This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data orchestrators have been essential since the inception of data workloads, because you need something to orchestrate your tasks and your business logic. In the old days that might have been a Makefile or a cron job. But these days, with the challenges and complexity rising exponentially, and the tools still exploding, the orchestrator is the heart of any data engineering project, potentially any data platform.
Managing and utilizing data effectively is crucial for organizational success in today's fast-paced technological landscape. The vast amounts of data generated daily require advanced tools for efficient management and analysis. Enter agentic AI, a type of artificial intelligence set to transform enterprise data management. As the Snowflake CTO at Deloitte, I have seen the powerful impact of these technologies, especially when leveraging the combined experience of the Deloitte and Snowflake allia
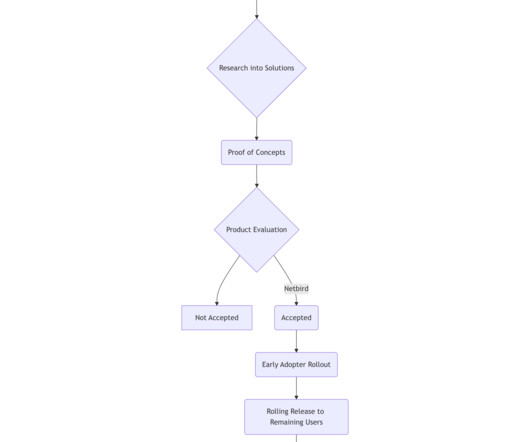
(Written by Kirill Voloshin & Abdullah Abusamrah ) In our previous blog posts , we have covered our server-driven UI framework called Picnic Page Platform. This framework allows anyone, including analysts and business teams, to leverage data across all of Picnic to build and ship new UI flows. This blog post explores how weve further evolved our framework to support more complex flows that interact with our back-end systems, persist data andmore.
Glossary ZTA: zero trust architecture SAML: security assertion markup language (an SSO facilitation protocol) Devbox: a remote server used to develop software Zero Trust Access Remote Future Yelp is now a fully remote company, which means our employee base has become increasingly distributed across the world, making secure access to resources from anywhere a critical business function.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
👋 Hi, this is Gergely with a free issue of the Pragmatic Engineer Newsletter. We cover two out of seven topics in today’s subscriber-only deepdive: Tech hiring: is this an inflection point? If you’ve been forwarded this email, you can subscribe here. Before we start: I do one conference talk every year, and this year it will be a keynote at LDX3 in London, on 16 June.
Introducing Apache Airflow® 3.0 Be among the first to see Airflow 3.0 in action and get your questions answered directly by the Astronomer team. You won't want to miss this live event on April 23rd! Save Your Spot → Stanford HAI: AI Index 2025 - State of AI in 10 Charts Stanford gives an insight into AI adoption in the industry with the AI adoption.
Microsoft Fabric has become a key platform in the quickly changing field of data engineering, providing extensive tools for data integration, transformation, and analysis. “Microsoft Fabric Data Engineer Associate ” is the official title of the DP-700, which is intended to verify professionals’ proficiency in using Microsoft Fabric to create reliable data solutions.
Shifting left is an interesting concept that’s gaining momentum in modern data engineering. SDF has been among those sharing this approach, even making “shifting left” one of their main slogans. As Elias DeFaria, SDF’s co-founder, describes it, shifting left means “improving data quality by moving closer toward the data source” However, the benefits extend beyond just data quality improvements.
Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. The ecosystem is louder, flashier, and more fragmented. Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” Vendors promise magic, just plug in their tool and watch your insights appear.… Read more The post How To Set Up Your Data Infrastructure In 2025 Part 1 appeared first on Seattle Data Guy.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Snowflake Cortex AI now features native multimodal AI capabilities, eliminating data silos and the need for separate, expensive tools. Introducing Cortex AI COMPLETE Multimodal , now in public preview. This major enhancement brings the power to analyze images and other unstructured data directly into Snowflakes query engine, using familiar SQL at scale.
AI and analytics have the potential to transform decision-making, streamline operations, and drive innovation. But theyre only as good as the data they rely on. If the underlying data is incomplete, inconsistent, or delayed, even the most advanced AI models and business intelligence systems will produce unreliable insights. Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
1. Introduction 2. APIs are a way to communicate between systems on the Internet 2.1. HTTP is a protocol commonly used for websites 2.1.1. Request: Ask the Internet exactly what you want 2.1.2. Response is what you get from the server 3. API Data extraction = GET-ting data from a server 3.1. GET data 3.1.1. GET data for a specific entity 3.
There is little doubt that GenAI will have an impact on almost every aspect of our business and personal lives. However, we are at an interesting juncture: models are becoming ever more powerful, with prototypes showing ever greater promise, but there remain significant challenges when it comes to the reality of putting this technology into practice.
Welcome to Snowflakes Startup Spotlight, where we learn about awesome companies building businesses on Snowflake. In this edition, discover how Houssam Fahs, CEO and Co-founder of KAWA Analytics , is on a mission to revolutionize the creation of data-driven applications with a cutting-edge, AI-native platform built for scalability. What inspires you as a founder?
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Data Quality When You Dont Understand the Data : Data Quality Coffee With Uncle Chip #3 Lets be honestdata quality feels impossible when you dont understand the data. And in large organizations, thats not a rare problem. Its the norm. Ive seen it firsthand: massive data estates maintained by teams who dont know what the numbers, strings, or categories in their tables really mean.
There is little doubt that (Generative) AI will have an impact on almost every aspect of our business and personal lives. However, we are at an interesting juncture: models are becoming ever more powerful, with prototypes showing ever greater promise, but there remain significant challenges when it comes to the reality of putting this technology into practice.
A private or enterprise cloud is the type of cloud computing in which all the resources are dedicated to a single tenant. Private cloud allows organizations a high level of cloud computing benefits such as scalability, flexibility, access control, and faster service delivery. This blog explores the fundamentals of the private cloud framework. Lets learn […] The post Private Cloud appeared first on WeCloudData.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
There is little doubt that (Generative) AI will have an impact on almost every aspect of our business and personal lives. However, we are at an interesting juncture: models are becoming ever more powerful, with prototypes showing ever greater promise, but there remain significant challenges when it comes to the reality of putting this technology into practice.
Hybrid cloud computing is a type of cloud computing that combines the benefits of both private and public clouds. It has emerged as a pivotal strategy for organizations aiming to balance scalability, agility, and control. The hybrid cloud empowers businesses to optimize performance, enhance security, and drive innovation. This blog explores the current landscape of […] The post Hybrid Cloud appeared first on WeCloudData.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Introduction GitHub Copilot isn’t like other code completion tools. Artificial intelligence (AI) powers this cutting-edge writing assistant that could change the way we write code. We will discuss the key concepts and characteristics of Copilot that revolutionize the software development industry. What is GitHub Copilot? It is an AI-powered writing assistant that was made by GitHub and OpenAI working together.
Welcome to the Data Quality Coffee Series with Uncle Chip Pull up a chair, pour yourself a fresh cup, and get ready to talk shopbecause its time for Data Quality Coffee with Uncle Chip. This video series is where decades of data experience meet real-world challenges, a dash of humor, and zero fluff. Uncle Chipaka Charles Bloche of DataKitchenhas spent his career deep in the trenches of data engineering, wrangling pipelines, building platforms, and navigating the all-too-familiar chaos of data qu
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content