This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
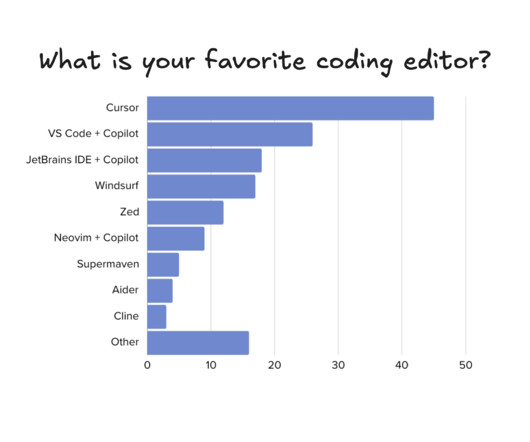
It’s been nearly 6 months since our research into which AI tools software engineers use, in the mini-series, AI tooling for software engineers: reality check. At the time, the most popular tools were ChatGPT for LLMs, and GitHub copilot for IDE-integrated tooling. Then this summer, I saw the Cursor IDE becoming popular around when Anthropic’s Sonnet 3.5 model was released, which has superior code generation compared to ChatGPT.
After 10 years of Data Engineering work, I think it’s time to hang up the proverbial hat and ride off into the sunset, never to be seen again. I wish. Everything has changed in 10 years, yet nothing has changed in 10 years, how is that even possible? Sometimes I wonder if I’ve learned anything […] The post What I’ve Learned After A Decade Of Data Engineering appeared first on Confessions of a Data Guy.
The below was originally published in The Pragmatic Engineer. To get timely analysis on the tech industry like this, on a weekly basis: sign up to The Pragmatic Engineer Newsletter. If you are into podcasts, check out The Pragmatic Engineer Podcast. Imagine Apple decided Spotify was a big enough business threat that it had to take unfair measures to limit Spotify’s growth on the App Store.
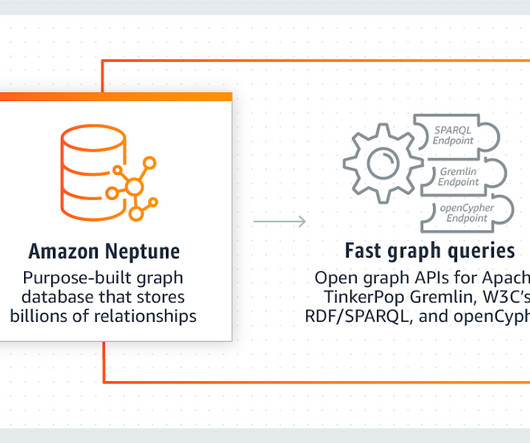
Introduction Managing complicated, interrelated information is more important than ever in today’s data-driven society. Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases. These powerful tools are designed to manage and query intricate data relationships effortlessly.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
What will data engineering look like in 2025? How will generative AI shape the tools and processes Data Engineers rely on today? As the field evolves, Data Engineers are stepping into a future where innovation and efficiency take center stage. GenAI is already transforming how data is managed, analyzed, and utilized, paving the way for […] The post Top 11 GenAI Powered Data Engineering Tools to Follow in 2025 appeared first on Analytics Vidhya.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of three topics from last week’s subscriber-only The Pulse issue. Today, full subscribers got access to a comprehensive Senior-and-above tech compensation research.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of three topics from last week’s subscriber-only The Pulse issue. Today, full subscribers got access to a comprehensive Senior-and-above tech compensation research.
1. Introduction 2. Docker concepts 2.1. Define the OS and its configurations with an image 2.2. Use the image to run containers 2.2.1. Communicate between containers and local OS 2.2.2. Start containers with docker CLI or compose 3. Conclusion 1. Introduction Docker can be overwhelming to start with. Most data projects use Docker to set up the data infra locally (and often in production).
As we approach the new year, it's time to gaze into the crystal ball and ponder the future. In this post, we delve into predictions for 2025, focusing on the transformative role of AI agents, workforce dynamics, and data platforms. Join Ananth Packkildurai, Ashwin Ashish, and Rajesh as they unravel the future and guide us through the fascinating changes ahead.
There are plenty of statistics about the speed at which we are creating data in today’s modern world. On the flip side of all that data creation is a need to manage all of that data and thats where data teams come in. But leading these data teams is challenging and yet many new data… Read more The post From IC to Data Leader: Key Strategies for Managing and Growing Data Teams appeared first on Seattle Data Guy.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
According to industry experts, 2024 was destined to be a banner year for generative AI. Operational use cases were rising to the surface, technology was reducing barriers to entry, and general artificial intelligence was obviously right around the corner. So… did any of that happen? Well, sort of. Here at the end of 2024, some of those predictions have come out piping hot.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction. This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance.
For years, companies have operated under the prevailing notion that AI is reserved only for the corporate giants — the ones with the resources to make it work for them. But as technology speeds forward, organizations of all sizes are realizing that generative AI isn’t just aspirational: It’s accessible and applicable now. With Snowflake’s easy-to-use, unified AI and data platform, businesses are removing the manual drudgery, bottlenecks and error-prone labor that stymie productivity, and are usi
Mountains I hope this e-mail finds you well, wherever you are. I'd like to thank you for the excellent comments you sent me last week after the publication of the first version of the Recommendations. This is just the beginning! This week I've added a subscribe button in the Recommendations page in order for you to opt-in for the weekly recommendation email—every Tuesday.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Large Language Models (LLMs) will be at the core of many groundbreaking AI solutions for enterprise organizations. Here are just a few examples of the benefits of using LLMs in the enterprise for both internal and external use cases: Optimize Costs. LLMs deployed as customer-facing chatbots can respond to frequently asked questions and simple queries.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Multiple open source projects and vendors have been working together to make this vision a reality. In this episode Dain Sundstrom, CTO of Starburst, explains how the combination of the Trino query engine and the Iceberg table format offer the ease of use and execution speed of data warehouses with the infinite storage and sc
See a longer version of this article here: Scaling ChatGPT: Five Real-World Engineering Challenges. Sometimes the best explanations of how a technology solution works come from the software engineers who built it. To explain how ChatGPT (and other large language models) operate, I turned to the ChatGPT engineering team. "How does ChatGPT work, under the hood?
