This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, this ability to remotely run client applications written in any supported language (Scala, Python) appeared only in Spark 3.4. The appropriate Spark dependencies (spark-core/spark-sql or spark-connect-client-jvm) will be provided later in the Java classpath, depending on the run mode. classOf[SparkSession.Builder].getDeclaredMethod("remote",
Hadoop and Spark are the two most popular platforms for Big Data processing. To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? scalability.
If you search top and highly effective programming languages for Big Data on Google, you will find the following top 4 programming languages: JavaScala Python R JavaJava is one of the oldest languages of all 4 programming languages listed here. Java is portable due to something called Java Virtual Machine – JVM.
MapReduce is written in Java and the APIs are a bit complex to code for new programmers, so there is a steep learning curve involved. Also, there is no interactive mode available in MapReduce Spark has APIs in Scala, Java, Python, and R for all basic transformations and actions. It can also run on YARN or Mesos.
The term Scala originated from “Scalable language” and it means that Scala grows with you. In recent times, Scala has attracted developers because it has enabled them to deliver things faster with fewer codes. Developers are now much more interested in having Scala training to excel in the big data field.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. For the package type, choose ‘Pre-built for Apache Hadoop’ The page will look like the one below. Step 6: Spark needs a piece of Hadoop to run. For Hadoop 2.7, exe file 3.
Good old data warehouses like Oracle were engine + storage, then Hadoop arrived and was almost the same you had an engine (MapReduce, Pig, Hive, Spark) and HDFS, everything in the same cluster, with data co-location. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with 3) Spark 4.0
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
Enter the new Event Tables feature, which helps developers and data engineers easily instrument their code to capture and analyze logs and traces for all languages: Java, Scala, JavaScript, Python and Snowflake Scripting. But previously, developers didn’t have a centralized, straightforward way to capture application logs and traces.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development. Yarn etc) Or, 2.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Contact Info LinkedIn @fhueske on Twitter fhueske on GitHub Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
The interesting world of big data and its effect on wage patterns, particularly in the field of Hadoop development, will be covered in this guide. As the need for knowledgeable Hadoop engineers increases, so does the debate about salaries. You can opt for Big Data training online to learn about Hadoop and big data.
The role requires extensive knowledge of data science languages like Python or R and tools like Hadoop, Spark, or SAS. ScalaScala has become one of the most popular languages for AI and data science use cases. As a result, Java is the best coding language for data science. How Is Programming Used in Data Science?
If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. There are a variety of big data processing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Apache Hadoop and Apache Spark fulfill this need as is quite evident from the various projects that these two frameworks are getting better at faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Table of Contents Why Apache Hadoop?
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Big Data has found a comfortable home inside the Hadoop ecosystem. Hadoop based data stores have gained wide acceptance around the world by developers, programmers, data scientists, and database experts. They were required to learn a new querying language all over again to effectively utilize the benefits provided by Hadoop.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. Prerequisites This guide assumes that you are using Ubuntu and that Hadoop 2.7 Hadoop should be installed on your Machine. The below command should show the java version. Minimum of 8 GB RAM.
Confused over which framework to choose for big data processing - Hadoop MapReduce vs. Apache Spark. Hadoop and Spark are popular apache projects in the big data ecosystem. Apache Spark is an improvement on the original Hadoop MapReduce component of the Hadoop big data ecosystem.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. They achieve this through a programming language such as Java or C++. It is considered the most commonly used and most efficient coding language for a Data engineer and Java, Perl, or C/ C++.
With that in mind, it’s not uncommon for a company to grow their own data scientists from adjacent expertises: analysts, database experts, people with coding experience in Java or C/C++ are often trained in algorithms and models to become data scientists. Let’s give a rundown of the necessary skills and what they entail. Statistics and maths.
I program in Python, Scala, and Java as I toggle between analyzing data, running machine learning experiments, and evaluating business impact. Using big data technologies like Spark and Hadoop, I sampled different data to feed our algorithms, which turned into business metric gains that I also learned to interpret.
