This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
Would you like help maintaining high-qualitydata across every layer of your Medallion Architecture? Like an Olympic athlete training for the gold, your data needs a continuous, iterative process to maintain peak performance.
Spotify offers hyper-personalized experiences for listeners by analysing user data. Key Components of an Effective Predictive Analytics Strategy Clean, high-qualitydata: Predictive analytics is only as effective as the data it analyses.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial data validation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes. But this process takes countless hours of time and effort.
Proactive dataquality measures are critical, especially in AI applications. Using AI systems to analyze and improve dataquality both benefits and contributes to the generation of high-qualitydata. Bias is a very critical topic in AI,” notes Bapat.
million customers worldwide, recognized how the immense volume of data they maintained could provide better insight into customers’ needs. Since leveraging Cloudera’s data platform, Rabobank has been able to improve its customers’ financial management. Rabobank , headquartered in the Netherlands with over 8.3
This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata. Given where that training data came from, it’s probable that it might misrepresents or underrepresents particular groups or concepts be given the wrong label.
It’s called deep because it comprises many interconnected layers — the input layers (or synapses to continue with biological analogies) receive data and send it to hidden layers that perform hefty mathematical computations. Plus, you likely won’t be able to use too much data. Assessing text dataquality.
Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors. There are multiple locations where problems can happen in a data and analytic system. What is Data in Use?
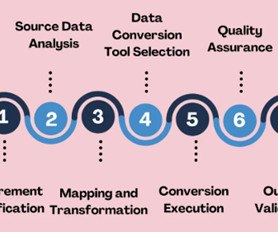
Selecting the strategies and tools for validating data transformations and data conversions in your data pipelines. Introduction Data transformations and data conversions are crucial to ensure that rawdata is organized, processed, and ready for useful analysis.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances dataquality, governance, and automation, transforming rawdata into valuable insights. This is what managing data without metadata feels like. Chaos, right?
A solution that helps with supply chain issues, for instance, will need access to rawdata on things such as weather, commodity risks, UPC-level attributes of products, and consumer transactions. That access needs to be fast and seamless.
Now, the primary function of data labeling is tagging objects on rawdata to help the ML model make accurate predictions and estimations. That said, data annotation is key in training ML models if you want to achieve high-quality outputs. Guaranteeing high-qualitydata with consistency.
At the opposite end of the spectrum, an abundance of data can be overwhelming. The key to effective data-driven decisions lies in curating enough high-qualitydata to adequately understand the situation, factor in the important variables, and draw confident conclusions. This process can be challenging.
Reading Time: 8 minutes In the world of data engineering, a mighty tool called DBT (Data Build Tool) comes to the rescue of modern data workflows. Imagine a team of skilled data engineers on an exciting quest to transform rawdata into a treasure trove of insights.
while overlooking or failing to understand what it really takes to make their tools — and, ultimately, their data initiatives — successful. When it comes to driving impact with your data, you first need to understand and manage that data’squality.
This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata. Given where that training data came from, it’s probable that it might misrepresents or underrepresents particular groups or concepts be given the wrong label.
It enables: Enhanced decision-making: Accurate and reliable data allows businesses to make well-informed decisions, leading to increased revenue and improved operational efficiency. Risk mitigation: Data errors can result in expensive mistakes or even legal issues.
Data Sources Diverse and vast data sources, including structured, unstructured, and semi-structured data. Structured data from databases, data warehouses, and operational systems. Goal Extracting valuable information from rawdata for predictive or descriptive purposes.
With these points in mind, I argue that the biggest hurdle to the widespread adoption of these advanced techniques in the healthcare industry is not intrinsic to the industry itself, or in any way related to its practitioners or patients, but simply the current lack of high-qualitydata pipelines.
Too much data Too much data might not sound like a problem (it is called big data afterall), but when rows populate out of proportion, it can slow model performance and increase compute costs.
AI models are only as good as the data they consume, making continuous data readiness crucial. Here are the key processes that need to be in place to guarantee consistently high-qualitydata for AI models: Data Availability: Establish a process to regularly check on data availability.
