This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
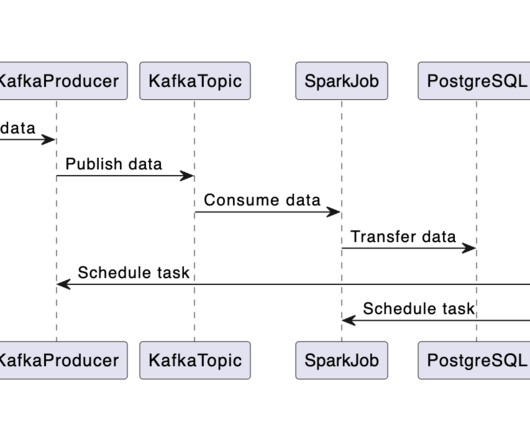
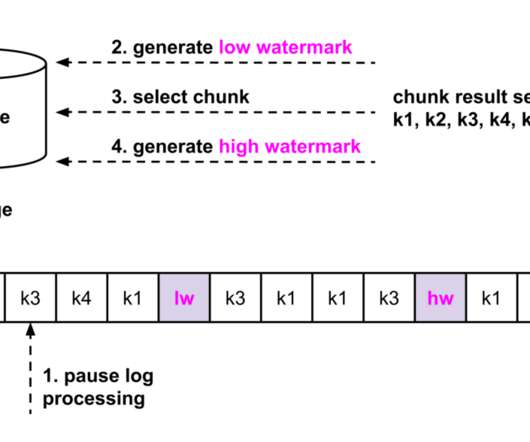
This involves getting data from an API and storing it in a PostgreSQL database. Overview Let’s break down the data pipeline process step-by-step: Data Streaming: Initially, data is streamed from the API into a Kafka topic. The data directory contains the last_processed.json file which is crucial for the Kafka streaming task.
The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing. Developers can work with the SQL constructs that they are familiar with while automatically getting the durability and reliability that Kafka offers. How is ksqlDB architected?
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®. The pipe symbol | (i.e.,
We’ll also take a look at some performance tests to see if Rust might be a viable alternative for Java applications using Apache Kafka ®. In this case, that means a command is created for a particular action, which will be assigned to a Kafka topic specific for that action. On May 15, 2015, the Core Kafka team released version 1.0
Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. With tools like KSQL and Kafka Connect, the concept of streaming ETL is made accessible to a much wider audience of developers and data engineers. Ingesting the data.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Here, I’m going to dig into one of the options available—the JDBC connector for Kafka Connect. Introduction.
Which one is better the Kafka or PostgreSQL for the implementation. RudderStack shows the concept behind the queueing System and how it is implemented.
This external consumer can be an asynchronous process that scans the “outbox” table or the database logs for new entries, and sends the message to an event bus, such as Apache Kafka. When defining a schema for our database table, it is important to think about what fields are needed to process and route the messages to Kafka.
release of PostGreSQL had on the design of the project? release of PostGreSQL had on the design of the project? Can you start by explaining what Timescale is and how the project got started? The landscape of time series databases is extensive and oftentimes difficult to navigate. What impact has the 10.0 What impact has the 10.0
To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers Links Decodable Podcast Episode Flink Podcast Episode Debezium Podcast Episode Kafka Redpanda Podcast Episode Kinesis PostgreSQL Podcast Episode Snowflake Podcast Episode Databricks Startree Pinot Podcast Episode Rockset Podcast Episode Druid (..)
Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Your host is Tobias Macey and today I’m interviewing Usman Masood and Derek Nelson about PipelineDB, an open source continuous query engine for PostgreSQL Interview Introduction How did you get involved in the area of data management?
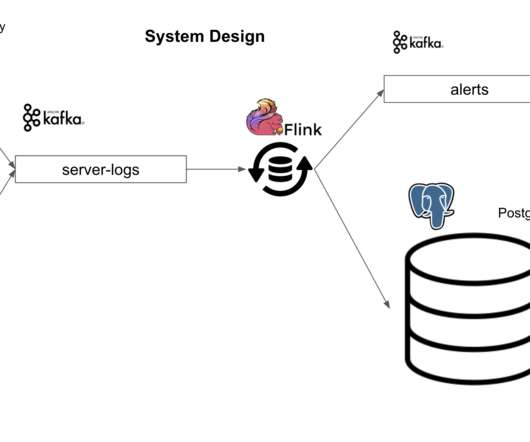
Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. In CSP, Kafka serves as the storage streaming substrate, and Flink as the core in-stream processing engine that supports SQL and REST interfaces. Apache Kafka and SMM.
