This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. That is because relationaldatabases are a rich source of events. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. What we’ll cover.
Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. Microservices, Apache Kafka, and Domain-Driven Design (DDD) covers this in more detail. Example: Severstal.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relationaldatabase might not be enough. Building an indexing pipeline at scale with Kafka Connect.
How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? Can you start by describing what Flink is and how the project got started? What are some of the primary ways that Flink is used? How is Flink architected?
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. gradlew composeUp. The KSQL pipeline flow.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. Data engineers who previously worked only with relationaldatabase management systems and SQL queries need training to take advantage of Hadoop. Just for reference, Spark Streaming and Kafka combo is used by.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
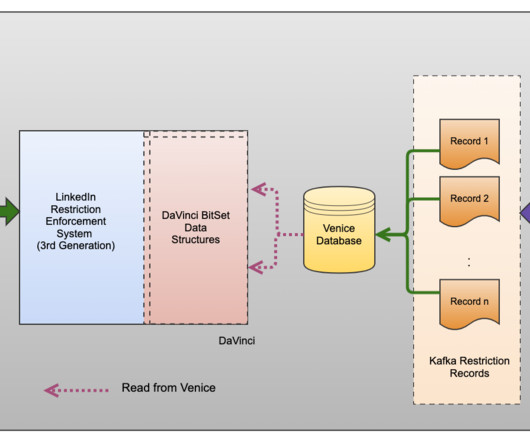
At the heart of this system was a reliance on a relationaldatabase, Oracle, which served as the repository for all member restrictions data. Figure 2: Relationaldatabase schema We adopted a pragmatic and scalable approach by distributing member restrictions across different Oracle tables.
If you are a database administrator or developer, you can start writing queries right-away using Apache Phoenix without having to wrangle Java code. . To store and access data in the operational database, you can do one of the following: Use native Apache HBase client APIs to interact with data in HBase: Use the HBase APIs for Java.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. Data Engineers are skilled professionals who lay the foundation of databases and architecture. They achieve this through a programming language such as Java or C++.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
Knowing SQL means you are familiar with the different relationaldatabases available, their functions, and the syntax they use. For example, you can learn about how JSONs are integral to non-relationaldatabases – especially data schemas, and how to write queries using JSON. Rely on the real information to guide you.
It frequently also means moving operational data from native mainframe databases to modern relationaldatabases. Typically, a mainframe to cloud migration includes re-factoring code to a modern object-oriented language such as Java or C# and moving to a modern relationaldatabase.
Logstash offers a JDBC input plugin that polls a relationaldatabase, like PostgreSQL or MySQL, for inserts and updates periodically. Logstash offers a JDBC input plugin that polls a relationaldatabase, like PostgreSQL or MySQL, for inserts and updates periodically.
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. Java can be used to build APIs and move them to destinations in the appropriate logistics of data landscapes.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. batchSize- A single Java object (batchSize) represents the number of Python objects.
Pig hadoop and Hive hadoop have a similar goal- they are tools that ease the complexity of writing complex java MapReduce programs. PIG was developed as an abstraction to avoid the complicated syntax of Java programming for MapReduce. YES, when you extend it with Java User Defined Functions.
The data flow is somewhat inverted: every photo or piece of text that enters Booking.com is broadcasted through the companys system for general use via Kafka. We then persist the results in a relational DB (the specific DB varies per use case) for each piece ofcontent. We use Apache Flink to implement our streaming pipeline.
Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology. To be an Azure Data Engineer, you must have a working knowledge of SQL (Structured Query Language), which is used to extract and manipulate data from relationaldatabases.
It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programming languages: Java, Python, and Go. Presto allows you to query data stored in Hive, Cassandra, relationaldatabases, and even bespoke data storage.
Experience with data warehousing and ETL concepts, as well as programming languages such as Python, SQL, and Java, is required. Data engineers must be well-versed in programming languages such as Python, Java, and Scala. The most common data storage methods are relational and non-relationaldatabases.
