This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s create a validateutility.scala in the following path, src/main/scala/rockthejvm/websockets/domain , and add the following code: package rockthejvm.websockets.domain import cats.data.Validated object validateutility { def validateItem [ F ]( value : String , userORRoom : F , name : String ) : Validated [ String , F ] = { Validated.
The team at Skyflow decided that the second best way is to build a storage system dedicated to securely managing your sensitive information and making it easy to integrate with your applications and data systems. And don’t forget to thank them for their continued support of this show! Atlan is the metadata hub for your data ecosystem.
If you want to master the Typelevel Scala libraries (including Http4s) with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. HOTP scala implementation HOTP generation is quite tedious, therefore for simplicity, we will use a java library, otp-java by Bastiaan Jansen.
It works by bundling up data in a UDP packet, adding header information, and sending these packets to the target destination. Setting Up Let’s create a new Scala 3 project and add the following to your build.sbt file. Lets see how we can search for network interfaces in scala: import cats.effect. val scala3Version = "3.3.1"
Snowflakes Snowpark is a game-changing feature that enables data engineers and analysts to write scalable data transformation workflows directly within Snowflake using Python, Java, or Scala. RAW_CUSTOMERS : Stores customer information. The data resides in three tables: RAW_ORDERS : Captures order details.
However, this ability to remotely run client applications written in any supported language (Scala, Python) appeared only in Spark 3.4. In any case, all client applications use the same Scala code to initialize SparkSession, which operates depending on the run mode. getOrCreate() // If the client application uses your Scala code (e.g.,
Antonio is an alumnus of Rock the JVM, now a senior Scala developer with his own contributions to Scala libraries and junior devs under his mentorship. Which brings us to this article: Antonio originally started from my Sudoku backtracking article and built a Scala CLI tutorial for the juniors he’s mentoring.
The assessment is built by scanning any codebase written in Python or Scala and outputting a readiness score for conversion to Snowpark. As a result, the tool can take in both code files and notebooks with multiple languages (such as Scala, Python and SQL) at the same time. Try it today to see how smooth the on-ramp to Snowpark can be.
For more information on this and other examples please visit the Dataflow documentation page." This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps. A large number of our data users employ SparkSQL, pyspark, and Scala. scala-workflow ? ???
The authorization server on app2 will respond with a token id and an access token app1 can now request the user’s information from app2’s API using the access token. In this section, we’ll build an application that connects to GitHub using OAuth and request user information using the GitHub API. Accessing the Github API through OAuth.
It’s no secret that Zalando Tech has had its hands full lately with its participation in several Scala conferences and meetups. As a company who practices Radical Agility , our use of Scala has skyrocketed and it’s now one of our most adopted programming languages amongst developers. So, where have we been in the Scala world?
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. by Herbert Kateu Hey, it’s Daniel here. val scala3Version = "3.2.2"
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. by Herbert Kateu Hey, it’s Daniel here. val scala3Version = "3.2.2"
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala In this post we will combine some ideas from functional programming with strong typing to produce robust expressive code that is more reusable.
you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with Here what Databricks brought this year: Spark 4.0 — (1) PySpark erases the differences with the Scala version, creating a first class experience for Python users. (2) Databricks sells a toolbox, you don't buy any UX. 3) Spark 4.0
Another category of unstructured data that every business deals with is PDFs, Word documents, workstation backups, and countless other types of information. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Play Framework “makes it easy to build web applications with Java & Scala”, as it is stated on their site, and it’s true. In this article we will try to develop a basic skeleton for a REST API using Play and Scala. PlayScala plugin defines default settings for Scala-based applications. import Keys._ get ( id ).
For more information about CDSW visit the Cloudera Data Science Workbench product page. Value: /opt/cloudera/parcels/CDH/lib/hbase_connectors/lib/hbase-spark.jar:/opt/cloudera/parcels/CDH/lib/hbase_connectors/lib/hbase-spark-protocol-shaded.jar:/opt/cloudera/parcels/CDH/jars/scala-library-2.11.12.jar. Restart Region Servers.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
Some teams use tools like dependabot , scala-steward that create pull requests in repositories when new library versions are available. The Software Bill of Materials contains information about the packages and libraries used by an application. Other teams update dependencies regularly in bulk, supported by build system plugins (e.g.
In this episode he shares his journey from building a consumer product to launching a data pipeline service and how his frustrations as a product owner have informed his work at Hevo Data. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses.
Summary Elasticsearch is a powerful tool for storing and analyzing data, but when using it for logs and other time oriented information it can become problematic to keep all of your history. What are some of the most interesting or unexpected uses of Chaos Search and access to large amounts of historical log information that you have seen?
