This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This enables choreographed service collaborations, where many components can subscribe to events stored in the event log and react to them asynchronously.
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
This explains why users have been looking for a reliable way to stream their data from Apache Kafka ® to S3 since Kafka Connect became available. In March 2017, we released the Kafka Connect S3 connector as part of the Confluent Platform. And no one likes missing events. So, it happened. How about we take it for a spin?
deployment on Astro to test DAG versioning, backfills, event-driven scheduling, and more. The blog outlines the challenges of traditional offset management, including inaccuracies stemming from control records and potential issues with stale metadata during leader changes. Spin up a new 3.0
We know that Apache Kafka ® is great when you’re dealing with streams, allowing you to conveniently look at streams as tables. Kafka already allows you to look at data as streams or tables; graphs are a third option, a more natural representation with a lot of grounding in theory for some use cases. 8, and so on. Here we go!
The Kafka Streams API boasts a number of capabilities that make it well suited for maintaining the global state of a distributed system. At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. After experiencing the impacts of fragmented metadata and previous attempts at building a solution Suresh Srinivas and Sriharsha Chintalapani created the OpenMetadata project.
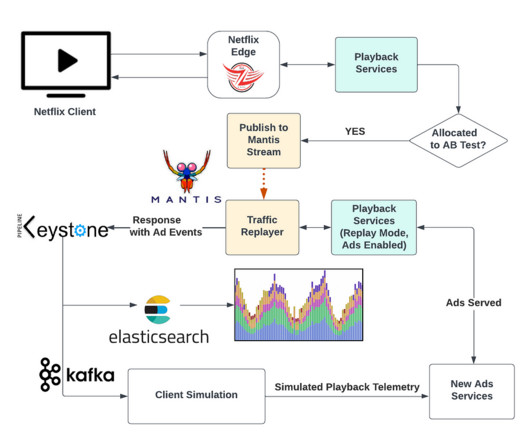
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Back in May 2017, we laid out why we believe that Kafka Streams is better off without a concept of watermarks or triggers , and instead opts for a continuous refinement model. By continuous refinement , I mean that Kafka Streams emits new results whenever records are updated. Use case: Alerting. But how can you build alerts?
With Snowpipe for Apache Kafka (public preview soon in AWS and Microsoft Azure), a “pull” mechanism, rather than the existing “push” connector, allows you to extract and ingest Apache Kafkaevents into your Snowflake account directly without hosting your own Kafka Connect cluster.
DoorDash’s Engineering teams revamped Kafka Topic creation by replacing a Terraform/Atlantis based approach with an in-house API, Infra Service. DoorDash’s Real-Time Streaming Platform, or RTSP, team is under the Data Platform organization and manages over 2,500 Kafka Topics across five clusters.
Instead of having many point-to-point connections between sites, the Confluent Platform provides an integrated event streaming architecture with frictionless data replication between sites. Useful to know in case of a disaster event). How far behind is data replication?
This configuration ensures that if the host goes down due to an EC2® event or any other reason, it will be automatically reprovisioned. Calls the data plane Apache Kafka® Connect API to obtain information about the current state of the system, such as the status of currently running connectors and their configurations.
New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing. It also included metadata about ads, such as ad placement and impression-tracking events. We stored these responses in a Keystone stream with outputs for Kafka and Elasticsearch.
During a recent talk titled Hunters ATT&CKing with the Right Data , which I presented with my brother Jose Luis Rodriguez at ATT&CKcon, we talked about the importance of documenting and modeling security event logs before developing any data analytics while preparing for a threat hunting engagement. FROM SYSMON_JOIN.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Try Astro Free → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. The proposal discusses how Kafka will implement queue functionality similar to SQS and RabbitMQ.
