This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Benchmarking: for new server types identified – or ones that need an updated benchmark executed to avoid data becoming stale – those instances have a benchmark started on them. Results are stored in git and their database, together with benchmarking metadata. Then we wait for the actual data and/or final metadata (e.g.
Profilers operate by sampling data to perform statistical analysis. For example, a profiler takes a sample every N events (or milliseconds in the case of time profilers) to understand where that event occurs or what is happening at the moment of that event. Did someone say Metadata? Function call count profilers.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Types of late-arriving data Based on the structure of our upstream systems, we’ve classified late-arriving data into two categories, each named after the timestamps of the updated partition: Ways to process such data Our team previously employed some strategies to manage these scenarios, which often led to unnecessarily reprocessing unchanged data.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming rawdata into valuable insights. This is what managing data without metadata feels like.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
When functions are “pure” — meaning they do not have side-effects — they can be written, tested, reasoned-about and debugged in isolation, without the need to understand external context or history of events surrounding its execution. This allows for landing immutable blocks of data without delays, in a predictable fashion.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. Why Use AWS Glue?
In truth, the synergy between batch and streaming pipelines is essential for tackling the diverse challenges posed to your data platform at scale. The key to seamlessly addressing these challenges lies, unsurprisingly, in data orchestration. This metadata is then utilized to manage, monitor, and foster the growth of the platform.
Let’s break down each of the seven data quality dimensions with examples to understand how they contribute to reliable data. What are the 7 Data Quality Dimensions? Data teams can use uniqueness tests to measure their data uniqueness.
As we mentioned in our previous blog , we began with a ‘Bring Your Own SQL’ method, in which data scientists checked in ad-hoc Snowflake (our primary data warehouse) SQL files to create metrics for experiments, and metrics metadata was provided as JSON configs for each experiment.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
As organizations seek to leverage data more effectively, the focus has shifted from temporary datasets to well-defined, reusable data assets. Data products transform rawdata into actionable insights, integrating metadata and business logic to meet specific needs and drive strategic decision-making.
This could just as easily have been Snowflake or Redshift, but I chose BigQuery because one of my data sources is already there as a public dataset. dbt seeds data from offline sources and performs necessary transformations on data after it's been loaded into BigQuery. Let's dig into each data source one at a time.
The “head” tags (<head> and </head>) contain the metadata or information about the website. Not all of the metadata is visible on the website, some of them are information for the browsers. SSG is a tool that generates HTML websites using a set of templates and rawdata.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance. Architecture overview. Separate storage.
As smart as ChatGPT appears to be, it can’t summarize current events accurately if it was last trained a year ago and not told what’s happening now. Models may need to know about events, computed metrics, and embeddings based on locality.
Data Service – is a group of Data Flows. At this level, users configure team members, connections to other systems, and event notifications. Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products.
Data Service – is a group of Data Flows. At this level, users configure team members, connections to other systems, and event notifications. Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products.
When the business intelligence needs change, they can go query the rawdata again. ELT: source Data Lake vs Data Warehouse Data lake stores rawdata. The purpose of the data is not determined. The data is easily accessible and is easy to update. x+ and set minimum memory to 5GB.
July brings summer vacations, holiday gatherings, and for the first time in two years, the return of the Massachusetts Institute of Technology (MIT) Chief Data Officer symposium as an in-person event. A key area of focus for the symposium this year was the design and deployment of modern data platforms.
The current landscape of Data Observability Tools shows a marked focus on “Data in Place,” leaving a significant gap in the “Data in Use.” ” When monitoring rawdata, these tools often excel, offering complete standard data checks that automate much of the data validation process.
ETL Architecture on AWS: Examining the Scalable Architecture for Data Transformation ETL Architecture on AWS typically consists of three components - Source Data Store A Data Transformation Layer Target Data Store Source Data Store The source data store is where rawdata is stored before being transformed and loaded into the target data store.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Watch our video explaining how data engineering works.
Moreover, over 20 percent of surveyed companies were found to be utilizing 1,000 or more data sources to provide data to analytics systems. These sources commonly include databases, SaaS products, and event streams. Databases store key information that powers a company’s product, such as user data and product data.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The names hold less meaning to the outcome, but its fancy. link] All rights reserved ProtoGrowth Inc, India.
Virtual Reality – The Next Frontier in Media I work as a Data Engineer at a leading company in the VR space, with a mission to capture and transmit reality in perfect fidelity. Our content varies from on-demand experiences to live events like NBA games, comedy shows and music concerts.
