This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
For example, a profiler takes a sample every N events (or milliseconds in the case of time profilers) to understand where that event occurs or what is happening at the moment of that event. With a CPU-cycles event, for example, the profile will be CPU time spent in functions or function call stacks executing on the CPU.
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There Then we wait for the actual data and/or final metadata (e.g.
To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized. Even with such strategies, interaction histories from active users can span thousands of events, exceeding the capacity of transformer models with standard self attention layers.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. After experiencing the impacts of fragmented metadata and previous attempts at building a solution Suresh Srinivas and Sriharsha Chintalapani created the OpenMetadata project.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. What are some examples of automated actions that can be triggered from metadata changes? What are the available events that can be used to trigger actions?
Event-first thinking enables us to build a new atomic unit: the event. Four pillars of event streaming. Pillar 4 – Operational plane: Event logging, DLQs and automation. To read the other articles in this series, see: Journey to Event Driven – Part 1: Why Event-First Thinking Changes Everything.
[link] Netflix: Netflix’s Distributed Counter Abstraction Netflix writes about scalable Distributed Counter abstractions for accurately counting events across its global services with millisecond latency. Due to the platform's diverse user base and workloads, Canva faced challenges maintaining visibility into Snowflake usage and costs.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Metadata Overhead: Iceberg relies heavily on metadata to track table changes and enable features like time travel.
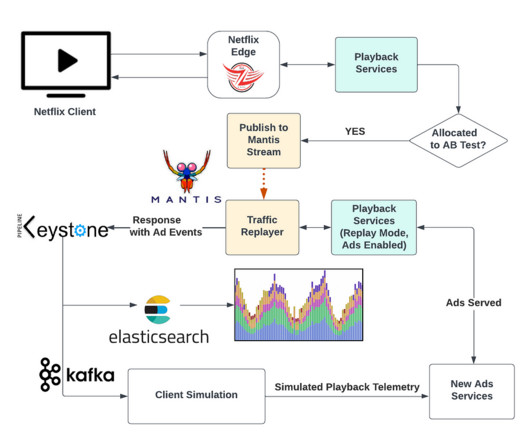
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
This approach is exemplified in the following code snippet: During runtime execution, Privacy Probes does the following: Capturing payloads : It captures source and sink payloads in memory on a sampled basis, along with supplementary metadata such as event timestamps, asset identifiers, and stack traces as evidence for the data flow.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
link] Event Alert: MLOps World/ Gen AI World - Austin, TX - Nov 7-8 The Gen AI Summit, consisting of a wider group of 20,000 Engineers, AI entrepreneurs, and Scientists, will host 1,000 AI teams in Austin, TX, November 7-8. Passes include app-brain-date networking, birds of a feature, post-event parties, etc.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. This is what managing data without metadata feels like. This is what managing data without metadata feels like. Effective metadata management is no longer a luxury—it’s a necessity.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. What are some of the tactical aspects of deciding what interfaces to use for generating interaction events?
Kafka is designed for streaming events, but Fluss is designed for streaming analytics. Analytics on Stream Freshness on Lakehouse When to use Kafka Vs. Fluss Kafka is a general-purpose distributed event streaming platform optimized for high-throughput messaging and event sourcing. How do you compare Fluss with Apache Kafka?
This work illustrates our effort in successfully building Pinterest an internal embedding-based retrieval system for organic content learned purely from logged user engagement events and serves in production. The metadata is generated together with the index. We have deployed our system for homefeed as well as notification.
Using fixed lookback windows to always reprocess data, assuming that most late-arriving events will occur within that window. Add alerts to flag when late arriving data appears, block the pipelines, and perform a manual intervention where we triggered backfill pipelines to handle the missed events. Some techniques we used were: 1.
New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing. It also included metadata about ads, such as ad placement and impression-tracking events. We stored these responses in a Keystone stream with outputs for Kafka and Elasticsearch.
CDC provides real-time or near-real-time movement of data by moving and processing data continuously as new database events occur. Events (deposits and withdrawals) are captured and streamed in real time using change data capture. Striim consumes events from database redo logs.