How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product? How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product? Have you been able to leverage some of the native improvements to simplify your implementation?
Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL. You soon will be able to try out the Snowflake Connectors for PostgreSQL or MySQL by installing them from Snowflake Marketplace and downloading the agent from Docker Hub.
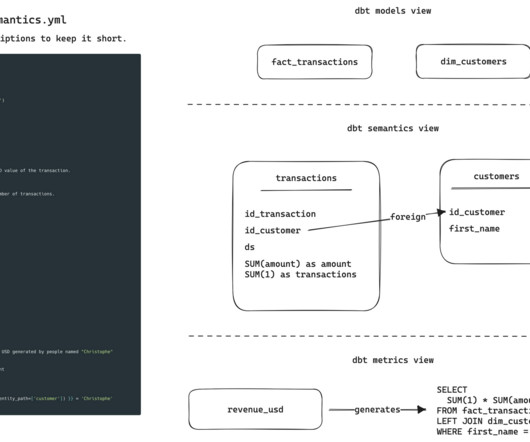
Read dbt metrics documentation As an extension I've seen 2 things this week that I feel makes sense here: VulcanSQL — A data API framework for DuckDB, Snowflake, BigQuery, PostgreSQL. The best way to describe it is: this is a Kafka alternative. Redpanda raises $100m in Series C. Redpanda is a great product for developers.
I understand that your original architecture used RabbitMQ as your ingest mechanism, which you then migrated to Kafka. I understand that your original architecture used RabbitMQ as your ingest mechanism, which you then migrated to Kafka. What was your initial motivation for that change? What was your initial motivation for that change?
The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast Summary Modern applications frequently require access to real-time data, but building and maintaining the systems that make that possible is a complex and time consuming endeavor.
Links Starburst Data Presto Hadapt Hadoop Hive Teradata PrestoCare Cost Based Optimizer ANSI SQL Spill To Disk Tempto Benchto Geospatial Functions Cassandra Accumulo Kafka Redis PostGreSQL The intro and outro music is from The Hug by The Freak Fandango Orchestra / {CC BY-SA]([link] Support Data Engineering Podcast
Disclaimer: There are nice projects around like PostgreSQL full-text search that might be enough for your use case, and you should certainly consider them. Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®.
How has the tight coupling with Kafka impacted the direction and capabilities of Debezium? How has the tight coupling with Kafka impacted the direction and capabilities of Debezium? What are some of the other options on the market for handling change data capture? What, if any, other substrates does Debezium support (e.g.
Change Data Capture (CDC) with PostgreSQL and ClickHouse — This is a nice vendor post about CDC with Kafka as movement layer (using Debezium). — Marie wrote best practices for establishing complete and reliable data documentation. The post explains well the architecture you need to make it work.
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Links Sentry Podcast.__init__
For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase. Here’s a breakdown of employee numbers from Idan: Tens of people (between 10 and 30) maintaining hardware 25-30 people maintaining data infrastructure like Kafka or RabbitMQ.
Rockset replicates the data in real-time from your primary database, including both the initial full-copy data replication into Rockset and staying in sync by continuously reading your MySQL or PostgreSQL change streams.
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Links How DoorDash is Scaling its Data Platform to Delight Customers and Meet our Growing Demand DoorDash Uber Netscape Netflix Change Data Capture Debezium Podcast (..)