They employ a wide array of tools and techniques, including statistical methods and machine learning, coupled with their unique human understanding, to navigate the complex world of data. A significant part of their role revolves around collecting, cleaning, and manipulating data, as rawdata is seldom pristine.
Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-qualitydata in Delta Lake. Azure Blob Storage serves as the data lake to store rawdata. Databricks Notebooks are often used in conjunction with Workflows.
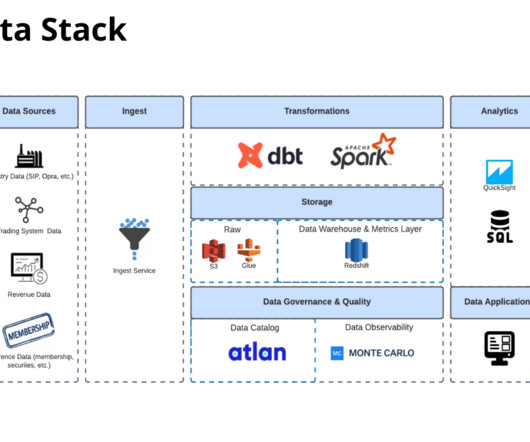
Data ingestion When we think about the flow of data in a pipeline, data ingestion is where the data first enters our platform. There are two primary types of rawdata.
Observability platforms not only supply rawdata but also offer actionable insights through visualizations, dashboards, and alerts. Databand allows data engineering and data science teams to define dataquality rules, monitor data consistency, and identify data drift or anomalies.
Whether the end result is a weekly report, dashboard, or embedded in a customer facing application, data products require a level of polish and data curation that is antithetical to unorganized sprawl. Your ability to pipe data is virtually limitless, but you are constrained by the capacity of humans to make it sustainably meaningful.
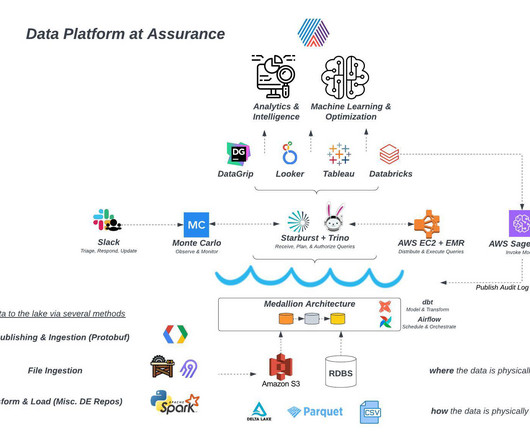
Business data assets at Assurance are loaded into the company’s lakehouse architecture through various methods, then stored in several data stores. The data team then uses tools like dbt and Airflow to refine, model and transform rawdata into usable, query-able assets through Trino and Starburst.
Not long after data warehouses moved to the cloud, so too did data lakes (a place to transform and store unstructured data), giving data teams even greater flexibility when it comes to managing their data assets. That is the question – at least if you ask a data engineer.
Trustworthy Analytics: Reliable data supports accurate statistical analysis. Enhanced Visualization: Clean data leads to clearer data visualizations. Efficient Machine Learning: High-qualitydata is vital for training accurate ML models. What is the difference between data cleaning and data transformation?
The `dbt run` command will compile and execute your models, thus transforming your rawdata into analysis-ready tables. Once the models are created and data transformed, `dbt test` should be executed. This command runs all tests defined in your dbt project against the transformed data.
While tempting to write-off our product stakeholders as not understanding our field, it’s very often because analysts are stuck responding to rudimentary questions that could be addressed with better access to high-qualitydata, rather than spending time on more sophisticated, thorough, or profound analysis that clearly demonstrates their expertise.
Providing a comprehensive suite of features, from alerts and analytics to fast integration and data tests, ‘The Traveler’ empowers the End-to-End Data Product Team to manage their data landscape proactively. The Hub Data Journey provides the rawdata and adds value through a ‘contract.
A 2023 Salesforce study revealed that 80% of business leaders consider data essential for decision-making. However, a Seagate report found that 68% of available enterprise data goes unleveraged, signaling significant untapped potential for operational analytics to transform rawdata into actionable insights.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content