This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
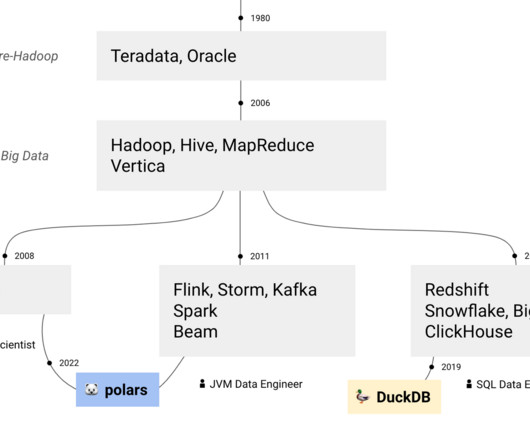
Good old data warehouses like Oracle were engine + storage, then Hadoop arrived and was almost the same you had an engine (MapReduce, Pig, Hive, Spark) and HDFS, everything in the same cluster, with data co-location. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with 3) Spark 4.0
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
Book Discount Use the code poddataeng18 to get 40% off of all of Manning’s products at manning.com Links Apache Spark Spark In Action Book code examples in GitHub Informix International Informix Users Group MySQL Microsoft SQL Server ETL (Extract, Transform, Load) Spark SQL and Spark In Action ‘s chapter 11 Spark ML and Spark In Action (..)
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
Apache Hadoop and Apache Spark fulfill this need as is quite evident from the various projects that these two frameworks are getting better at faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Table of Contents Why Apache Hadoop?
Python, Java, and Scala knowledge are essential for Apache Spark developers. Various high-level programming languages, including Python, Java , R, and Scala, can be used with Spark, so you must be proficient with at least one or two of them. Understanding of SQL database integration (Microsoft, Oracle, Postgres , and/or MySQL ).
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. The hybrid data platform supports numerous Big Data frameworks including Hadoop and Spark , Flink, Flume, Kafka, and many others. Kafka vs Hadoop. The Good and the Bad of Hadoop Big Data Framework.
Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. How is Hadoop related to Big Data? Explain the difference between Hadoop and RDBMS. Data Variety Hadoop stores structured, semi-structured and unstructured data. Hardware Hadoop uses commodity hardware.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential. show() So How Much Python Is Required for a Data Engineer?
You should be well-versed with SQL Server, Oracle DB, MySQL, Excel, or any other data storing or processing software. Apache Hadoop-based analytics to compute distributed processing and storage against datasets. Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale data processing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
Data modeling and database management: Data analysts must be familiar with DBMS like MySQL, Oracle, and PostgreSQL as well as data modeling software like ERwin and Visio. This procedure can be sped up with the aid of programmes like Open Refine and Trifacta.
He also has more than 10 years of experience in big data, being among the few data engineers to work on Hadoop Big Data Analytics prior to the adoption of public cloud providers like AWS, Azure, and Google Cloud Platform. On LinkedIn, he focuses largely on Spark, Hadoop, big data, big data engineering, and data engineering.
Average Salary: $126,245 Required skills: Familiarity with Linux-based infrastructure Exceptional command of Java, Perl, Python, and Ruby Setting up and maintaining databases like MySQL and Mongo Roles and responsibilities: Simplifies the procedures used in software development and deployment.
Olga is skilled in MySQL, PostgreSQL, and R and regularly publishes articles on topics like data analysis and machine learning. She has extensive experience in platform integration using advanced data mining and machine learning in Python, SQL, and R, and data engineering in Snowflake, Apache Spark, and Hadoop.
E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server. How does Network File System (NFS) differ from Hadoop Distributed File System (HDFS)? Network File System Hadoop Distributed File System NFS can store and process only small volumes of data. Explain how Big Data and Hadoop are related to each other.
Spark future — I'm convinced that Apache Spark will have to transform itself if it is not to disappear (disappear in the sense of Hadoop, still present but niche). Is it Java/Scala or Python? Neurelo raises $5m seed to provide HTTP APIs on top of databases (PostgreSQL, MongoDB and MySQL). Is it DataFrames or SQL?
Now that well-known technologies like Hadoop and others have resolved the storage issue, the emphasis is on information processing. Programming in several languages: Data Scientists frequently employ a variety of programming languages, including Python, R, C/C, SAS, Scala, and SQL. And Data Science has a significant impact here.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content