This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this constantly growing technical era, big data is at its peak, with the need for a tool to import and export the data between RDBMS and Hadoop. Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.)
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
Striim offers an out-of-the-box adapter for Snowflake to stream real-time data from enterprise databases (using low-impact change data capture ), log files from security devices and other systems, IoT sensors and devices, messaging systems, and Hadoop solutions, and provide in-flight transformation capabilities.
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. then you are on the right page.
Planetscale is a serverless option for your MySQL workloads that lets you focus on your applications without having to worry about managing the database or fight with differences between development and production. Can you describe what Planetscale is and the story behind it?
Good old data warehouses like Oracle were engine + storage, then Hadoop arrived and was almost the same you had an engine (MapReduce, Pig, Hive, Spark) and HDFS, everything in the same cluster, with data co-location. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
Apache Hadoop and Apache Spark fulfill this need as is quite evident from the various projects that these two frameworks are getting better at faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Table of Contents Why Apache Hadoop?
For the MySQL/Postgres replication functionality how do you maintain schema evolution from the source DB to Clickhouse? For the MySQL/Postgres replication functionality how do you maintain schema evolution from the source DB to Clickhouse? Can you talk through how that factors into different use cases for Clickhouse?
Book Discount Use the code poddataeng18 to get 40% off of all of Manning’s products at manning.com Links Apache Spark Spark In Action Book code examples in GitHub Informix International Informix Users Group MySQL Microsoft SQL Server ETL (Extract, Transform, Load) Spark SQL and Spark In Action ‘s chapter 11 Spark ML and Spark In Action (..)
Bank of America has tapped into Hadoop technology to manage and analyse the large amounts of customer and transaction data that it generates. Big Data analytics and Hadoop are the heart of ‘BankAmeriDeals’ program, that provides cashback offers to bank’s credit and debit card holders. signing bonus, $68.9K
Almost all relational databases provide a JDBC driver, including Oracle, Microsoft SQL Server, DB2, MySQL and Postgres. The example that I’ll work through here is pulling in data from a MySQL database. For example: CLASSPATH=/u01/jdbc-drivers/mysql-connector-java-8.0.13.jar./bin/connect-distributed./etc/kafka/connect-distributed.properties.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Email hosts@dataengineeringpodcast.com ) with your story. Email hosts@dataengineeringpodcast.com ) with your story.
The toughest challenges in business intelligence today can be addressed by Hadoop through multi-structured data and advanced big data analytics. Big data technologies like Hadoop have become a complement to various conventional BI products and services. Big data, multi-structured data, and advanced analytics.
The data needed to compute our metrics came from various sources including MySQL databases, Kafka topics and Hadoop (HDFS). Data Flow We compute and load the full set of metrics from HDFS to a MySQL database every day and use a Gunicorn web server to serve it to the frontend.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Email hosts@dataengineeringpodcast.com ) with your story. Email hosts@dataengineeringpodcast.com ) with your story.
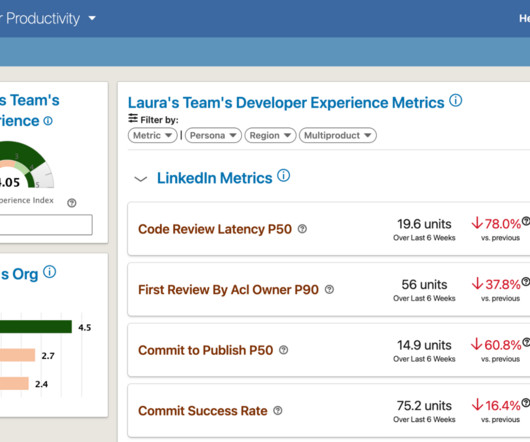
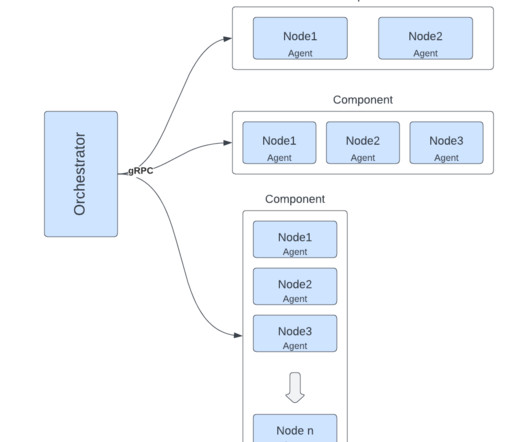
Co-authors: Arjun Mohnot , Jenchang Ho , Anthony Quigley , Xing Lin , Anil Alluri , Michael Kuchenbecker LinkedIn operates one of the world’s largest Apache Hadoop big data clusters. Historically, deploying code changes to Hadoop big data clusters has been complex.
With the help of ProjectPro’s Hadoop Instructors, we have put together a detailed list of big data Hadoop interview questions based on the different components of the Hadoop Ecosystem such as MapReduce, Hive, HBase, Pig, YARN, Flume, Sqoop , HDFS, etc. What is the difference between Hadoop and Traditional RDBMS?
The customer team included several Hadoop administrators, a program manager, a database administrator and an enterprise architect. Postgres 10, MySQL 5.7 The upgrade was driven by a task force that included the customer, Cloudera account team and Professional Services. OS – RHEL/CentOS/OEL 7.6/7.7/7.8 or Ubuntu 18.04.
hdfs dfs -cat” on the file triggers a hadoop KMS API call to validate the “DECRYPT” access. In this article, we will provide instructions on how to install and configure a MySQL instance as a backend for Ranger KMS. Ranger KMS supports MySQL, Postgresql as well as Oracle. Run below command to install MySQL 5.7
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloud storage services — Amazon S3, Azure Blob, and Google Cloud Storage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Data processing systems like Hadoop ; and. Kafka vs Hadoop.
