This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
A trend often seen in organizations around the world is the adoption of Apache Kafka ® as the backbone for data storage and delivery. We decided to write our code for one specific Java EE application server, and that cost us the ability to run the software in other Java EE application servers required by other banks.
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. They have to know Java to go deep in Hadoop coding and effectively use features available via Java APIs. Alternatively, you can opt for Apache Cassandra — one more noSQL database in the family.
Java programming roles need to cover a lot of ground when it comes to knowledge and processes. We’ve put together a list of essential points that developers should be familiar with when applying for a Java development position. You’ll want to use functional idioms, but don’t overuse them: Java is not a functional language.
The profile service will publish the changes in profiles, including address changes to an Apache Kafka ® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. They achieve this through a programming language such as Java or C++. It is considered the most commonly used and most efficient coding language for a Data engineer and Java, Perl, or C/ C++.
Data Science also requires applying Machine Learning algorithms, which is why some knowledge of programming languages like Python, SQL, R, Java, or C/C++ is also required. They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase.
Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. Java, Android Studio, and SQLite are the tools used to create an app that helps commuters to book train tickets directly from their mobile devices. cvtColor(image, cv2.COLOR_BGR2GRAY) findContours(thresh, cv2.RETR_TREE,
Apache HBase (NoSQL), Java, Maven: Read-Write. A Java application that creates an HBase table, writes some records and validates that it can read those records from the table via the HBase Java API. . Apache Phoenix (SQL), Java, Dropwizard: Stock ticker. Apache Phoenix (SQL), Java, Maven: Read-Write.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
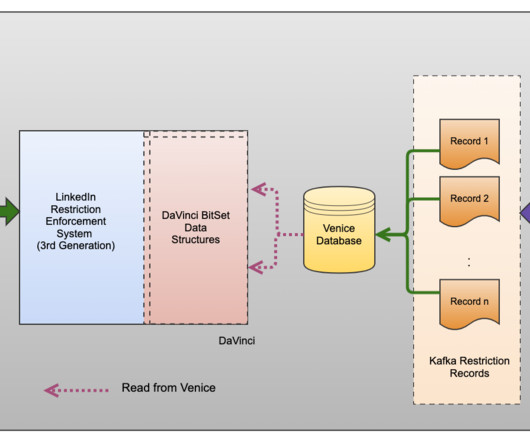
LinkedIn restriction enforcement system (2nd generation) First, we migrated all member restrictions data to Espresso , LinkedIn’s custom-built NoSQL distributed document storage solution. Espresso’s tight integration with LinkedIn’s Brooklin –a near real-time data streaming framework–enabled seamless data streaming through Kafka messages.
With that in mind, it’s not uncommon for a company to grow their own data scientists from adjacent expertises: analysts, database experts, people with coding experience in Java or C/C++ are often trained in algorithms and models to become data scientists. Let’s give a rundown of the necessary skills and what they entail. Statistics and maths.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. Java can be used to build APIs and move them to destinations in the appropriate logistics of data landscapes.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! Notably, they’ve added experimental support for Java 11 (finally) and virtual tables.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! Notably, they’ve added experimental support for Java 11 (finally) and virtual tables.
Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go. Apache Kafka Amazon MSK and Kafka Under the Hood Apache Kafka is an open-source streaming platform. This learning path covers the basics of Java, including syntax, functions, and modules.
Hadoop common provides all Java libraries, utilities, OS level abstraction, necessary Java files and script to run Hadoop, while Hadoop YARN is a framework for job scheduling and cluster resource management. Busboy, a proprietary framework of Skybox makes use of built-in code from java based MapReduce framework. >
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka.
It uses Cognito federated identities in conjunction with AWS IoT to create a client certificate and private key and store it in a local Java Keystore. The app will use the certificate and private key saved in the local java Keystore for future connections. We had selected Amazon MSK to run Kafka and Spark.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Kafka: Kafka is a top engineering tool highly valued by big data experts. Machine learning engineer: A machine learning engineer is an engineer who uses programming languages like Python, Java, Scala, etc.
Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering. Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases.
