identifying new opportunities, improving research efficiency & accelerating new product adoption with DataOps. The post DataOps: The New Normal in Pharma first appeared on DataKitchen.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content