This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But is it truly revolutionary, or is it destined to repeat the pitfalls of past solutions like Hadoop? Danny authored a thought-provoking article comparing Iceberg to Hadoop , not on a purely technical level, but in terms of their hype cycles, implementation challenges, and the surrounding ecosystems.
dbt Labs also develop dbt Cloud which is a cloud product that hosts and runs dbt Core projects. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. You can initialise a project with the CLI command: dbt init. dbt/ folder.
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are HadoopProjects So Important?
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Quantifiable improvements to Apache open source projects.
If you've learned something or tried out a project from the show then tell us about it! If you've learned something or tried out a project from the show then tell us about it! The Machine Learning Podcast helps you go from idea to production with machine learning. Email hosts@dataengineeringpodcast.com with your story.
If you've learned something or tried out a project from the show then tell us about it! If you've learned something or tried out a project from the show then tell us about it! The Machine Learning Podcast helps you go from idea to production with machine learning. Email hosts@dataengineeringpodcast.com ) with your story.
Projects like Apache Iceberg provide a viable alternative in the form of data lakehouses that provide the scalability and flexibility of data lakes, combined with the ease of use and performance of data warehouses. What are the notable changes in the Iceberg project and its role in the ecosystem since our last conversation October of 2018?
Summary The Hadoop platform is purpose built for processing large, slow moving data in long-running batch jobs. To fill this need the Kudu project was created with a column oriented table format that was tuned for high volumes of writes and rapid query execution across those tables. How does it fit into the Hadoop ecosystem?
With their launch of Dagster+ as the redesigned commercial companion to the open source project they are investing in that capability with a suite of new features. What are the notable enhancements beyond the Dagster Core project that this updated platform provides? What problems are you trying to solve with Dagster+?
Data projects are notoriously complex. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro.
The interesting world of big data and its effect on wage patterns, particularly in the field of Hadoop development, will be covered in this guide. As the need for knowledgeable Hadoop engineers increases, so does the debate about salaries. You can opt for Big Data training online to learn about Hadoop and big data.
Summary Managing big data projects at scale is a perennial problem, with a wide variety of solutions that have evolved over the past 20 years. One of the early entrants that predates Hadoop and has since been open sourced is the HPCC (High Performance Computing Cluster) system.
This led to his creation of the Hadoop Weekly newsletter, which he recently rebranded as the Data Engineering Weekly newsletter. What are some of the projects that you have been involved in that were most personally fulfilling? What was your motivation for starting a newsletter about the Hadoop space?
To establish a career in big data, you need to be knowledgeable about some concepts, Hadoop being one of them. Hadoop tools are frameworks that help to process massive amounts of data and perform computation. You can learn in detail about Hadoop tools and technologies through a Big Data and Hadoop training online course.
In this post, we focus on how we enhanced and extended Monarch , Pinterest’s Hadoop based batch processing system, with FGAC capabilities. We discussed our project with technical contacts at AWS and brainstormed approaches, looking at alternate ways to grant access to data in S3. QueryBook uses OAuth to authenticate users.
Summary With the growth of the Hadoop ecosystem came a proliferation of implementations for the Hive table format. Unfortunately, with no formal specification, each project works slightly different which increases the difficulty of integration across systems.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. STORED AS TEXTFILE. location 'ofs://ozone1/s3v/spark-bucket/vaccine-dataset'. builder. .
As the data landscape matures, how have you seen that influence the types of projects/companies that are founded? If you've learned something or tried out a project from the show then tell us about it! As the data landscape matures, how have you seen that influence the types of projects/companies that are founded?
Vinoth Chandar helped to create the Hudi project while at Uber to address this challenge. By adding support for small, incremental inserts into large table structures, and building support for arbitrary update and delete operations the Hudi project brings the best of both worlds together. Can you describe how Hudi is architected?
Privacera is an enterprise grade solution for cloud and hybrid data governance built on top of the robust and battle tested Apache Ranger project. The most important piece of any data project is the data itself, which is why it is critical that your data source is high quality. Email hosts@dataengineeringpodcast.com ) with your story.
We recently embarked on a significant data platform migration, transitioning from Hadoop to Databricks, a move motivated by our relentless pursuit of excellence and our contributions to the XRP Ledger's (XRPL) data analytics. High maintenance costs and a system that struggled to meet the real-time demands of our data-driven initiatives.
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
In this episode, I interview Michael Drogalis, the founder and CEO of ShadowTraffic where we talked about the early Hadoop era and how he saw the need for Kafka in the industry. He shared his journey of starting a new company in his 20s and being acquired by Confluent.
As I look forward to the next decade of transformation, I see that innovating in open source will accelerate along three dimensions — project, architectural, and system. These are innovations by developers, for developers, and as adoption of OSS projects has grown, innovation at the project level has accelerated sharply.