The new databases that have emerged during this time have adopted names such as NoSQL and NewSQL, emphasizing that good old SQL databases fell short when it came to meeting the new demands. RocksDB offers a key-value API, available for C++, C and Java. Apache Cassandra is one of the most popular NoSQL databases.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. Equip yourself with the experience and know-how of Hadoop, Spark, and Kafka, and get some hands-on experience in AWS data engineer skills, Azure, or Google Cloud Platform. Step 4 - Who Can Become a Data Engineer?
Pig hadoop and Hive hadoop have a similar goal- they are tools that ease the complexity of writing complex java MapReduce programs. PIG was developed as an abstraction to avoid the complicated syntax of Java programming for MapReduce. YES, when you extend it with Java User Defined Functions.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential. csv') data_excel = pd.read_excel('data2.xlsx')
First publicly introduced in 2010, Elasticsearch is an advanced, open-source search and analytics engine that also functions as a NoSQL database. It is developed in Java and built upon the highly reputable Apache Lucene library. What is Elasticsearch? The engine’s core strength lies in its high-speed, near real-time searches.
Table of Contents Apache Pig Apache Hive Apache Spark Apache Kafka Presto HBase Each of these innovations on Hadoop are packaged either in a cloud service or into a distribution and it is up to the organization to figure out the best way to integrate these hadoop components which can help them solve the business use case at hand.
You must have good knowledge of the SQL and NoSQL database systems. NoSQL databases are also gaining popularity owing to the additional capabilities offered by such databases. You shall have advanced programming skills in either programming languages, such as Python, R, Java, C++, C#, and others.
Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. Java, Android Studio, and SQLite are the tools used to create an app that helps commuters to book train tickets directly from their mobile devices. cvtColor(image, cv2.COLOR_BGR2GRAY) findContours(thresh, cv2.RETR_TREE,
As open source technologies gain popularity at a rapid pace, professionals who can upgrade their skillset by learning fresh technologies like Hadoop, Spark, NoSQL, etc. Assume that you are a Java Developer and suddenly your company hops to join the big data bandwagon and requires professionals with Java+Hadoop experience.
It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programming languages: Java, Python, and Go. CMAK Source: Github CMAK stands for Cluster Manager for Apache Kafka , previously known as Kafka Manager, is a tool for managing Apache Kafka clusters.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing.
Decomposer - Contains large matrix decomposition algorithms implemented in Java. Kafka - Publish-Subscribe messaging system, that unifies online and offline processing by providing a method for parallel load into Hadoop. 70% of all Hadoop data deployments at LinkedIn employ key-value access using Voldemort.
Hadoop ecosystem has a very desirable ability to blend with popular programming and scripting platforms such as SQL, Java , Python, and the like which makes migration projects easier to execute. Tools/Tech stack used: The tools and technologies used for such weblog trend analysis using Apache Hadoop are NoSql, MapReduce, and Hive.
Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Hadoop, MongoDB, and Kafka are popular Big Data tools and technologies a data engineer needs to be familiar with. They must be skilled at creating solutions that use the Azure Cosmos DB for NoSQL API.
A Java class gets generated during the Sqoop import process. The source code of the Java class is provided and can be utilized by the developer to make any changes to the MapReduce processing of the data. HBase is a NoSQL database, but the data can be dumped into HBase as well. YARN also offers fault tolerance.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
Hadoop Framework works on the following two core components- 1)HDFS – Hadoop Distributed File System is the java based file system for scalable and reliable storage of large datasets. 2)Hadoop MapReduce-This is a java based programming paradigm of the Hadoop framework that provides scalability across various Hadoop clusters.
Deepanshu’s skills include SQL, data engineering, Apache Spark, ETL, pipelining, Python, and NoSQL, and he has worked on all three major cloud platforms (Google Cloud Platform, Azure, and AWS). Beyond his work at Google, Deepanshu also mentors others on career and interview advice at topmate.io/deepanshu. deepanshu.
They get used in NoSQL databases like Redis, MongoDB, data warehousing. It supports PHP, GO, Java, Node,NET, Python, and Ruby. Use cases for EBS are Software development and testing, NoSQL databases, organization-wide application. These instances use their local storage to store data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content