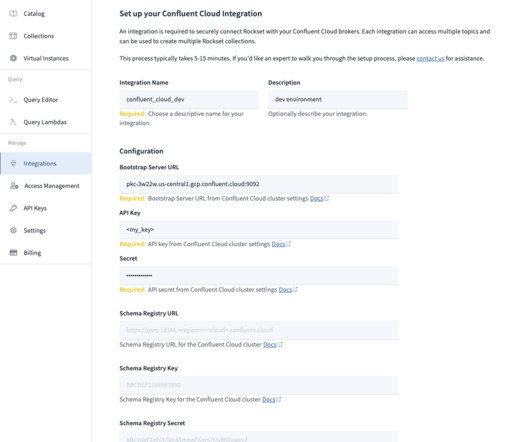
Building a Cloud ETL Pipeline on Confluent Cloud shows you how to build and deploy a data pipeline entirely in the cloud. However, not all databases can be in the […].
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. For example in PostgreSQL RDS, changes can only be captured from the master.
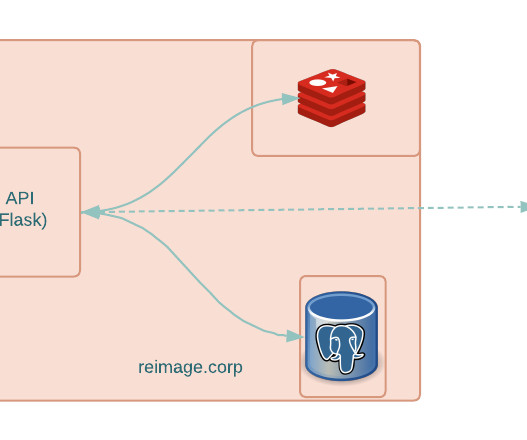
There was reliance on an unmanaged data layer.Redis (for caching) and PostgreSQL (as primary datastore)served as single points of failure for this product. Managing data replication for data in PostgreSQL could have been more robust. We decided to leverage Kafka as a distributed messaging queue.
Finally RudderStack keys "Why they did not prefer Apache Kafka over PostgreSQL for building RudderStack?". Focuses on the challenges using Apache Kafka
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. For example in PostgreSQL RDS, changes can only be captured from the master.
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Links DataForm YCombinator DBT == Data Build Tool Podcast Episode Fishtown Analytics Typescript Continuous Integration Continuous Delivery BigQuery Snowflake DB (..)
We started with PostgreSQL, laying the foundation for structured analytics early on. Seven years on, the transformation isclear: Top-tier DataOps tools: Snowflake, dbt, Terraform, ClickHouse, Kafka, dbt-score. The Turning Point: Year3 At Picnic we had a Data Warehouse from the start, from the very first order.
What are the benefits of using PostgreSQL as the system of record for Marquez? What are the benefits of using PostgreSQL as the system of record for Marquez? Can you explain how Marquez is architected and how the design has evolved since you first began working on it? How is the metadata itself stored and managed in Marquez?
To help other people find the show please leave a review on Apple Podcasts and tell your friends and co-workers Links Milvus Zilliz Linux Foundation/AI & Data MySQL PostgreSQL CockroachDB Pilosa Podcast Episode Pinecone Vector DB Podcast Episode Vector Embedding Reverse Image Search Vector Arithmetic Vector Distance SIGMOD Tensor Rotation Matrix (..)
The solution centered around Notebook opens a Flink Session for the Kafka stream and continues the exploration. It opens some old memory; try to solve this problem first with Presto-Kafka connector and then using OLAP engines like Druid & Apache Pinot. How are you analyzing the cost of your infrastructure?
Initially, we built a quick prototype of the data services - primitive CRUD-type services, with synchronous HTTP APIs, each interacting directly with a simple (dedicated) PostgreSQL database as the operational store for the data. Outbound events were generated after completion of DB updates. all primed from the single eventing platform.
An MV is a special type of sink that allows us to output data from our query into a tabular format persisted in a PostgreSQL database. A sink could be another data stream or we could use a special type of data sink we call a materialized view (MV). We can also query this data later, optionally with filters using SSBs REST API.
Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. PostgreSQL, MySQL, SQL Server, and even Oracle are popular choices, but there are many others that will work fine.
Snowflake’s native connectors , including the existing Snowflake Connector for Kafka and for ServiceNow , are built with scalability, cost efficiency and lower latency. Getting data ingested now only takes a few clicks, and the data is encrypted.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content