1. Introduction 2. Setup 3. Parts of data engineering 3.1. Requirements 3.1.1. Understand input datasets available 3.1.2. Define what the output dataset will look like 3.1.3. Define SLAs so stakeholders know what to expect 3.1.4. Define checks to ensure the output dataset is usable 3.2. Identify what tool to use to process data 3.3. Data flow architecture 3.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Agentic AI, small data, and the search for value in the age of the unstructured datastack. Image credit: MonteCarlo According to industry experts, 2024 was destined to be a banner year for generative AI. Operational use cases were rising to the surface, technology was reducing barriers to entry, and general artificial intelligence was obviously right around thecorner.
Unapologetically Technical’s newest episode is now live! In this episode of Unapologetically Technical, I interview Cliff Crosland, the co-founder and CEO of Scanner.dev. Cliff Crosland is a data engineer passionate about helping people wrangle massive log volumes. He sees logs as a treasure trove of insights and believes effective log analysis is critical in today’s complex systems.
Scraping data from PDFs is a right of passage if you work in data. Someone somewhere always needs help getting invoices parsed, contracts read through, or dozens of other use cases. Most of us will turn to Python and our trusty list of Python libraries and start plugging away. Of course, there are many challenges… Read more The post Challenges You Will Face When Parsing PDFs With Python – How To Parse PDFs With Python appeared first on Seattle Data Guy.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights. Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out?
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. We kick off with a few topics focused on how were empowering Netflix to efficiently produce and effectively deliver high quality, actionable analytic insights across the company.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. For organizations considering moving from a legacy data warehouse to Snowflake, looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or assessing new options if your current cloud data warehouse just isn’t scaling anymore, it helps to see how others have done it.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making. Cloudera’s mission since its inception has been to empower organizations to transform all their data to deliver trusted, valuable, and predictive insights.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Key Takeaways: Data mesh is a decentralized approach to data management, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. Both approaches empower your organization to be more agile, data-driven, and responsive so you can make informed decisions in real time.
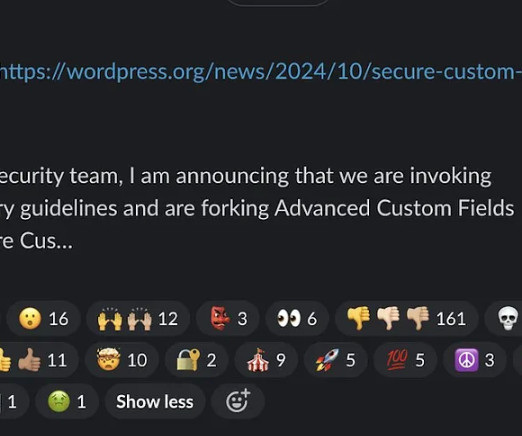
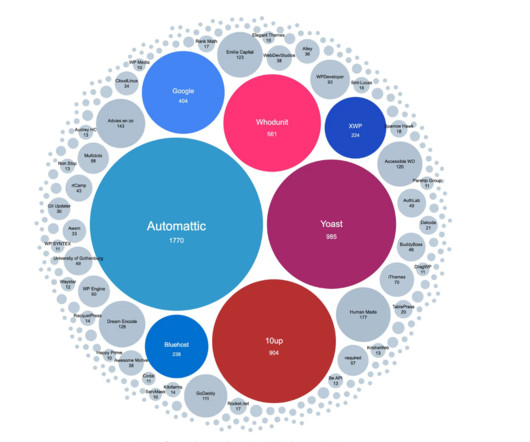
Automattic, creator of Wordpress, is being sued by one of the largest WordPress hosting providers. The conflict fits into a trend of billion-dollar companies struggling to effectively monetize open source, and are changing tactics to limit their competition and increase their revenue. This article was originally published a week ago, on 3 October 2024, in The Pragmatic Engineer.
1. Introduction 2. Run Data Pipelines 2.1. Run on codespaces 2.2. Run locally 3. Projects 3.1. Projects from least to most complex 3.2. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Conclusion 1. Introduction Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up!
Scrum is a quality-driven process for producing excellent business outcomes. Organizations are looking for professional product owners that grasp this notion and can use it in the real world. Employers use many credentialing services to certify levels of comprehension and application by level, which are referred to as belts. Scrum training sessions, along with resources like a PSPO study guide, assist you in learning PSPO I principles, studying efficiently and effectively to pass your exam, adva
Speaker: Jay Allardyce, Deepak Vittal, Terrence Sheflin, and Mahyar Ghasemali
As we look ahead to 2025, business intelligence and data analytics are set to play pivotal roles in shaping success. Organizations are already starting to face a host of transformative trends as the year comes to a close, including the integration of AI in data analytics, an increased emphasis on real-time data insights, and the growing importance of user experience in BI solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content