This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. And who better to learn from than the tech giants who process more data before breakfast than most companies see in a year?
Turns out, stream processing also has its skew but more related to time. As a data engineer you're certainly familiar with data skew. Yes, this bad phenomena where one task takes considerably more input than the others and often causes unexpected latency or failures.
One of the most impactful, yet underdiscussed, areas is the potential of autonomous finance, where systems not only automate payments but manage accounts and financial processes with minimal human intervention.
At Zalando, our event-driven architecture for Price and Stock updates became a bottleneck, introducing delays and scaling challenges. Once complete, each product was materialised as an event, requiring teams to consume the event stream to serve product data via their own APIs. Where do I get it?"had
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. This process can also be used to track the provenance of increments.
Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. Check out the agenda and register today at Neo4j.com/NODES.
Data and process automation used to be seen as luxury but those days are gone. Lets explore the top challenges to data and process automation adoption in more detail. Almost half of respondents (47%) reported a medium level of automation adoption, meaning they currently have a mix of automated and manual SAP processes.
Strobelight is also not a single profiler but an orchestrator of many different profilers (even ad-hoc ones) that runs on all production hosts at Meta, collecting detailed information about CPU usage, memory allocations, and other performance metrics from running processes. Event-based profilers for both native and non-native languages (e.g.,
How to Stream and Apply Real-Time Prediction Models on High-Throughput Time-Series Data Photo by JJ Ying on Unsplash Most of the stream processing libraries are not python friendly while the majority of machine learning and data mining libraries are python based. An event is generated by a producer (e.g. online dashboard).
What is Real-Time Stream Processing? To access real-time data, organizations are turning to stream processing. To access real-time data, organizations are turning to stream processing. There are two main data processing paradigms: batch processing and stream processing.
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
Balancing correctness, latency, and cost in unbounded data processing Image created by the author. Intro Google Dataflow is a fully managed data processing service that provides serverless unified stream and batch data processing. It is the first choice Google would recommend when dealing with a stream processing workload.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
These industry-specific virtual events are ideal for IT professionals and business leaders who want to bridge the gap between perception and reality, build robust data foundations and accelerate their AI initiatives. The events will also feature demos of key use cases and best practices. Why attend Accelerate Retail and Consumer Goods?
Processing some 90,000 tables per day, the team oversees the ingestion of more than 100 terabytes of data from upward of 8,500 events daily. With Snowpark, Nexon found processing speeds to be equally fast but more convenient and cost-effective since data never has to move off of Snowflake.
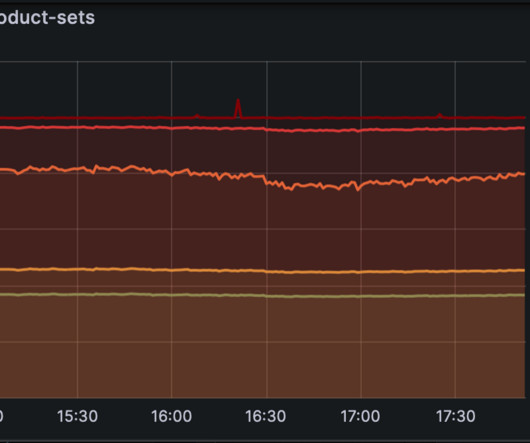
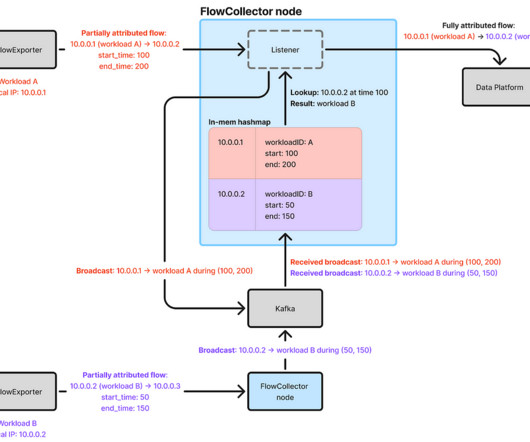
FlowCollector , a backend service, collects flow logs from FlowExporter instances across the fleet, attributes the IP addresses, and sends these attributed flows to Netflixs Data Mesh for subsequent stream and batch processing. Additionally, event timestamps may be inaccurate depending on how they are captured.
and Executive Chairman of LandingAI, Andrew Ng, has long been a leading proponent of AI agents and agentic workflows — the iterative processes of multiple AI agents collaborating to solve problems and ultimately carry out complex tasks automatically. Go in-depth on some of Snowflake’s most popular features, like Document AI.
