This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Together, MongoDB and Apache Kafka ® make up the heart of many modern data architectures today. Integrating Kafka with external systems like MongoDB is best done though the use of Kafka Connect. The official MongoDB Connector for Apache Kafka is developed and supported by MongoDB engineers.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. BigQuery, Amazon Redshift, and MongoDB Atlas) and caches (e.g.,
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Here in part 4 of the Spring for Apache Kafka Deep Dive blog series, we will cover: Common event streaming topology patterns supported in Spring Cloud Data Flow. Create and manage event streaming pipelines, including a Kafka Streams application using Spring Cloud Data Flow. java -jar spring-cloud-dataflow-shell-2.1.0.RELEASE.jar.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development. Get familiar with data warehouses, data lakes, and data lakehouses, including MongoDB , Cassandra, BigQuery, Redshift and more.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
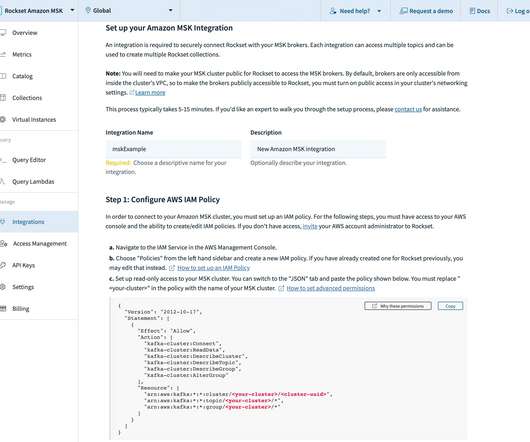
Rockset’s native connector for Amazon Managed Streaming for Apache Kafka (MSK) makes it simpler and faster to ingest streaming data for real-time analytics. Amazon MSK is a fully managed AWS service that gives users the ability to build and run applications using Apache Kafka.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
We’re introducing a new Rockset Integration for Apache Kafka that offers native support for Confluent Cloud and Apache Kafka, making it simpler and faster to ingest streaming data for real-time analytics. With the Kafka Integration, users no longer need to build, deploy or operate any infrastructure component on the Kafka side.
There are a variety of big data processing technologies available, including Apache Hadoop, Apache Spark, and MongoDB. Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase.
Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. Java, Android Studio, and SQLite are the tools used to create an app that helps commuters to book train tickets directly from their mobile devices. cvtColor(image, cv2.COLOR_BGR2GRAY) findContours(thresh, cv2.RETR_TREE,
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). Key education and technical skills include: A degree in computer science, information technology, or a related field Expert in programming languages Python, Java, and SQL. Knowledge of Hadoop, Spark, and Kafka.
Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go. Microsoft SQL Server Document-oriented database: MongoDB (classified as NoSQL) The Basics of Data Management, Data Manipulation and Data Modeling This learning path focuses on common data formats and interfaces.
Data Science also requires applying Machine Learning algorithms, which is why some knowledge of programming languages like Python, SQL, R, Java, or C/C++ is also required. They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Kafka: Kafka is a top engineering tool highly valued by big data experts. Machine learning engineer: A machine learning engineer is an engineer who uses programming languages like Python, Java, Scala, etc.
Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering. Data processing: Data engineers should know data processing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential. csv') data_excel = pd.read_excel('data2.xlsx')
It uses Cognito federated identities in conjunction with AWS IoT to create a client certificate and private key and store it in a local Java Keystore. The app will use the certificate and private key saved in the local java Keystore for future connections. We had selected Amazon MSK to run Kafka and Spark.
Introduction Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time analytics is a challenge for many teams. The connector does require installing and managing additional tooling, Kafka Connect. This is because the mapping cannot be changed once it is already defined.
Experience with data warehousing and ETL concepts, as well as programming languages such as Python, SQL, and Java, is required. Data engineers must be well-versed in programming languages such as Python, Java, and Scala. A data engineer should be familiar with popular Big Data tools and technologies such as Hadoop, MongoDB, and Kafka.
Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. Java, Android Studio, and SQLite are the tools used to create an app that helps commuters to book train tickets directly from their mobile devices. cvtColor(image, cv2.COLOR_BGR2GRAY) findContours(thresh, cv2.RETR_TREE,
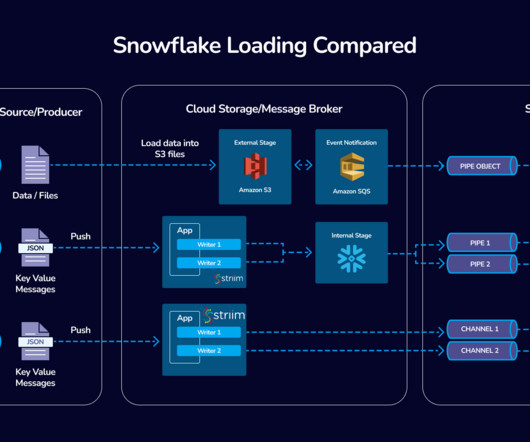
Versatile Source Connectivity: Striim offers a wide array of streaming source connectors including databases like Oracle, Microsoft SQL Server, MongoDB, PostgreSQL, IoT streams, Kafka, and many more.
Programming languages like Python, Java, or Scala require a solid understanding of data engineers. Popular Big Data tools and technologies that a data engineer has to be familiar with include Hadoop, MongoDB, and Kafka. Data engineers handle vast volumes of data on a regular basis and don't only deal with normal data.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. Equip yourself with the experience and know-how of Hadoop, Spark, and Kafka, and get some hands-on experience in AWS data engineer skills, Azure, or Google Cloud Platform. You can also post your work on your LinkedIn profile.
This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API, and the data is stored in a column store called HBase. Finally, the data is published and visualized on a Java-based custom Dashboard. Collection happens in the Kafka topic.
Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Hadoop, MongoDB, and Kafka are popular Big Data tools and technologies a data engineer needs to be familiar with. They should be able to use PowerShell, read C# or Java code, and understand JSON.
Hadoop ecosystem has a very desirable ability to blend with popular programming and scripting platforms such as SQL, Java , Python, and the like which makes migration projects easier to execute. Tools/Tech stack used: The tools and technologies used for such healthcare data management using Apache Hadoop are MapReduce and MongoDB.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
He currently runs a YouTube channel, E-Learning Bridge , focused on video tutorials for aspiring data professionals and regularly shares advice on data engineering, developer life, careers, motivations, and interviewing on LinkedIn.
They get used in NoSQL databases like Redis, MongoDB, data warehousing. DB used in AWS MariaDB, Postgres, MongoDB, Oracle, MySQL are some common databases used in AWS. It supports PHP, GO, Java, Node,NET, Python, and Ruby. These instances use their local storage to store data.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
Apache Hadoop is an open-source Java-based framework that relies on parallel processing and distributed storage for analyzing massive datasets. Streaming analytics became possible with the introduction of Apache Kafka , Apache Spark , Apache Storm , Apache Flink , and other tools to build real-time data pipelines. What is Hadoop?
For this reason, learn an enterprise language, such as Java or C#. Numerous NoSQL databases are used today, including MongoDB, Cassandra, and Ruby. Apache Kafka is a well-liked tool for creating a broadcasting pipeline and is used by over 80% of Fortune 500 firms. Five Steps to Starting a Successful Career as a Data Engineer.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content