This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
release of PostGreSQL had on the design of the project? release of PostGreSQL had on the design of the project? Can you start by explaining what Timescale is and how the project got started? The landscape of time series databases is extensive and oftentimes difficult to navigate. What impact has the 10.0 What impact has the 10.0
How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product? How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product? Have you been able to leverage some of the native improvements to simplify your implementation?
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast Summary Modern applications frequently require access to real-time data, but building and maintaining the systems that make that possible is a complex and time consuming endeavor.
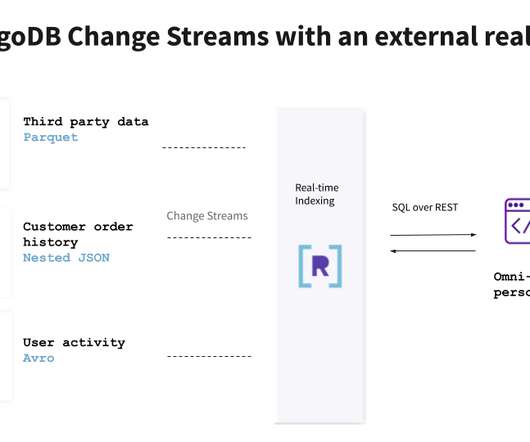
MongoDB.live took place last week, and Rockset had the opportunity to participate alongside members of the MongoDB community and share about our work to make MongoDB data accessible via real-time external indexing. We would be responsible for building and maintaining pipelines from these sources to MongoDB.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
If you’d like to join our first cohort of Striim Developers, you can sign up here. If you’d like to get an overview from a data streaming expert first, request a demo here.
Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. PostgreSQL, MySQL, SQL Server, and even Oracle are popular choices, but there are many others that will work fine.
Debezium uses connectors like PostgreSQL, SQL, MySQL, Oracle, MongoDB, and more for respective databases to stream such changes. Debezium is an open-source, distributed system that can convert real-time changes of existing databases into event streams so that various applications can consume and respond immediately.
Apache Kafka has made acquiring real-time data more mainstream, but only a small sliver are turning batch analytics, run nightly, into real-time analytical dashboards with alerts and automatic anomaly detection. But until this release, all these data sources involved indexing the incoming raw data on a record by record basis.
Introduction Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time analytics is a challenge for many teams. Logstash offers a JDBC input plugin that polls a relational database, like PostgreSQL or MySQL, for inserts and updates periodically.
Be it PostgreSQL, MySQL, MongoDB, or Cassandra, Python ensures seamless interactions. Use Case: Storing data with PostgreSQL (example) import psycopg2 conn = psycopg2.connect(dbname="mydb", Use Case: Storing data with PostgreSQL (example) import psycopg2 conn = psycopg2.connect(dbname="mydb",
Rockset works well with a wide variety of data sources, including streams from databases and data lakes including MongoDB , PostgreSQL , Apache Kafka , Amazon S3 , GCS (Google Cloud Service) , MySQL , and of course DynamoDB. Results, even for complex queries, would be returned in milliseconds.
For instance, let’s say you have streaming data coming in from Kafka or Kinesis. DynamoDB or MongoDB), and relational databases (e.g. PostgreSQL or MySQL). For high velocity data, most commonly coming from data streams, you can roll it up at write-time. S3 or GCS), NoSQL databases (e.g.
It works with existing streaming systems like Apache Kafka, Amazon Kinesis, and Azure Events Hubs, making it easier than ever to build a real-time data pipeline. We’ve already built CDC-based data connectors for many common sources: DynamoDB , MongoDB , and more. This method offers a few enormous advantages over batch updates.
Versatile Source Connectivity: Striim offers a wide array of streaming source connectors including databases like Oracle, Microsoft SQL Server, MongoDB, PostgreSQL, IoT streams, Kafka, and many more.
In this respect, it is very similar to transactional databases like Oracle, PostgreSQL, etc. For example, an OLTP system like PostgreSQL has a database server; updates arrive at the database server, which then writes it to the LOG. Typical examples of transactional systems are Oracle, Spanner, PostgreSQL, etc.
Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing. Implement ETL & Data Pipelines with Bash, Airflow & Kafka; architect, populate, deploy Data Warehouses; create BI reports & interactive dashboards.
Follow Zach on LinkedIn 8) Shashank Mishra Data Engineer III at Expedia Group Shashank is a data engineer with over six years of experience working in service and product companies, having solved data mysteries across aviation, pharmaceutical, fintech, and telecom companies and designed scalable and optimized data pipelines to handle petabytes of data (..)
It has direct connectors for a number of primary data stores, including DynamoDB, MongoDB, Kafka, and many relational databases. Most relational databases, like PostgreSQL and MySQL, are row-based databases. In thinking about data layout, we'll contrast two approaches: row-based vs. column-based.
E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server. E.g. Redis, MongoDB, Cassandra, HBase , Neo4j, CouchDB What is data modeling? Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers How is a data warehouse different from an operational database?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content