You won't want to miss this live event on April 23rd! A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. Introducing Apache Airflow® 3.0 Be among the first to see Airflow 3.0
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. Introduction. gradlew composeUp.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table. Databricks bought Tabular for $1b.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Includes free forever Confluent Platform on a single Apache Kafka ® broker, improved Control Center functionality at scale and hybrid cloud streaming. the event streaming platform built by the original creators of Apache Kafka. What do we mean by contextual event-driven applications? Confluent Platform 5.2
Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafkametadata and metadata lineage in the Atlas UI. Deep Dive 2: Atlas / Kafka integration. This will expose newly created Kafka topics to Atlas.
Since Kafka is almost synonymous with real-time data processing, we often call this a “Fronting Kafka” pattern. The Fronting Kafka pattern follows a two-cluster approach. Like the staging environment, Fronting Kafka receives all the events without validation. Now, Why is Data Quality Expensive?
This leads us to event streaming microservices patterns. Now that the profile change event is published, it can be received by the quote service. Now that the profile change event is published, it can be received by the quote service. In fact, schemas are more than just a contract between two event streaming microservices.
Giannis is a proud alumnus of Rock the JVM, working as a Solutions Architect with a focus on Event Streaming and Stream Processing Systems. Introduction Apache Kafka is a well-known event streaming platform used in many organizations worldwide. Environment Setup First, we want to have a Kafka Cluster up and running.
Using fixed lookback windows to always reprocess data, assuming that most late-arriving events will occur within that window. Add alerts to flag when late arriving data appears, block the pipelines, and perform a manual intervention where we triggered backfill pipelines to handle the missed events. Some techniques we used were: 1.
Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. So our solution was to start using an intentional contract: Events. What are Events? Events are facts about what happened within your service.
Their SDKs and plugins make event streaming easy, and their integrations with cloud applications like Salesforce and ZenDesk help you go beyond event streaming. What is the current state of the ecosystem for generating and sharing metadata between systems? What are your goals for the OpenLineage effort?
It provides abstractions and tools for the translation of lakehouse table format metadata. Apache Kafka overview — If you're not familiar with Kafka this is a great overview. Stories How Canva collects 25 billion events per day — Protobuf + Amazon Kinesis.
From this release, Streams Messaging templates will support scaling with automatic rebalancing allowing you to grow or shrink your Apache Kafka cluster based on demand. Kafka Scaling. There will now be two specific hostgroups for Kafka Brokers; These are the Core_broker and Broker host groups.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
Flow Collector consumes two data streams, the IP address change events from Sonar via Kafka and eBPF flow log data from the Flow Exporter sidecars. It performs real time attribution of flow data with application metadata from Sonar. Sonar is an IPv6 and IPv4 address identity tracking service.
We are excited to announce the release of Confluent Cloud Schema Registry in general availability (GA), available in Confluent Cloud , our fully managed event streaming service based on Apache Kafka ®. Confluent Schema Registry provides a serving layer for your metadata and a RESTful interface for storing and retrieving Avro schemas.
Introduction Many modern application designs are event-driven. An event-driven architecture enables minimal coupling, which makes it an optimal choice for modern, large-scale distributed systems. Send an event to notify other services about the new order. These services might be responsible for checking the inventory (eg.
Running a single Apache Kafka ® cluster across multiple datacenters (DCs) is a common, yet somewhat taboo architecture. This functionality allows operators to increase data durability and automate client failover in the event of a disaster. Essentially, this is how Apache Kafka provides durability. Follower Fetching.
The Event Driven Decisions capability in particular turned out to be general enough as to be applicable to a wide range of use cases. The interface was designed such that a minimal amount of metadata was needed to construct a pipeline object which performs a given capability. One key component is the Analytics Event Abstraction layer.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
It happens for instance when you have 2 producers of the same event but they are not using the same type for a column. Using server sent events to simplify real-time streaming at scale — Interesting discussion about concepts around real-time communication for apps. in Terraform) but for data.
Photo by Leon S on Unsplash By: Jing Li Summary This article articulates the challenges, innovation and success of the Kafka implementation in Afterpay’s Global Payments Platform in the PCI zone. Context The asynchronous processing capability that Kafka offers opens up numerous innovation opportunities to interact with other services.
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. To serve this need, we created kafka-delta-ingest.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content