Metabase is a tool built with the goal of making the act of discovering information and asking questions of an organizations data easy and self-service for non-technical users.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development. This can come with tedious checks on secure information like PII, extra layers of security, and more meetings with the legal team.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. How has that informed your efforts in the development and release of the project? How has that informed your efforts in the development and release of the project?
How do you ensure the integrity and accuracy of that information? What is your approach for merging and enriching event data with the information that you retrieve from your supported integrations? How do you ensure the integrity and accuracy of that information? What challenges does that pose in your processing architecture?
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. They no longer need to ask a small subset of the organization to provide them with information, rather, they have tooling, systems, and capabilities to get the data they need. A rare breed.
And even if you were to gather all the information from the docs, it's still not enough. It provides a powerful information retrieval language and engine that integrates several microservice components built by the Search Department. From the description on its (internal) repository page: Origami is the Zalando Core Search API.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development.
Links Alooma Convert Media Data Integration ESB (Enterprise Service Bus) Tibco Mulesoft ETL (Extract, Transform, Load) Informatica Microsoft SSIS OLAP Cube S3 Azure Cloud Storage Snowflake DB Redshift BigQuery Salesforce Hubspot Zendesk Spark The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay (..)
This data engineering skill set typically consists of Java or Scala programming skills mated with deep DevOps acumen. They no longer need to ask a small subset of the organization to provide them with information, rather, they have tooling, systems, and capabilities to get the data they need. A rare breed.
Enter the new Event Tables feature, which helps developers and data engineers easily instrument their code to capture and analyze logs and traces for all languages: Java, Scala, JavaScript, Python and Snowflake Scripting. For further information about how Event Tables work, visit Snowflake product documentation.
For example, we recently examined data on Ethereum smart contract interactions and clearly identified patterns of usage that could inform future development in what is essentially a machine dominated ecosystem. Complementary data types such as transaction receipts, event logs, and state diffs are also extracted.
Git Git, or Global Information Tracker is a version control system popular among DevOps users. ScalaScala is a programming language that combines object-oriented and functional programming paradigms. It runs on the JVM and offers seamless Java interoperability, making it easy for Java developers to transition to Scala.
Data scientists are thought leaders who apply their expertise in statistics and machine learning to extract useful information from data. It is a declarative language for interacting with databases and allows you to create queries to extract information from your data sets.
In this episode Shinji Kim discusses the challenges of data discovery and how to collect and preserve additional context about each piece of information so that you can find what you need when you don’t even know what you’re looking for yet. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
For example, the data storage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. Snowflake is the pioneer of the Data Cloud , a global, federated network for secure, governed information exchange.
Sust Global was created to provide curated data sets for organizations to be able to analyze climate information in the context of their business needs. In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses.
In this episode co-founder Martin Sahlen explains the impact that easy access to lineage information can have on the work of data engineers and analysts, and how he and his team have designed their platform to offer that information to engineers and stakeholders in the places that they interact with data.
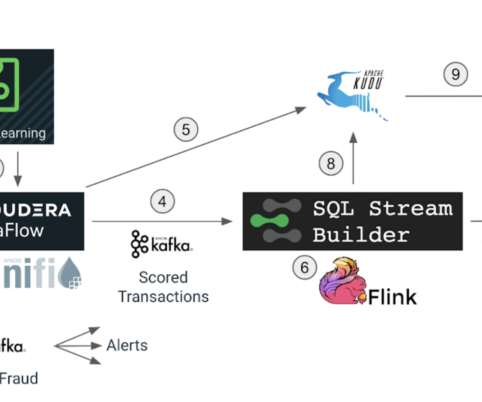
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap.
It takes python/java/scala/R/SQL and converts that code into a highly optimized set of transformations. Ok, hopefully not all of that was new information. 5— Use SQL Syntax Whether you’re using scala, java, python, SQL, or R, spark will always leverage the same transformations under the hood. Let’s dive in! Image by author.
CI/CD) Once a model is in production, what are the types and sources of information that you collect to monitor their performance? CI/CD) Once a model is in production, what are the types and sources of information that you collect to monitor their performance? What are the factors that contribute to model drift?
In addition, data discovery is made easy through Sifflet’s information-rich data catalog with a powerful search engine and real-time health statuses. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Who are your target customers and how does that focus inform your product and feature priorities? Who are your target customers and how does that focus inform your product and feature priorities? This has led to an explosion of database engines and related tools to address these different needs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content