This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Results are stored in git and their database, together with benchmarking metadata. 4 cloud providers across 100+ regions end up with more than 100,000 different server prices. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There
CDP Public Cloud is now available on GoogleCloud. The addition of support for GoogleCloud enables Cloudera to deliver on its promise to offer its enterprise data platform at a global scale. CDP Public Cloud is already available on Amazon Web Services and Microsoft Azure. Virtual Machines . Attached Disks.
It will be illustrated with our technical choices and the services we are using in the GoogleCloud Platform. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services.
Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. Hence, the metadata files record schema and partition changes, enabling systems to process data with the correct schema and partition structure for each relevant historical dataset.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
[link] Allegro Tech: A Mission to Cost-Effectiveness: Reducing the cost of a single GoogleCloud Dataflow Pipeline by Over 60% The blog is an excellent case study of hyopoesis driven cost optimization with the detail analysis to verify the hypothesis. Physical resources are underutilized.
What are some of the data modeling considerations that need to be considered when pushing metadata to Sifflet? runs natively on data lakes and warehouses and in AWS, GoogleCloud and Microsoft Azure. What are some of the data modeling considerations that need to be considered when pushing metadata to Sifflet?
How we deployed a simple wildlife monitoring system on GoogleCloud — Artefact engineering a serverless platform on GCP to do wildlife monitoring. Select Star is another data catalog that automatically connects to your tools and provides the usual data catalog UI based on a search bar with metadata management inside.
Databricks and Snowflake are better places to index the data and its metadata to enable natural language query capabilities. The question remains how far the data catalog tools can go with just the metadata. I exclude GoogleCloud since I rarely see GoogleCloud users using either Snowflake or Databricks.
Let’s assume the task is to copy data from a BigQuery dataset called bronze to another dataset called silver within a GoogleCloud Platform project called project_x. Load data For data ingestion GoogleCloud Storage is a pragmatic way to solve the task. Data can easily be uploaded and stored for low costs.
With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. .
It’s running on Googlecloud services on a Debian linux. What pieces of metadata do you track for a given data set? It’s running on Googlecloud services on a Debian linux. What pieces of metadata do you track for a given data set?
Originally created by GoogleCloud in 2014, Kubernetes is now being offered by leading Cloud Providers like AWS and Azure. apiVersion: v1 kind: Pod metadata: name: Postgres spec: containers: - name: Postgres image: Postgres: 3.1 Here is a sample YAML file used to create a pod with the postgres database.
Datadog easily connects with popular cloud service providers such as Amazon Web Services (AWS), Microsoft Azure, GoogleCloud Platform (GCP), and more. This means you can quickly start monitoring and managing your cloud infrastructure, applications, and services without hassle, regardless of which cloud provider you use.
We recently completed a project with IMAX, where we learned that they had developed a way to simplify and optimize the process of integrating GoogleCloud Storage (GCS) with Bazel. rules_gcs is a Bazel ruleset that facilitates the downloading of files from GoogleCloud Storage. What is rules_gcs ?
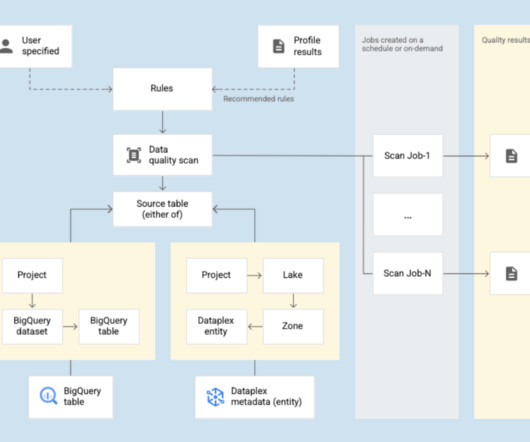
Dataplex works with your metadata. As you add new data sources to your data stores, Dataplex leverages the structured and unstructured metadata with built-in data quality checks to maintain integrity. Courtesy of GoogleCloud. Courtesy of GoogleCloud. Our promise: we will show you the product.
However, one of the biggest trends in data lake technologies, and a capability to evaluate carefully, is the addition of more structured metadata creating “lakehouse” architecture. If not paired with Glue, or another metastore/catalog solution, S3 will also lack some of the metadata structure required for more advanced data management tasks.
Recently, we announced the general availability of DataFlow Functions , allowing NiFi flows to be executed in serverless compute environments, such as AWS Lambda, Azure Functions, or GoogleCloud Functions. . With NiFi you can configure your source processor and run it independently of any other processors to retrieve data.
This means you now have access, without any time constraints, to tools such as Control Center, Replicator, security plugins for LDAP and connectors for systems, such as IBM MQ, Apache Cassandra and GoogleCloud Storage. Output metadata. Some of the changes include: Feed pause and resume. Card and table formats.
The Unity Catalog is Databricks governance solution which integrates with Databricks workspaces and provides a centralized platform for managing metadata, data access, and security. It acts as a sophisticated metastore that not only organizes metadata but also enforces security and governance policies across various data assets and AI models.
Printing it loses all this metadata. Several engineers are tasked with investigating which systems can be scaled back or turned off completely, to reduce cloud operations costs. Reviewing code is done on the computer because it’s more efficient, because you can jump between revisions, see who made which change, and so on.
Attributes contain key metadata like the source directory of a file or the source topic of a Kafka message. Figure 6: While listing the content of a queue, you can pin attributes for easy access The ability to view metadata and pin attributes is very useful to find the right events that you want to explore further.
