This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Kafka ships with Kafka Streams, a powerful yet lightweight client library for Java and Scala to implement highly scalable and elastic applications and microservices that process and analyze data […].
When it was first created, Apache Kafka ® had a client API for just Scala and Java. Since then, the Kafka client API has been developed for many other programming languages which enables you to pick the language you want. At Confluent, we have an engineering team dedicated to the development of these Kafka clients.
Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. 6 Spark streaming is a standalone framework.
How cool would it be to build your own burglar alarm system that can alert you before the actual event takes place simply by using a few network-connected cameras and analyzing the camera images with Apache Kafka ® , Kafka Streams, and TensorFlow? Uploading your images into Kafka. Setting up your burglar alarm.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
This typically involved a lot of coding with Java, Scala or similar technologies. The DataFlow platform has established a leading position in the data streaming market by unlocking the combined value and synergies of Apache NiFi, Apache Kafka and Apache Flink.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
The term Scala originated from “Scalable language” and it means that Scala grows with you. In recent times, Scala has attracted developers because it has enabled them to deliver things faster with fewer codes. Developers are now much more interested in having Scala training to excel in the big data field.
It offers a slick user interface for writing SQL queries to run against real-time data streams in Apache Kafka or Apache Flink. They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . SQL Stream Builder continuously runs SQL via Flink.
you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with Here what Databricks brought this year: Spark 4.0 — (1) PySpark erases the differences with the Scala version, creating a first class experience for Python users. (2) Databricks sells a toolbox, you don't buy any UX. 3) Spark 4.0
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. It’s also worth noting that even those with Java skills will often prefer to work with SQL – if for no other reason than to share the workload with others in their organization that only know SQL.
How we use Apache Kafka and the Confluent Platform. Apache Kafka ® is the central data hub of our company. At TokenAnalyst, we’re using Kafka for ingestion of blockchain data—which is directly pushed from our cluster of Bitcoin and Ethereum nodes—to different streams of transformation and loading processes.
How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? Can you start by describing what Flink is and how the project got started? What are some of the primary ways that Flink is used? How is Flink architected?
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Introduction Apache Kafka is a well-known event streaming platform used in many organizations worldwide. The focus of this article is to provide a better understanding of how Kafka works under the hood to better design and tune your client applications. Environment Setup First, we want to have a Kafka Cluster up and running.
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
The developers must understand lower-level languages like Java and Scala and be familiar with the streaming APIs. Streamings Messaging , powered by Apache Kafka, buffers and scales massive volumes of data streams for streaming analytics.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
As a big data architect or a big data developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Rabbit MQ vs. Kafka - Which one is a better message broker? Table of Contents Kafka vs. RabbitMQ - An Overview What is RabbitMQ? What is Kafka?
A closer look at the ingredients needed for ultimate stability This is part of a series of posts on Kafka. See Ranking Websites in Real-time with Apache Kafka’s Streams API for the first post in the series. Remora is a small application to track the monitoring of Kafka. Some use cloud infrastructure such as AWS Kinesis or SQS.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Real-time joins in event-driven microservices As discussed in my previous blog post , Kafka is one of the key components of our event-driven microservice architecture in Zalando’s Smart Product Platform. This is where Kafka API comes in handy! We use it for sequencing events and building an aggregated view of data hierarchies.
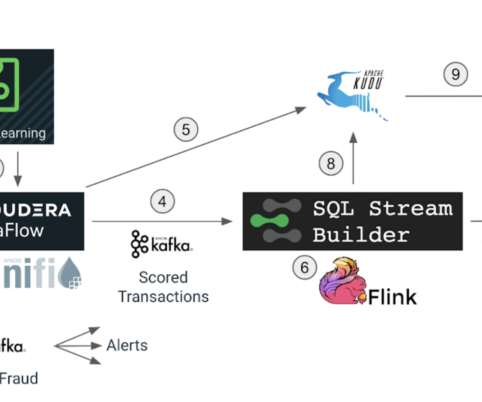
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. They have to know Java to go deep in Hadoop coding and effectively use features available via Java APIs. Just for reference, Spark Streaming and Kafka combo is used by. Hadoop vs Spark differences summarized.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
We discussed how Cloudera Stream Processing (CSP) with Apache Kafka and Apache Flink could be used to process this data in real time and at scale. If the fraud score is above a certain threshold, NiFi immediately routes the transaction to a Kafka topic that is subscribed by notification systems that will trigger the appropriate actions.
Python, Java, and Scala knowledge are essential for Apache Spark developers. Various high-level programming languages, including Python, Java , R, and Scala, can be used with Spark, so you must be proficient with at least one or two of them. Creating Spark/Scala jobs to aggregate and transform data.
Use Snowflake’s native Kafka Connector to configure Kafka topics into Snowflake tables. B) Transformations – Feature engineering into business vault Transformations can be supported in SQL, Python, Java, Scala—choose your poison!
Spark is most notably easy to use, and it’s easy to write applications in Java, Scala, Python, and R. This framework works in conjunction with other frameworks, using Apache Kafka for messaging and Hadoop YARN for fault tolerance, security, and management of resources.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? Table of Contents What is Spark streaming?
However, as real-time queries are typically executed by those with unique skills like Scala or Java, there could be a mismatch between expertise and increasing workloads. If you want to learn more about SQL Stream Builder , download our Tech Brief or the datasheet. .
We have delivered an event streaming platform which gives strong guarantees on data quality, using Apache Kafka ® and Protocol Buffers. Because it builds on top of Apache Kafka we decided to call it Franz. We then proceeded to conduct an evaluation of these formats to determine what would work best for transmission of data over Kafka.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. Java can be used to build APIs and move them to destinations in the appropriate logistics of data landscapes.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. They achieve this through a programming language such as Java or C++. It is considered the most commonly used and most efficient coding language for a Data engineer and Java, Perl, or C/ C++.
With that in mind, it’s not uncommon for a company to grow their own data scientists from adjacent expertises: analysts, database experts, people with coding experience in Java or C/C++ are often trained in algorithms and models to become data scientists. Let’s give a rundown of the necessary skills and what they entail. Statistics and maths.
With the help of python, Java, and Ruby, along with AI and ML, you can create any application. Oracle Java SE Oracle offers several certification courses at professional, master, and expert levels. This will require a professional-level certification, typically requiring an OCP Java certification.
In this article we will see: Why it’s powerful and how it helps democratize Stream Processing and Analytics Understand basic concepts around Streaming and Flink SQL Setup Kafka and Flink Clusters and get started with Flink SQL Understand different kinds of Processing Operators and Functions Different ways of running Flink SQL Queries 1.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Notably, they’ve added experimental support for Java 11 (finally) and virtual tables. Here’s what’s happening in data engineering right now. Cassandra 4.0
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content