This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A replication slot should be created for each client - so in this case we have blue (upper, denoted 1 ) and pink (lower, denoted 2 ) replication slots - and each slot will contain information about the progress of its client through the WAL.
Docker for Redis and PostgreSQL We’ll be using Docker images for Redis and Postgres. Skunk for PostgreSQL Integration In this section, we’ll implement the protocols necessary for interacting with Postgres in our application using Skunk. object message {. To follow along, you’ll need Docker and Docker Compose installed. flatMap { _.
[link] SquareSpace: Leveraging Change Data Capture For Database Migrations At Scale Squarespace writes about migrating their business-critical PostgreSQL databases to CockroachDB (CRDB) at scale. I have provided links for informational purposes and do not suggest endorsement. link] All rights reserved, ProtoGrowth Inc.,
Today, Snowflake advances our vision to be the ultimate platform for data-driven innovation with our announcement that we have agreed to acquire Crunchy Data, a leading provider of trusted, open source PostgreSQL technology. Snowflakes platform serves as the foundation for Blue Yonders vast amount of supply chain data.
This blog post explains to you which tools to use to serve geospatial data from a database system (PostgreSQL) to your web browser. At Zalando, the open source database system PostgreSQL is used by many teams and it offers a geospatial component called PostGIS. The vector tile format must not consist solely of the geometry.
PostgreSQL and MySQL are among the most popular open-source relational database management systems (RDMS) worldwide. For all of their similarities, PostgreSQL and MySQL differ from one another in many ways. That’s because MySQL isn’t fully SQL-compliant, while PostgreSQL is.
In practical terms, this means creating a system where everyone in your organization understands what data they’re handling and how to treat it appropriately, with safeguards if someone accidentally tries to mishandle sensitive information. Step 2: Hunt Down the Sensitive Stuff Now its time to play detective in your database.
In the database ecosystem, Postgres is one of the top open-source databases, and one of the most widely used PSQL tools for managing PostgreSQL is pgAdmin. To run PostgreSQL instances on the Azure cloud, Azure offers Azure Database for PostgreSQL. What are PostgreSQL Tools? Why Use a GUI Tool?
While Atlas operates as an in-memory graph database for speed and performance, it uses PostgreSQL as its persistent storage layer to ensure durability and long-term data storage. A table named commit, that stores information about schema commits, including commit number and time. These data objects are referred to as “storables”.
The following sections provide additional details on other aspects of how this is implemented, as well as information on steps to take to set this up for yourself. In addition to AKS and the load balancers mentioned above, this includes VNET, Data Lake Storage, PostgreSQL Azure database, and more. Activating CDW with Private AKS.
We knew we’d be deploying a Docker container to Fargate as well as using an Amazon Aurora PostgreSQL database and Terraform to model our infrastructure as code. Set up a locally running containerized PostgreSQL database. For more information on the Dockerfile spec, you can check out the Docker documentation here.
With the first wave of cloud era databases the ability to replicate information geographically came at the expense of transactions and familiar query languages. I know that your SQL syntax is PostGreSQL compatible, so is it possible to use existing ORMs unmodified with CockroachDB?
Part 1: Setup dbt project and database Step 1: Install project dependencies Before you can get started: You must have either DuckDB or PostgreSQL installed. Choose one, and download and install the database using one of the following links: Download DuckDB Download PostgreSQL You must have Python 3.8
Recently my team and I observed in our PostgreSQL databases a sporadic increase in the execution time of stored procedures (see the graph above). To find answers, we tested how different configurations of PostgreSQL influenced the results of the query planner. PostgreSQL also addresses non-uniform distributions.
As a data-driven business, extracting meaningful data from various sources and making informed decisions relies heavily on effective data analysis. To unlock the full potential of your data in PostgreSQL on Google Cloud SQL necessitates data integration with Amazon Aurora.
PostgreSQL is a very flexible database system. There are multiple system catalogs: pg_class stores information about tables, pg_type describes types. There are multiple system catalogs: pg_class stores information about tables, pg_type describes types. Its flexibility derives from its way of storing metadata.
Since early 2020, Netflix has been iteratively developing systems to provide internal stakeholders and business leaders with up-to-date tools and dashboards with the latest information on the pandemic. Use PostgreSQL Composite Types when taking advantage of PostgreSQL Aggregate Functions.
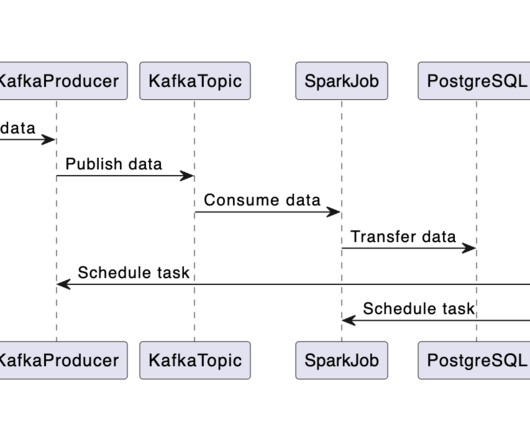
This involves getting data from an API and storing it in a PostgreSQL database. Data Processing: A Spark job then takes over, consuming the data from the Kafka topic and transferring it to a PostgreSQL database. This article is part of a project that’s split into two main phases. The first phase focuses on building a data pipeline.
What are some of the most interesting or unexpected uses of your platform that you are aware of? What are some of the most interesting or unexpected uses of your platform that you are aware of?
Presto is a distributed SQL engine that allows you to tie all of your information together without having to first aggregate it all into a data warehouse. Presto is a distributed SQL engine that allows you to tie all of your information together without having to first aggregate it all into a data warehouse.