Interoperability through community Just as large communities have grown in support of open source projects for open file and table formats, there is a community emerging to collaborate on standards for metadata catalogs. Diversity of ideas and community contributions creates the most interoperable catalog across the widest variety of tools.
Rostratter joins Ascend from Google, where she led various sales and vendor teams for GoogleCloud to better serve Small and Medium Businesses across Europe , Middle East, and Africa. Prior to Google, she worked as an investment researcher for S&P Global Market Intelligence and GLG. SAN FRANCISCO , Feb.
Rostratter joins Ascend from Google, where she led various sales and vendor teams for GoogleCloud to better serve Small and Medium Businesses across Europe , Middle East, and Africa. Prior to Google, she worked as an investment researcher for S&P Global Market Intelligence and GLG. SAN FRANCISCO , Feb.
By design, data was less structured with limited metadata and no ACID properties. With this new release, Monte Carlo now supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and GoogleCloud.
The “head” tags (<head> and </head>) contain the metadata or information about the website. Not all of the metadata is visible on the website, some of them are information for the browsers. Cloud Providers like Amazon Web Services, GoogleCloud Platform, Microsoft Azure also provide hosting services.
In this article, we want to illustrate our extensive use of the public cloud, specifically GoogleCloud Platform (GCP). As an example, in one of our first BigQuery aggregations, we had a large query that joined statistics data with metadata, then aggregated over it. Booking Holdings, as a whole, spent $4.7
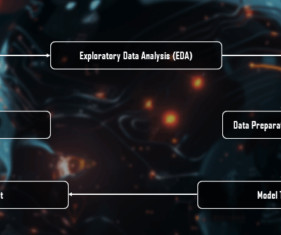
Step 4) Model Deployment Study how to deploy machine learning models on cloud platforms like AWS, GoogleCloud Platform (GCP), or Microsoft Azure. Step 6) Metadata Management Understand the importance of metadata (data about data) and how to manage it effectively.
As the only data observability platform to provide full visibility into delta tables With our delta lake integration, Monte Carlo supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and GoogleCloud.
Disadvantages of a data lake are: Can easily become a data swamp data has no versioning Same data with incompatible schemas is a problem without versioning Has no metadata associated It is difficult to join the data Data warehouse stores processed data, mostly structured data. The data is easily accessible and is easy to update.
It handles the metadata related to these objects, access control configurations, and query optimization statistics. The external stage area includes Microsoft Azure Blob storage, Amazon AWS S3, and GoogleCloud Storage. Cloud Storage Snowflake leverages the cloud’s native object storage services (e.g.
You can think of a cookbook as a collection of all the recipes, files, characteristics, and metadata you'll need to implement a specific scenario. Metadata A small bit of metadata is required for every cookbook. Cookbooks In Chef Infra, a Cookbook is the basic unit of configuration and policy distribution.
It houses metadata and both the desired and current state for each resource. So, if any other component needs to access information about the metadata or state of resources stored in the etcd, they have to go through the kube-apiserver. This ensures that all of the configurations are set correctly before being stored in the etcd.
Prerequisites Set up a BigQuery project and service account This exercise requires familiarity with dbt and Google BigQuery. Most importantly, you will need to know: the file path of your GoogleCloud service account’s JSON key the name of your GoogleCloud project If that doesn’t mean anything to you, never fear!
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, GoogleCloud Storage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. Databricks lakehouse platform architecture.
File Systems: Data from several file systems, including FTP, SFTP, HDFS, and different cloud storages such as Amazon S3, Googlecloud storage, etc., Preserve Metadata Along with Data When copying data, you can also choose to preserve metadata such as column names, data types, and file properties.
The Data Engineering Weekly even published a special Metadata Edition focusing on the historical development of the Data Catalog. link] It is almost two years since we published the metadata edition, but I keep thinking back. link] Prabhuk Karthi STB: 10 Key Takeaways From GoogleCloud Next22 Bye Bye Google Studio!!
A warehouse can be a one-stop solution, where metadata, storage, and compute components come from the same place and are under the orchestration of a single vendor. Some of the well-known players in the data warehouse sphere include Amazon Redshift, Google BigQuery, and Snowflake.
Spotify builds the vector embeddings with the query text being the input embedding and a concatenation of textual metadata fields including title and description for the podcast episode embeddings. One of the reasons that Vespa was chosen is that it can also incorporate metadata filtering post-search on features like episode popularity.
v1 Kind: StorageClass metadata: Name: standard provisioner: kubernetes.io/aws-ebs aws-ebs parameters: type: gp3 reclaimPolicy: Retain allowVolumeExpansion: true mount0ptions: debug volumeBindingMode: Immediate The StorageClass object's name is crucial since it permits requests to that specific class. Example: a.
Hortonworks and Cloudera both depend on HDFS and go with the DataNode and NameNode architecture for splitting up where the data processing is done and metadata is saved. Leading companies like Cisco, Ancestry.com, Boeing, GoogleCloud Platform and Amazon EMR use MapR Hadoop Distribution for their Hadoop services.
OpenLineage collects data lineage and performance metadata as models run, so I can identify issues and find bottlenecks. I decided that this situation called for a small slice of PyPI: a table that only contains rows for the packages I am studying, one that I can point a greedy dashboarding tool at without blowing up my GoogleCloud bill.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content