When a metric is defined in Minerva, authors are required to provide important self-describing metadata. Prior to Minerva, all such metadata often existed only as undocumented institutional knowledge or in chart definitions scattered across various business intelligence tools.
Data integration layer holds any transformations required to make the data digestible for end users. This often involves such operations as data harmonization, mastering, and enrichment with metadata. Storage layer corresponds to the needs of database management and data modeling. Stambia data hub.
Companies are drowning in a sea of rawdata. As data volumes explode across enterprises, the struggle to manage, integrate, and analyze it is getting real. Thankfully, with serverless data integration solutions like Azure Data Factory (ADF), data engineers can easily orchestrate, integrate, transform, and deliver data at scale.
Data processing : Whatnot data teams rely on Snowflake and dbt for processing, with orchestration in Dagster. “All It’s quite dynamic, and analytics events that represent ephemeral things happening in real time are incredibly valuable for us. Data quality challenges at Whatnot And you know what they say: mo’ data, mo’ problems.
For example, Online Analytical Processing (OLAP) systems only allow relational data structures so the data has to be reshaped into the SQL-readable format beforehand. In ELT, rawdata is loaded into the destination, and then it receives transformations when it’s needed. ELT allows them to work with the data directly.
Aside from video data from each camera-equipped store, Standard deals with other data sets such as transactional data, store inventory data that arrive in different formats from different retailers, and metadata derived from the extensive video captured by their cameras.
Data lakes offer a flexible and cost-effective approach for managing and storing unstructured data, ensuring high durability and availability. Another NLP approach for handling unstructured text data is information extraction (IE). Last but not least, you may need to leverage data labeling if you train models for custom tasks.
As it serves the request, the web server writes a line to a log file on the filesystem that contains some metadata about the client and the request. We store the raw log data to a database. This ensures that if we ever want to run a different analysis, we have access to all of the rawdata. PingdomPageSpeed/1.0
The Windward Maritime AI platform Lastly, Windward wanted to move their entire platform from batch-based data infrastructure to streaming. This transition can support new use cases that require a faster way to analyze events that was not needed until now. They used MongoDB as their metadata store to capture vessel and company data.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. Data pipeline orchestration is characterized by a detailed understanding of pipeline events and processes. Not every team needs data orchestration.
The data warehouse layer consists of the relational database management system (RDBMS) that contains the cleaned data and the metadata, which is data about the data. The RDBMS can either be directly accessed from the data warehouse layer or stored in data marts designed for specific enterprise departments.
If any unplanned event triggers, which results in the machine crashing, then the Hadoop cluster would not be available unless the Hadoop Administrator restarts the NameNode. We also use Hadoop and Scribefor log collection, bringing in more than 50TB of rawdata per day. What is high availability in Hadoop? With Hadoop 2.0,
The `dbt run` command will compile and execute your models, thus transforming your rawdata into analysis-ready tables. Once the models are created and data transformed, `dbt test` should be executed. This command runs all tests defined in your dbt project against the transformed data. Curious to learn more?
Airbyte – An open source platform that easily allows you to sync data from applications. Data streaming ingestion solutions include: Apache Kafka – Confluent is the vendor that supports Kafka, the open source event streaming platform to handle streaming analytics and data ingestion.
Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. Data that can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi-structured data.
Provides Powerful Computing Resources for Data Processing Before inputting data into advanced machine learning models and deep learning tools, data scientists require sufficient computing resources to analyze and prepare it. They just need to deliver their data and hand it over to Snowflake to manage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































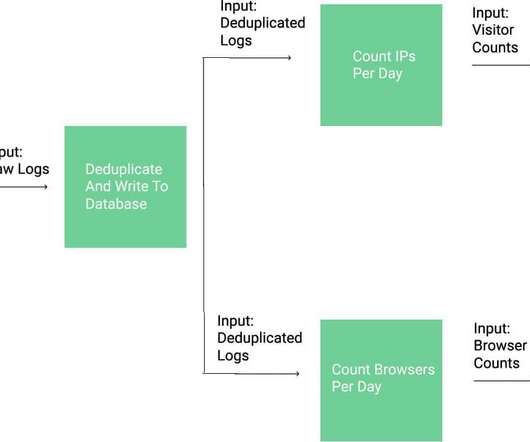















Let's personalize your content