This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
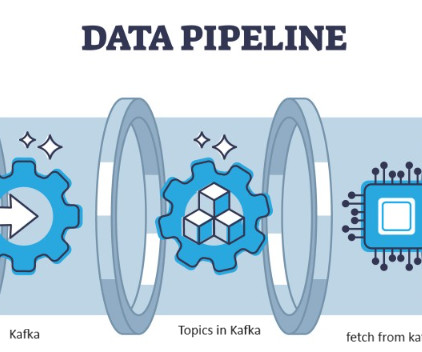
We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined Data Pipeline appeared first on Analytics Vidhya. Handling and processing the streaming data is the hardest work for Data Analysis.
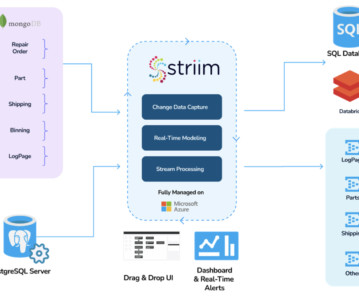
Together, MongoDB and Apache Kafka ® make up the heart of many modern data architectures today. Integrating Kafka with external systems like MongoDB is best done though the use of Kafka Connect. The official MongoDB Connector for Apache Kafka is developed and supported by MongoDB engineers.
Since the MongoDB Atlas source and sink became available in Confluent Cloud, we’ve received many questions around how to set up these connectors in a secure environment. By default, MongoDB […].
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. BigQuery, Amazon Redshift, and MongoDB Atlas) and caches (e.g.,
I’m excited to announce that we’re partnering with Google Cloud to make Confluent Cloud, our fully managed offering of Apache Kafka ® , available as a native offering on Google Cloud Platform (GCP). Confluent’s founders didn’t just write the original code of Apache Kafka, we also ran it as a service at massive scale.
MongoDB has grown from a basic JSON key-value store to one of the most popular NoSQL database solutions in use today. These attributes have caused MongoDB to be widely adopted especially alongside JavaScript web applications. These attributes have caused MongoDB to be widely adopted especially alongside JavaScript web applications.
Change Data Capture (CDC) is an excellent way to introduce streaming analytics into your existing database, and using Debezium enables you to send your change data through Apache Kafka®. Although […].
Over the past few years, MongoDB has become a popular choice for NoSQL Databases. Catering to real-time processing requirements, MongoDB introduced a powerful feature to track data […] With the rise of modern data tools, real-time data processing is no longer a dream.
We are excited to announce the preview release of the fully managed MongoDB Atlas source and sink connectors in Confluent Cloud, our fully managed event streaming service based on Apache […].
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
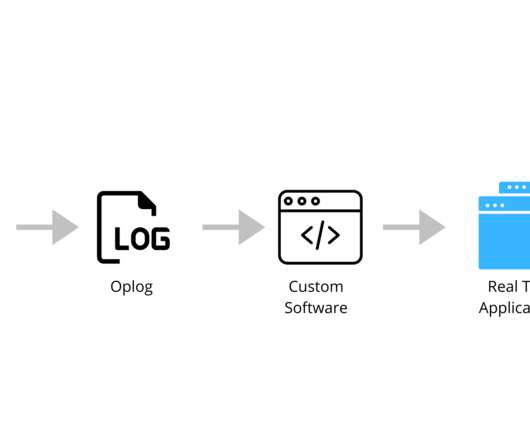
According to over 40,000 developers, MongoDB is the most popular NOSQL database in use right now. From a developer perspective, MongoDB is a great solution for supporting modern data applications. This blog post will look at three of them: tailing MongoDB with an oplog, using MongoDB change streams, and using a Kafka connector.
In the course of implementing the Rockset connector to MongoDB , we did a fair amount of research on the MongoDB user experience, both online and through user interviews. Sharding What is MongoDB Sharding and the Best Practices? This was a recurring theme we heard when speaking with MongoDB users.
Here in part 4 of the Spring for Apache Kafka Deep Dive blog series, we will cover: Common event streaming topology patterns supported in Spring Cloud Data Flow. Create and manage event streaming pipelines, including a Kafka Streams application using Spring Cloud Data Flow.
Most organisations maintain fleets, a collection of vehicles put to use for day-to-day operations. Telcos use a variety of vehicles including cars, vans, and trucks for service, delivery, and maintenance. […].
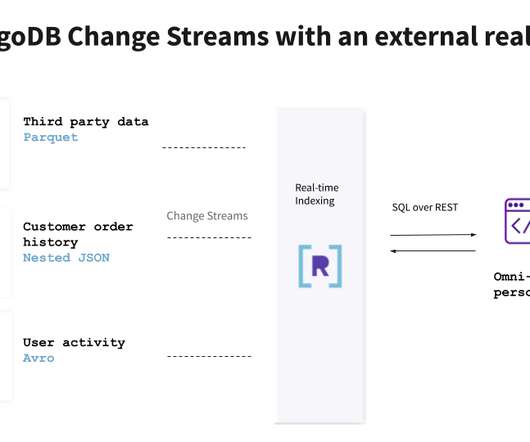
MongoDB.live took place last week, and Rockset had the opportunity to participate alongside members of the MongoDB community and share about our work to make MongoDB data accessible via real-time external indexing. We would be responsible for building and maintaining pipelines from these sources to MongoDB.
The data sources available include: users (MongoDB): Core customer data such as name, age, gender, address. online_orders (MongoDB): Online purchase data including product details and delivery addresses. instore_orders (MongoDB): In-store purchase data again including product details and store location. SELECT users.id
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Email hosts@dataengineeringpodcast.com ) with your story. Email hosts@dataengineeringpodcast.com ) with your story.