Compatibility MapReduce is also compatible with all data sources and file formats Hadoop supports. Spark is developed in Scala language and it can run on Hadoop in standalone mode using its own default resource manager as well as in Cluster mode using YARN or Mesos resource manager. Spark is a bit bare at the moment.
Python Crash Course: A Hands-On, Project-Based Introduction to Programming Eric Matthes wrote "Python Crash Course: A Hands-On, Project-Based Introduction to Programming," published by No Starch Press. This book introduces data scientists to the Hadoop ecosystem and its tools for big data analytics. 5 stars on GoodReads.
If you’re struggling with unwieldy dimensional models, slow moving projects, or challenges integrating new data sources then listen in on this conversation and then give data vault a try for yourself. Is there any utility in data vault modeling in a data lake context (S3, Hadoop, etc.)?
Spark installations can be done on any platform but its framework is similar to Hadoop and hence having knowledge of HDFS and YARN is highly recommended. Spark standalone node cluster can be installed on the same nodes and configure Spark and Hadoop memory and CPU usage accordingly to avoid any interference. Basic knowledge of SQL.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
This makes it difficult to gain insights from across departments, projects, or people. Kamil Bajda-Pawlikowski co-founded Starburst Data to provide support and tooling for Presto, as well as contributing advanced features back to the project. This makes it difficult to gain insights from across departments, projects, or people.
hadoop-aws since we almost always have interaction with S3 storage on the client side). FROM openjdk:11-jre-slim WORKDIR /app # Here, we copy the common artifacts required for any of our Spark Connect # clients (primarily spark-connect-client-jvm, as well as spark-hive, # hadoop-aws, scala-library, etc.).
Evolution of Open Table Formats Here’s a timeline that outlines the key moments in the evolution of open table formats: 2008 - Apache Hive and Hive Table Format Facebook introduced Apache Hive as one of the first table formats as part of its data warehousing infrastructure, built on top of Hadoop.
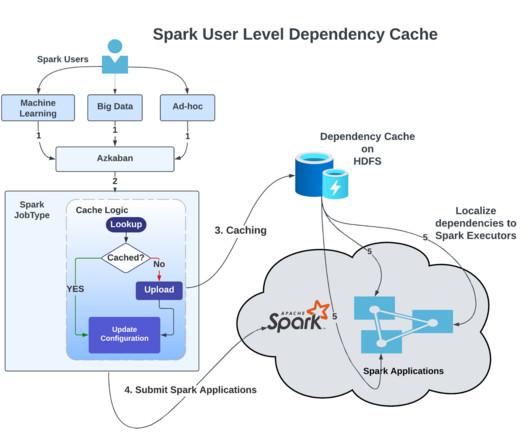
We execute nearly 100,000 Spark applications daily in our Apache Hadoop YARN (more on how we scaled YARN clusters here ). Every day, we upload nearly 30 million dependencies to the Apache Hadoop Distributed File System (HDFS) to run Spark applications. Conclusion Our project aligns with the " doing more with less " philosophy.
Hadoop Gigabytes to petabytes of data may be stored and processed effectively using the open-source framework known as Apache Hadoop. Hadoop enables the clustering of many computers to examine big datasets in parallel more quickly than a single powerful machine for data storage and processing. Packages and Software OpenCV.
I started my current career path with Hortonworks in 2016, back when we still had to tell people what Hadoop was. An opportunity to pursue an exciting new project at a major fortune 500 company came up and I decided to give it a try. Once I got to work with all the amazing open-source Apache tools I was hooked.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out Linode. What is the governance model for the project?
Introduction Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out Linode. Can you refresh our memory about what TimescaleDB is?
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data infrastructure When you’re ready to launch your next project you’ll need somewhere to deploy it. Can you start by explaining what Timescale is and how the project got started? release of PostGreSQL had on the design of the project?
In this episode Sijie Guo discusses his motivations for spending so much of his time and energy on contributing to the project and growing the community. This was a great conversation about the strengths of the Pulsar project, how it has evolved in recent years, and some of the innovative ways that it is being used.
In this episode Sage Weil, the creator and lead maintainer of the project, discusses how it got started, how it works, and how you can start using it on your infrastructure today. What was the motivation for starting the project? What was the motivation for starting the project? Can you start with an overview of what Ceph is?
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data infrastructure When you’re ready to launch your next project you’ll need somewhere to deploy it.
In this episode the CEO of Metabase, Sameer Al-Sakran, discusses how and why the project got started, the ways that it can be used to build and share useful reports, some of the useful features planned for future releases, and how to get it set up to start using it in your environment.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out Linode. What are some of the primary ways that Flink is used?
Azure Data engineering projects are complicated and require careful planning and effective team participation for a successful completion. The Azure Data Engineer certification aspirants frequently seek out real-world projects in order to obtain hands-on experience and demonstrate their skills.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content