Summary Elasticsearch is a powerful tool for storing and analyzing data, but when using it for logs and other time oriented information it can become problematic to keep all of your history. What are some of the most interesting or unexpected uses of Chaos Search and access to large amounts of historical log information that you have seen?
The record in the “outbox” table contains information about the event that happened inside the application, as well as some metadata that is required for further processing or routing. Other events such as DELETE can be ignored now, as it does not contain useful information for our use case. transforms: The name of the transformation.
In this episode ThreatStack’s director of operations, Pete Cheslock, and senior infrastructure security engineer, Patrick Cable, discuss the data infrastructure that supports their platform, how they capture and process the data from client systems, and how that information can be used to keep your systems safe from attackers.
I'm not informed enough so I'll wait before giving my opinion on it. Change Data Capture (CDC) with PostgreSQL and ClickHouse — This is a nice vendor post about CDC with Kafka as movement layer (using Debezium). Also called GDPR 2.0 the AI Act is meant to regulate the usage of AI in tomorrow's world. This is neat.
As organizations grow and data sources proliferate it becomes difficult to keep track of everything, particularly for analysts and data scientists who are not involved with the collection and management of that information. How does the information in Amundsen get populated and what is the process for keeping it up to date?
SurrealDB is the solution for database administration, which includes general admin and user management, enforcing data security and control, performance monitoring, maintaining data integrity, dealing with concurrency transactions, and recovering information in the event of an unexpected system failure. What is Jamstack?
What is overlooked in that characterization is the level of complexity and effort that are required to collect and present that information, and the opportunities for providing those insights in other contexts. How are you approaching schema design and evolution in the storage layer?
In addition to storing schema information you allow users to store information about the transformations being performed. How can users populate information about their transformations in an automated fashion? How do you approach evolution and versioning of schema information? How is that represented?
What are the downstream challenges or complications that application designers or systems architects have to deal with to make use of that information? What are the downstream challenges or complications that application designers or systems architects have to deal with to make use of that information?
In this episode co-founder Martin Sahlen explains the impact that easy access to lineage information can have on the work of data engineers and analysts, and how he and his team have designed their platform to offer that information to engineers and stakeholders in the places that they interact with data.
For a substantial number of use cases, the optimal format for storing and querying that information is as a graph, however databases architected around that use case have historically been difficult to use at scale or for serving fast, distributed queries. How does the query interface and data storage in DGraph differ from other options?
In this episode Eric Kansa describes how they process, clean, and normalize the data that they host, the challenges that they face with scaling ETL processes which require domain specific knowledge, and how the information contained in connections that they expose is being used for interesting projects.
In order to handle the volume and variety of information that they use to run and improve the business the data team has to build a platform that analysts and data scientists can use in a self-service manner. What secondary or third party sources of information do you rely on? What do you do with that information?
What is a typical lifecycle of information in ksqlDB? What is a typical lifecycle of information in ksqlDB? Typically a database is considered a long term storage location for data, whereas Kafka is a streaming layer with a bounded amount of durable storage.
See our latest 10-Q for more information. Snowflake’s native connectors , including the existing Snowflake Connector for Kafka and for ServiceNow , are built with scalability, cost efficiency and lower latency. Getting data ingested now only takes a few clicks, and the data is encrypted.
What are the benefits of using PostgreSQL as the system of record for Marquez? What are some of the interesting questions that can be answered from the information stored in Marquez? What are the benefits of using PostgreSQL as the system of record for Marquez? How is the metadata itself stored and managed in Marquez?
In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses.
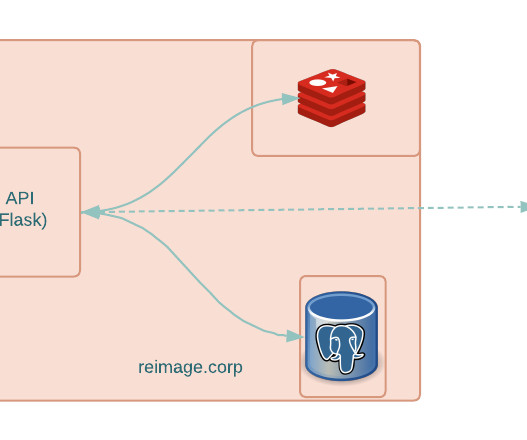
There was reliance on an unmanaged data layer.Redis (for caching) and PostgreSQL (as primary datastore)served as single points of failure for this product. Managing data replication for data in PostgreSQL could have been more robust. It required an engineer (with access to this keystore) to be logged in at the time of deployment.
Intuit provides insightful information about performing a set of tests called machine learning model sanity checks in a pre-production environment. link] WTTJ Tech: From PostgreSQL to Snowflake - A data migration story WTTJ Tech has an interesting story to share about data migration.
Two of the most recognized positions for API information are XML and JSON. Knowledge of Databases When working on a project, you must realize that data storage is essential since they contain a lot of information. Therefore, developers employ MySQL, SQL, PostgreSQL, MongoDB, etc., to manage DBMS.
The result will be put on another topic, in which case a failed response would contain a reason for the failure, and the successful response might contain additional information. The blue parts represent PostgreSQL databases, and turquoise is a Nginx web server. The command handler has two external connections to Kafka and PostgreSQL.
It is important because you would want to ensure that you are collecting appropriate information from users and this is achieved by ensuring that your users are entering the correct details. One way to ensure that users give the appropriate information is through form handling. Let’s understand this with an example.
However, managing data can be a challenging task, especially when dealing with large amounts of information. A database management system (DBMS) is a software system that helps organize, store and manage information efficiently. The system can be designed to track employee information such as hours worked, wages and taxes.
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka. The EDS resource includes pod IP addresses and their AZ information. The EDS resource includes pod IP addresses and their AZ information.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content