Imagine you’ve got a stream of data; it’s not “big data,” but it’s certainly a lot. Within the data, you’ve got some bits you’re interested in, and of those bits, […].
Connect any database to MongoDB using Confluent's cloud-native data streaming platform. Modernize any database, build streaming data pipelines, and empower real-time data in minutes.
Today, Confluent is announcing the general availability (GA) of the fully managed MongoDB Atlas Source and MongoDB Atlas Sink Connectors within Confluent Cloud. Now, with just a few simple clicks, […].
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
Data Engineering Tools Data engineers need to be comfortable using essential tools for data pipeline management and workflow orchestration, including Apache Kafka, Apache Spark, Airflow, Dagster, dbt, and many more. Get familiar with data warehouses, data lakes, and data lakehouses, including MongoDB , Cassandra, BigQuery, Redshift and more.
In Data Science projects, we distinguish between descriptive analytics and statistical models running in production. Overall, these can be seen as one process. You start with analyzing historical data to […].
Contact Info Ajay @acoustik on Twitter LinkedIn Mike LinkedIn Website @michaelfreedman on Twitter Timescale Website Documentation Careers timescaledb on GitHub @timescaledb on Twitter Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
How did the constraint of supporting the Kafka API influence your implementation strategy for transaction semantics? How did the constraint of supporting the Kafka API influence your implementation strategy for transaction semantics? What are the elements of streaming systems that make atomic transactions a complex problem?
Links Timescale PostGreSQL Citus Timescale Design Blog Post MIT NYU Stanford SDN Princeton Machine Data Timeseries Data List of Timeseries Databases NoSQL Online Transaction Processing (OLTP) Object Relational Mapper (ORM) Grafana Tableau Kafka When Boring Is Awesome PostGreSQL RDS Google Cloud SQL Azure DB Docker Continuous Aggregates Streaming Replication (..)
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Links Molecula Pilosa Podcast Episode The Social Dilemma Feature Store Cassandra Elasticsearch Podcast Episode Druid MongoDB SwimOS Podcast Episode KafkaKafka (..)
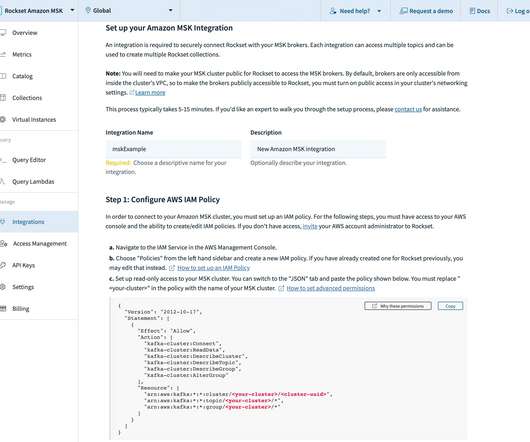
Rockset’s native connector for Amazon Managed Streaming for Apache Kafka (MSK) makes it simpler and faster to ingest streaming data for real-time analytics. Amazon MSK is a fully managed AWS service that gives users the ability to build and run applications using Apache Kafka.
In Part One , we discussed how to first identify slow queries on MongoDB using the database profiler, and then investigated what the strategies the database took doing during the execution of those queries to understand why our queries were taking the time and resources that they were taking.
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast Summary Modern applications frequently require access to real-time data, but building and maintaining the systems that make that possible is a complex and time consuming endeavor.
We’re introducing a new Rockset Integration for Apache Kafka that offers native support for Confluent Cloud and Apache Kafka, making it simpler and faster to ingest streaming data for real-time analytics. With the Kafka Integration, users no longer need to build, deploy or operate any infrastructure component on the Kafka side.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Hevo]([link] Are you sick of repetitive, time-consuming ELT work?
It points to best practices for anyone writing Kafka Connect connectors. In a nutshell, the document states that sources and sinks are verified as Gold if they’re functionally equivalent to Kafka Connect connectors. Over the years, we’ve since seen wide adoption of Kafka Connect.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Email hosts@dataengineeringpodcast.com ) with your story. Email hosts@dataengineeringpodcast.com ) with your story.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
There are a variety of big data processing technologies available, including Apache Hadoop, Apache Spark, and MongoDB. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase. In general, Hadoop and Spark are good choices for batch processing, while Kafka and Storm are better suited for streaming applications.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
Machine learning on real-time data is a powerful combination because you gain direct insights into your data, can make powerful decisions, and consequently improve your business processes and outcomes. It […].
Users often have to grapple with intricate, low-level Kafka elements like topics, brokers, partitions, taking focus away from more strategic tasks. AWS MSK : An Apache Kafka-compatible managed streaming platform that also allows users to access other AWS services directly. Frequently Asked Questions What is Apache Kafka?
The data architecture is based on open source standards Pentaho and is used for managing, preparing and integrating data that runs through their environments including Cloudera Hadoop Distribution , HP Vertica, Flume and Kafka. Source : [link] How Hadoop helps Experian crunch credit reports. Source : [link] ) Bringing Hadoop to the mainframe.
Understanding of Big Data technologies such as Hadoop, Spark, and Kafka. Familiarity with database technologies such as MySQL, Oracle, and MongoDB. Knowledge of Hadoop, Spark, and Kafka. Familiarity with database technologies such as MySQL, Oracle, and MongoDB. How Much Do Data Engineers Make?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content