For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka. Familiarity with database technologies such as MySQL, Oracle, and MongoDB. Knowledge of Hadoop, Spark, and Kafka.
Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. How is Hadoop related to Big Data? Explain the difference between Hadoop and RDBMS. Data Variety Hadoop stores structured, semi-structured and unstructured data. Hardware Hadoop uses commodity hardware.
Hadoop job interview is a tough road to cross with many pitfalls, that can make good opportunities fall off the edge. One, often over-looked part of Hadoop job interview is - thorough preparation. Needless to say, you are confident that you are going to nail this Hadoop job interview. directly into HDFS or Hive or HBase.
You should be well-versed with SQL Server, Oracle DB, MySQL, Excel, or any other data storing or processing software. Apache Hadoop-based analytics to compute distributed processing and storage against datasets. What are the features of Hadoop? Explain MapReduce in Hadoop. What is Data Modeling? What is a NameNode?
5 Programming Models Students study data-parallel analytics along with Hadoop MapReduce (YARN), distributed programming for the cloud, graph parallel analytics (with GraphLab 2.0), and iterative data-parallel analytics (with Apache Spark). Using Apache Hadoop, they can write their own MapReduce code and provision instances on Amazon EC2.
BigQuery saves us substantial time — instead of waiting for hours in Hive/Hadoop, our median query run time is 20 seconds for batch, and 2 seconds for interactive queries[3]. A Unified View for Operational Data We kept most of our operational data in relational databases, like MySQL.
A good understanding of big data technologies like Hadoop, HDFS, Hive, HBase is important to be able to integrate them with Apache Spark applications. Understanding of SQL database integration (Microsoft, Oracle, Postgres , and/or MySQL ). Working knowledge of S3, Cassandra, or DynamoDB.
Data connectors: Numerous data connections are supported by Tableau, including those for Dropbox, SQL Server, Salesforce, Google Sheets, Presto, Hadoop, Amazon Athena, and Cloudera. Some examples are Microsoft Excel, Text/CSV, folders, MS SQL Server, Access DB, Oracle Database, IBM DB2, MySQL database, PostgreSQL database and etc.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Hadoop / HDFS Apache’s open-source software framework for processing big data. HDFS stands for Hadoop Distributed File System.
Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing. Intellipaat Big Data Hadoop Certification Introduction : This Big Data training course helps you master big data and Hadoop skills like MapReduce, Hive, Sqoop, etc.
Relational Databases – The fundamental concept behind databases, namely MySQL, Oracle Express Edition, and MS-SQL that uses SQL, is that they are all Relational Database Management Systems that make use of relations (generally referred to as tables) for storing data.
It is commonly stored in relational database management systems (DBMSs) such as SQL Server, Oracle, and MySQL, and is managed by data analysts and database administrators. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data.
Amazon Web Services (AWS) Databases such as MYSQL and Hadoop Programming languages, Linux web servers and APIs Application programming and Data security Networking. Hybrid Cloud is essentially the combination of public and private clouds - two distinct entities that are bound together and work in unison.
Learning MySQL and Hadoop can be pleasant. The skills that are necessary for Cloud engineering jobs are enumerated as follows: Programming skills : Expertise in programming languages is essential. Languages like Java, Ruby, and PHP are in great demand. Database knowledge : Try to learn database management and querying.
Despite the buzz surrounding NoSQL , Hadoop , and other big data technologies, SQL remains the most dominant language for data operations among all tech companies. Data processing tasks containing SQL-based data transformations can be conducted utilizing Hadoop or Spark executors by ETL solutions.
Earlier at Yahoo, he was one of the founding engineers of the Hadoop Distributed File System. Traditionally, this information would be stored in transactional databases — Oracle Database , MySQL , PostgreSQL , etc. He was an engineer on the database team at Facebook, where he was the founding engineer of the RocksDB data store.
Be it PostgreSQL, MySQL, MongoDB, or Cassandra, Python ensures seamless interactions. Even in predominantly Java environments like Hadoop, Python carves its niche, with tools like Pydoop offering seamless interactions with the Hadoop Distributed File System (HDFS) and MapReduce.
Some open-source technology for big data analytics are : Hadoop. APACHE Hadoop Big data is being processed and stored using this Java-based open-source platform, and data can be processed efficiently and in parallel thanks to the cluster system. The Hadoop Distributed File System (HDFS) provides quick access. Apache Spark.
ODI has a wide array of connections to integrate with relational database management systems ( RDBMS) , cloud data warehouses, Hadoop, Spark , CRMs, B2B systems, while also supporting flat files, JSON, and XML formats. There are also out-of-the-box connectors for such services as AWS, Azure, Oracle, SAP, Kafka, Hadoop, Hive, and more.
During his time at Facebook, in the context of the MyRocks project, a fork of MySQL that replaces InnoDB with RocksDB as MySQL’s storage engine, Mark Callaghan performed extensive and rigorous performance measurements to compare MySQL performance on InnoDB vs on RocksDB. Details can be found here. trillion euros.
Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc. Thus, having worked on projects that use tools like Apache Spark, Apache Hadoop, Apache Hive, etc., Experience with using cloud services providing platforms like AWS/GCP/Azure. Good communication skills as a data engineer directly works with the different teams.
It would also be a good idea to have a good understanding of MySQL and Hadoop so that you can deal with data effectively. There are many benefits to having an understanding of database management skills like MySQL and Hadoop, since they will be of great help in the future.
He also has more than 10 years of experience in big data, being among the few data engineers to work on Hadoop Big Data Analytics prior to the adoption of public cloud providers like AWS, Azure, and Google Cloud Platform. On LinkedIn, he focuses largely on Spark, Hadoop, big data, big data engineering, and data engineering.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content