This blog post gives an overview on the big data analytics job market growth in India which will help the readers understand the current trends in big data and hadoop jobs and the big salaries companies are willing to shell out to hire expert Hadoop developers. It’s raining jobs for Hadoop skills in India.
Scott Gnau, CTO of Hadoop distribution vendor Hortonworks said - "It doesn't matter who you are — cluster operator, security administrator, data analyst — everyone wants Hadoop and related big data technologies to be straightforward. That’s how Hadoop will make a delicious enterprise main course for a business.
The role requires extensive knowledge of data science languages like Python or R and tools like Hadoop, Spark, or SAS. ScalaScala has become one of the most popular languages for AI and data science use cases. As a result, Java is the best coding language for data science. How Is Programming Used in Data Science?
Python, Java, and Scala knowledge are essential for Apache Spark developers. Various high-level programming languages, including Python, Java , R, and Scala, can be used with Spark, so you must be proficient with at least one or two of them. Creating Spark/Scala jobs to aggregate and transform data.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. In former times, Kafka worked with Java only. The hybrid data platform supports numerous Big Data frameworks including Hadoop and Spark , Flink, Flume, Kafka, and many others. Kafka vs Hadoop.
Hadoop This open-source batch-processing framework can be used for the distributed storage and processing of big data sets. Hadoop relies on computer clusters and modules that have been designed with the assumption that hardware will inevitably fail, and the framework should automatically handle those failures.
For the majority of Spark’s existence, the typical deployment model has been within the context of Hadoop clusters with YARN running on VM or physical servers. DE supports Scala, Java, and Python jobs. Let’s take a technical look at what’s included. A Technical Look at CDP Data Engineering. Managed, Serverless Spark.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Hadoop YARN : Often the preferred choice due to its scalability and seamless integration with Hadoop’s data storage systems, ideal for larger, distributed workloads.
Even though Spark is written in Scala, you can interact with Spark with multiple languages like Spark, Python, and Java. Getting started with Apache Spark You’ll need to ensure you have Apache Spark, Scala, and the latest Java version installed. In my case, I needed aws-java-sdk-bundle 1.11.375 for Apache Spark 3.2.0.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
The datasets are usually present in Hadoop Distributed File Systems and other databases integrated with the platform. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data. HQL or HiveQL is the query language in use with Apache Hive to perform querying and analytics activities.
Python R SQL Java Julia Scala C/C++ JavaScript Swift Go MATLAB SAS Data Manipulation and Analysis: Develop skills in data wrangling, data cleaning, and data preprocessing. Big Data Technologies: Familiarize yourself with distributed computing frameworks like Apache Hadoop and Apache Spark. Who can Become Data Scientist?
JavaJava, a general-purpose language, has found a niche in big data analytics. Libraries like Hadoop and Apache Flink, written in Java, are extensively used for data processing in distributed computing environments. Scala offers speed and scalability, making it suitable for large scale data processing tasks.
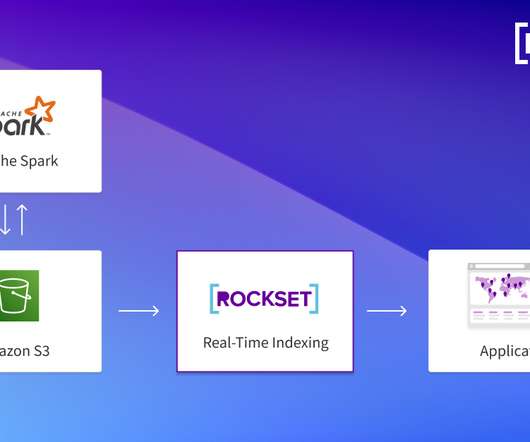
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google Cloud Storage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. The open source platform works with Java , Python, and R.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. Java can be used to build APIs and move them to destinations in the appropriate logistics of data landscapes.
Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential. show() So How Much Python Is Required for a Data Engineer?
Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content