” And an update inside the final hour and a half of the outage: “2:00 PM PDT Many AWS services are now fully recovered and marked Resolved on this event. Lambda is working to process these messages during the next few hours and during this time, we expect to see continued delays in the execution of asynchronous invocations.
I asked Googlers the reason why these events have been canceled and one thing became clear: most of the program managers who worked on the coding competitions were recently let go in Google’s historic job cuts. In the beginning of February, Google announced the delays in the registration process.
Glassdoor could make the process a lot clearer by publishing a moderation log which details when and why it removed a review. Organize a “Glassdoor review event,” asking employees to leave honest reviews. This log could contain only the redacted parts of affected reviews to ensure the terms of service are not broken.
One of the major benefits of AI tools will be increased efficiency throughout the process of getting messages to consumers. This is where AI can really make a difference in optimizing the process and improving ROI for marketers. AI will clearly benefit advertisers by giving them more bang for their budget.
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used. Hack, C++, Python, etc.)
Enter Amazon EventBridge, a fully managed serverless event bus service that makes it easier to build event-driven applications using data from your AWS services, custom applications, or SaaS providers. It is a fully managed, serverless event bus service that allows applications to communicate with each other using events.
Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns. Internal comms: Chat: Slack Coordination / project management: Linear 3.
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. The learning mostly involves understanding the data's nature, frequency of data processing, and awareness of the computing cost.
Ready Flows: Accelerate development with pre-built templates for common data integration and processing tasks, freeing up developers to focus on higher-value activities. Boosting Developer Productivity DataFlow 2.9 This reduces development time and enhances consistency. By simplifying development and promoting reusability, DataFlow 2.9
Snowflake partner Accenture, for example, demonstrated how insurance claims professionals can leverage AI to process unstructured data including government IDs and reports to make document gathering, data validation, claims validation and claims letter generation more streamlined and efficient.
KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts. The app was pretrained using enormous quantities of security logs and is particularly focused on the pattern of events, including relative and absolute time.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. In the event of these different cluster errors, what are the strategies for mitigating and recovering from those failures? Operating it at scale, however, is notoriously challenging.
Avoiding downtime was nerve-wracking, and the notion of a 'rollback' was as much a relief as a technical process. After this zero-byte file was deployed to prod, the Apache web server processes slowly picked up the empty configuration file. Our deployments were initially manual. Apache started to log like a maniac.
Fluss is a compelling new project in the realm of real-time data processing. Kafka is designed for streaming events, but Fluss is designed for streaming analytics. It excels in event-driven architectures and data pipelines. It works with streaming processing like Flink and Lakehouse formats like Iceberg and Paimon.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. Serving a web page.
Venture funding is on a downward trend , and we seem to be at the start – or the middle – of a “startup purge” event. This news is hot off the press, publicly announced by Postman and by Akita yesterday, and you are among the early ones to hear about this event. On hiring Every startup hires differently.
Proponents of the streaming paradigm argue that stream processing engines can easily handle batched workloads, but the reverse isn't true. Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools.
There were many Gartner keynotes and analyst-led sessions that had titles like: Scale Data and Analytics on Your AI Journeys” What Everyone in D&A Needs to Know About (Generative) AI: The Foundations AI Governance: Design an Effective AI Governance Operating Model The advice offered during the event was relevant, valuable, and actionable.
Many real-world datasets consist of records of events that occur at arbitrary and irregular intervals. These datasets then need to be processed into regular time series for further analysis. We will use the AI & Analytics Engine to illustrate how you can prepare your time-series data in just 1 step.
Postgres Logical Replication at Zalando Builders at Zalando have access to a low-code solution that allows them to declare event streams that source from Postgres databases. At the time of writing, there are hundreds of these Postgres-sourced event streams out in the wild at Zalando. Simple, right?
link] Event Alert: MLOps World/ Gen AI World - Austin, TX - Nov 7-8 The Gen AI Summit, consisting of a wider group of 20,000 Engineers, AI entrepreneurs, and Scientists, will host 1,000 AI teams in Austin, TX, November 7-8. Passes include app-brain-date networking, birds of a feature, post-event parties, etc.
Discovering and surfacing telemetry traditionally can be a tedious and challenging process, especially when it comes to pinpointing specific issues for debugging. A default Event Table (public preview soon) is in the Snowflake database of every account, removing the need to create and manage your own custom event table.
Introduction Stateful stream processing refers to processing a continuous stream of events in real-time while maintaining state based on the events seen so far.
Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. When there is no internal data talent to assist with hiring, what are some of the problems that manifest in the hiring process?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content