In every step,we do not just read, transform and write data, we are also doing that with the metadata. As mentioned in the DataKitchen article, it is deployed automatically with code. As mentioned in the DataKitchen article, it is deployed automatically with code. It is not an extra work by reading the database schema or based on your ETL.
To make this migration easier and as seamless as possible, we will give developers the ability to export their deep-link metadata.” Events tech company Hopin selling its events tech business. The ‘startup purge’ event that we predicted at the beginning the year would come seems to, sadly, be here.
Read Time: 2 Minute, 13 Second During the last post we discussed about the Event tables and how these are used for Error logging in your process. The UDTF was responsible of parsing JSON data in a tabular format and identify any erroneous records and log into an Event table. Event tables.
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This enables choreographed service collaborations, where many components can subscribe to events stored in the event log and react to them asynchronously. Let’s imagine a “Hello, World!”
Developing event-driven pipelines is going to be a lot easier - Meet Functions! Memphis Logo]([link] Developing event-driven pipelines is going to be a lot easier - Meet Functions! Developing event-driven pipelines is going to be a lot easier - Meet Functions!
Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. What is the importance of embedding column-level lineage awareness into transformation tool vs. layering on top w/ dedicated lineage/metadata tooling?
This platform has evolved from supporting studio applications to data science applications, machine-learning applications to discover the assets metadata, and build various data facts. During this evolution, quite often we receive requests to update the existing assets metadata or add new metadata for the new features added.
What are the most interesting, unexpected, or challenging lessons that you have learned while working on selecting presentations for this year's event? What do you have planned for the future of this topic at Data Council events? What do you have planned for the future of this topic at Data Council events?
Stateless Data Processing : As the name suggests, one should use this pattern in scenarios where the columns in the target table solely depend on the content of the incoming events, irrespective of their order of occurrence. A missed event in such a scenario would result in incorrect analysis due to a wrong derived state.
At our recent Snowday event, we announced a wave of Snowflake product innovations for easier application development, new AI and LLM capabilities, better cost management and more. If you missed the event or need a refresh of what was presented, watch any Snowday session on demand. Learn more about Iceberg Tables here. Learn more.
Data & Metadata : the data of the data product in many possible storages if needed but also the metadata (data on data) Infrastructure : you will need compute & storage but with the Serverless philisophy, we want to make it totally transparent and stay focus on the first two dimensions. What you have to code is this workflow !
Metadata Caching. This is used to provide very low latency access to table metadata and file locations in order to avoid making expensive remote RPCs to services like the Hive Metastore (HMS) or the HDFS Name Node, which can be busy with JVM garbage collection or handling requests for other high latency batch workloads.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
Linked data technologies provide a means of tightly coupling metadata with raw information. what are the characteristics that distinguish a knowledge graph from What are the layers/stages of applications and data that can/should incorporate JSON-LD as the representation for records and events?
If you've always wanted to learn how to use event binding in Angular, you've come to the right place. This article will discuss Angular's event binding and how to apply it to our Angular project. Events are triggered after these actions are completed. How Does Event Binding Works in Angular ?
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA.
You won't want to miss this live event on April 23rd! A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. Introducing Apache Airflow® 3.0 Be among the first to see Airflow 3.0
When functions are “pure” — meaning they do not have side-effects — they can be written, tested, reasoned-about and debugged in isolation, without the need to understand external context or history of events surrounding its execution. Knowing when events were reported in relation to when they occurred is useful.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Join in with the event for the global data community, Data Council Austin. Don't miss out on their only event this year! Data Council Logo]([link] Join us at the event for the global data community, Data Council Austin.
Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
Here are a couple of the biggest takeaways we had from our time at the event. In those discussions, it was clear that everyone understood the need to treat data estates more cohesively as a whole—that means bringing more attention to security, data governance, and metadata management, the latter of which has become increasingly popular.
RudderStack Transformations lets you customize your event data in real-time with your own JavaScript or Python code. Join in with the event for the global data community, Data Council Austin. Don't miss out on their only event this year! Don't miss out on our only event this year!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content