This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Can you describe your experiences with Kafka? What are the operational challenges that you have had to overcome while working with Kafka? When is Kafka the wrong choice?
We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined Data Pipeline appeared first on Analytics Vidhya. IT industries rely heavily on real-time insights derived from streaming data sources.
Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a message broker application and a logging service that is distributed, segmented, and […] The post A Detailed Guide of Interview Questions on Apache Kafka appeared first on Analytics Vidhya.
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
The full inventory of three online Kafka Summits in 2021 is now complete. Kafka Summit Americas wrapped just yesterday. Being a part of the event team and the Program Committee, […].
Apache Kafka 3.7 introduces updates to the Consumer rebalance protocol, an official Apache Kafka Docker image, JBOD support in Kraft-based clusters, and more!
Kafka Streams is an abstraction over Apache Kafka® producers and consumers that lets you forget about low-level details and focus on processing your Kafka data. You could of course write […].
Apache Kafka 3.8 adds 17 new KIPs (13 for Core, 3 for Streams & 1 for Connect). Highlights include 2 new Docker images, the ability to set task assignors, and more!
At the heart of Apache Kafka® sits the log—a simple data structure that uses sequential operations that work symbiotically with the underlying hardware. Efficient disk buffering and CPU cache usage, […].
I’m pleased to announce the release of Apache Kafka 3.0 on behalf of the Apache Kafka® community. Apache Kafka 3.0 is a major release in more ways than one. Apache […].
I’m proud to announce the release of Apache Kafka 3.2.0 on behalf of the Apache Kafka® community. release contains many new features and improvements. This blog will highlight […].
Apache Kafka® is an event streaming platform used by more than 30% of the Fortune 500 today. There are numerous features of Kafka that make it the de-facto standard for […].
Major milestone release Apache Kafka 4.0 removes ZooKeeper entirely, provides early access to Queues for Kafka, and enables faster rebalances, in addition to many other new KIPs.
Today I'll focus on these differences for Amazon Kinesis service and Apache Kafka ecosystem. The managed cloud services often share the same fundamentals as their Open alternatives. However, there is always something different.
Managing Apache Kafka® clusters can be tricky sometimes. To solve this problem, Confluent Control Center helps you easily manage and monitor your clusters and interact with other Confluent components, such […].
Apache Kafka® is at the heart of the data transportation layer at Pinterest. The amount of data that runs through Kafka has constantly grown over the years. This growth sometimes […].
I’m proud to announce the release of Apache Kafka 2.8.0 on behalf of the Apache Kafka® community. release contains many new features and improvements. This blog post highlights […].
Dive into Kafka internals with a four-part series examining client requests and brokers. Part 1 covers what a producer does to prepare raw event data for the broker.
Each one of the more than 50 tutorials for Apache Kafka® on Confluent Developer answers a question that you might ask a knowledgeable friend or colleague about Kafka and its […].
Whether you’re a seasoned Apache Kafka® developer or just getting started you’re likely to hit a snag at some point or another—either in configuring and understanding your clients or setting […].
Soon, Apache Kafka® will no longer need ZooKeeper! With KIP-500, Kafka will include its own built-in consensus layer, removing the ZooKeeper dependency altogether. The next big milestone in this effort […].
You can limit the max throughput for Apache Spark Structured Streaming jobs for popular data sources such as Apache Kafka, Delta Lake, or raw files. Have you known that you can also control the lower limit, at least for Apache Kafka? I bet you know it already.
As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. Now we are able to ingest our data in near real time directly from Kafka topics to a Snowflake table, drastically reducing the cost of ingestion and improving our SLA from 15 minutes to within 60 seconds.
Extensive out-of-the-box functionality, a large user community, and up-to-date, cloud-native features make Spring and its libraries a strong option for anchoring your Apache Kafka® and Confluent Cloud based microservices architecture. […].
Explore GitHub Actions for your Kafka CI/CD pipeline, automate Schema Registry, and transform the development and testing of Kafka client applications.
Introducing fully managed Apache Kafka® + Flink for the most robust, cloud-native data streaming platform with stream processing, integration, and streaming analytics in one.
One of the great things about using an Apache Kafka® based architecture is that it naturally decouples systems and allows you to use the best tool for the job. While […].
Apache Kafka 3.3 includes KRaft mode, improves partition scalability and resiliency while simplifying Kafka deployment, as well as updates to Kafka Streams, Connect, and more.
Change data capture is a software design pattern used to capture changes to data and take corresponding action based on that change. The change to data is usually one of read, update or delete. The corresponding action usually is supposed to occur in another system in response to the change that was made in the source system.
ksqlDB use case: see how apps can use ksqlDB to ingest, filter, enrich, aggregate, and query data directly with Kafka—no complex architectures or data stores needed.
It’s not difficult to get started with Apache Kafka®. If you are new to Kafka, […]. Learning resources can be found all over the internet, especially on the Confluent Developer site.
Running Kafka is costly, but Confluent has created a far more efficient product to lower your costs. Join the Cost Savings challenge to see for yourself.
In the final article of this four-part series on Kafka producer and consumer internals, observe the inner workings of brokers as they attempt to serve data up to consumers.
Major improvements to the Kafka consumer, Streams, and ksqlDB for incremental cooperative rebalancing while maintaining at-least-once and exactly-once guarantees.
Kafka-on-Windows tutorials are everywhere, but most run Kafka directly on Windows. Here's how to use Kafka on Windows in a Linux environment backed by WSL 2, maximizing performance and stability
Welcome Pythonistas to the streaming data world centered around Apache Kafka®! If you’re using Python and ready to get hands-on with Kafka, then you’re in the right place. This blog […].
This blog post shows how transactional machine learning (TML) integrates data streams with automated machine learning (AutoML), using Apache Kafka® as the data backbone, to create a frictionless machine learning […].
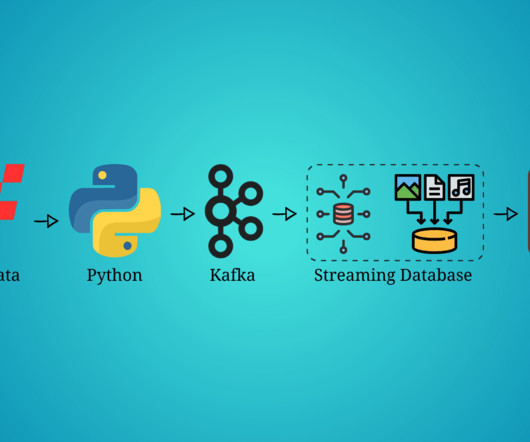
Build a streaming data pipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
At DoorDash, we rely on message queue systems based on Kafka to handle billions of real-time events. We will delve here into how we set up multi-tenancy with a messaging queue system based on Kafka. In Kafka, a test tenant processing production event can cause data inconsistencies, including outages and other incidents.
Confluent Hackathon ‘22: Using Apache Kafka a Raspberry Pi, and a camera, Simon Aubury builds a detection and monitoring system to better understand wildlife population trends over time.
There are two main consumer group memberships in Apache Kafka®. Here’s how static and dynamic consumer groups work, how they affect rebalancing, and which to choose for your application.
This article focuses on how we … The post Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot appeared first on Uber Engineering Blog. With this new ability came new challenges that needed to be solved at Uber, such as systems for ad auctions, bidding, attribution, reporting, and more.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content