Let’s start with a quick summary of both stream processing and RTA databases. Streams”, as opposed to tables in a relationaldatabase context, are the first-class citizens in stream processing. It was developed by the Apache Software Foundation and is written in Java and Scala. So do you need just one? Stateful Or Not?
For streaming technology, Netflix utilizes a variety of options such as Kafka, SQS, Kinesis, and even Netflix specific streaming solutions such as Keystone. Supporting RelationalDatabases. There are services at Netflix that use RDBMS kind of databases such as MySQL or PostgreSQL via AWS RDS. Writing events to any output.
For streaming technology, Netflix utilizes a variety of options such as Kafka, SQS, Kinesis, and even Netflix specific streaming solutions such as Keystone. Supporting RelationalDatabases. There are services at Netflix that use RDBMS kind of databases such as MySQL or PostgreSQL via AWS RDS. Writing events to any output.
Sqoop is compatible with all JDBC compatible databases. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Apache Sqoop uses Hadoop MapReduce to get data from relationaldatabases and stores it on HDFS. A Java class gets generated during the Sqoop import process.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. You should be thorough with technicalities related to relational and non-relationaldatabases, Data security, ETL (extract, transform, and load) systems, Data storage, automation and scripting, big data tools, and machine learning.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing.
Relationaldatabases, nonrelational databases, data streams, and file stores are examples of data systems. Programming languages like Python, Java, or Scala require a solid understanding of data engineers. One of the most popular ways to store data is in databases, both relational and non-relational.
Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Relational and non-relationaldatabases are among the most common data storage methods. Learning SQL is essential to comprehend the database and its structures.
First publicly introduced in 2010, Elasticsearch is an advanced, open-source search and analytics engine that also functions as a NoSQL database. It is developed in Java and built upon the highly reputable Apache Lucene library. Fields in these documents are defined and governed by mappings akin to a schema in a relationaldatabase.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. These are the most organized forms of data, often originating from relationaldatabases and tables where the structure is clearly defined.
Applicants must be supportive and in favour of various open source tools along with strong knowledge in Java. Hiring managers can ask as simple questions as tell me about the Hadoop ecosystem or can ask code review questions or situation questions relating to a big data problem.
This failure of relationaldatabase management systems triggered organizations to move their data from RDBMS to Hadoop. Data migration from legacy systems to the cloud is a major use case in organizations that have been into relationaldatabases.
The distributed execution engine in the Spark core provides APIs in Java, Python, and Scala for constructing distributed ETL applications. For input streams receiving data through networks such as Kafka, Flume, and others, the default persistence level setting is configured to achieve data replication on two nodes to achieve fault tolerance.
Proficiency in data ingestion, including the ability to import and export data between your cluster and external relationaldatabase management systems and ingest real-time and near-real-time (NRT) streaming data into HDFS. 2-5 years of experience in Software Engineering/Data Management if you seek a senior-level position.
Amazon Redshift Logs: Amazon Redshift logs collect and record information concerning database connections, any changes to user definitions, and activity. The logs can be used for security monitoring and troubleshooting any database-related issues. The log files may also be queried from a specific database table.
It backs up storage in a routine fashion without the hassle of Database administrators interfering. RDS (Amazon RelationalDatabase System) is the traditional relationaldatabase that provides scalability and cost-effective solutions for storing data. It supports PHP, GO, Java, Node,NET, Python, and Ruby.
Without a solid understanding of SQL, you cannot administer an RDBMS (relationaldatabase management). Database Management: Understanding how to create and operate a data warehouse is a crucial skill. For this reason, learn an enterprise language, such as Java or C#. The essential knowledge base for Data Engineers is SQL.
Apache Hadoop is an open-source Java-based framework that relies on parallel processing and distributed storage for analyzing massive datasets. Streaming analytics became possible with the introduction of Apache Kafka , Apache Spark , Apache Storm , Apache Flink , and other tools to build real-time data pipelines. What is Hadoop?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content