This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
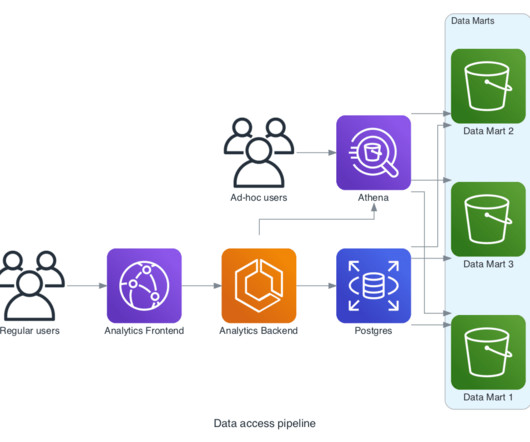
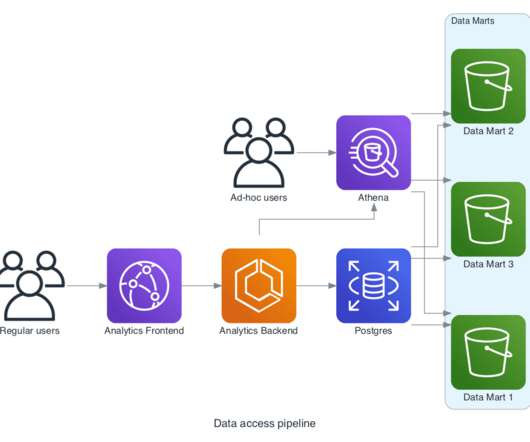
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
__init__ Episode Kubernetes Operator ScalaKafka Abstract Syntax Tree Language Server Protocol Amazon Deequ dbt Tecton Podcast Episode Informatica The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
Apache HBase , a noSQL database on top of HDFS, is designed to store huge tables, with millions of columns and billions of rows. Alternatively, you can opt for Apache Cassandra — one more noSQL database in the family. Just for reference, Spark Streaming and Kafka combo is used by. Some components of the Hadoop ecosystem.
KafkaKafka is an open-source processing software platform. The applications developed by Kafka can help a data engineer discover and apply trends and react to user needs. You can refer to the following links to learn about Kafka: Apache Kafka Training by KnowledgeHut 6.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. KafkaKafka is one of the most desired open-source messaging and streaming systems that allows you to publish, distribute, and consume data streams.
They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase. They also make use of ETL tools, messaging systems like Kafka, and Big Data Tool kits such as SparkML and Mahout.
Data engineers are well-versed in Java, Scala, and C++, since these languages are often used in data architecture frameworks such as Hadoop, Apache Spark, and Kafka. noSQL storages, cloud warehouses, and other data implementations are handled via tools such as Informatica, Redshift, and Talend. Let’s go through the main areas.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! 5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice.
Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering. Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Kafka: Kafka is a top engineering tool highly valued by big data experts. Machine learning engineer: A machine learning engineer is an engineer who uses programming languages like Python, Java, Scala, etc.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. Equip yourself with the experience and know-how of Hadoop, Spark, and Kafka, and get some hands-on experience in AWS data engineer skills, Azure, or Google Cloud Platform. Step 4 - Who Can Become a Data Engineer?
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Big Data Frameworks : Familiarity with popular Big Data frameworks such as Hadoop, Apache Spark, Apache Flink, or Kafka are the tools used for data processing.
Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go. Apache Kafka Amazon MSK and Kafka Under the Hood Apache Kafka is an open-source streaming platform. Rely on the real information to guide you.
Table of Contents Apache Pig Apache Hive Apache Spark Apache Kafka Presto HBase Each of these innovations on Hadoop are packaged either in a cloud service or into a distribution and it is up to the organization to figure out the best way to integrate these hadoop components which can help them solve the business use case at hand.
Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Hadoop, MongoDB, and Kafka are popular Big Data tools and technologies a data engineer needs to be familiar with. They must be skilled at creating solutions that use the Azure Cosmos DB for NoSQL API.
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. It is an improvement over Hadoop’s two-stage MapReduce paradigm.
To ensure that big data recruiters find you for the right Hadoop job, focus on highlighting the specific Hadoop skills, spark skills or data science skills you want to work with, such as Pig & Hive , HBase, Oozie and Zookeeper, Apache Spark, Scala, machine learning , python, R language, etc.
AWS Glue Dev Endpoint serves as a development interface that enables users to develop, test, and debug ETL scripts interactively using PySpark or Scala. Amazon DynamoDB Accelerator (DAX) is a caching service that operates in memory for DynamoDB, a NoSQL database. How can AWS Glue Streaming ETL be utilized for real-time data processing?
Deepanshu’s skills include SQL, data engineering, Apache Spark, ETL, pipelining, Python, and NoSQL, and he has worked on all three major cloud platforms (Google Cloud Platform, Azure, and AWS). Beyond his work at Google, Deepanshu also mentors others on career and interview advice at topmate.io/deepanshu. deepanshu.
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers How is a data warehouse different from an operational database? Also, acquire a solid knowledge of databases such as the NoSQL or Oracle database. Table Storage in Microsoft Azure holds structured NoSQL data. What is a case class in Scala?
There is no need for other frameworks to apply their “magic” on top of Apache Kafka ® but instead stay in the pure event-first paradigm. Brokered systems like Kafka provide huge buffers (the default in Kafka is two weeks) which negate the need for explicit flow control for the vast majority of use cases.
On top of HDFS, the Hadoop ecosystem provides HBase , a NoSQL database designed to host large tables, with billions of rows and millions of columns. Streaming analytics became possible with the introduction of Apache Kafka , Apache Spark , Apache Storm , Apache Flink , and other tools to build real-time data pipelines.
It is a cloud-based NoSQL database that deals mainly with modern app development. Azure Table Storage- Azure Tables is a NoSQL database for storing structured data without a schema. It lets you store organized NoSQL data in the cloud and provides a schemaless key/attribute storage. What is Azure CosmosDB?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content