This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing. Developers can work with the SQL constructs that they are familiar with while automatically getting the durability and reliability that Kafka offers. How is ksqlDB architected?
link] Gunnar Morling: What If We Could Rebuild Kafka From Scratch? KIP-1150 ("Diskless Kafka") is one of my most anticipated releases from Apache Kafka. Then, a custom Apache Beam consumer processed these events, transforming and writing them to CRDB.
Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. Check out the agenda and register today at Neo4j.com/NODES.
This involves getting data from an API and storing it in a PostgreSQL database. This first part project is ideal for beginners in data engineering, as well as for data scientists and machine learning engineers looking to deepen their knowledge of the entire data handling process. To set-up and run these tools we will use Docker.
Cloudera has a strong track record of providing a comprehensive solution for stream processing. Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. Cloudera Stream Processing Community Edition. Apache Kafka and SMM.
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®. The pipe symbol | (i.e.,
We’ll also take a look at some performance tests to see if Rust might be a viable alternative for Java applications using Apache Kafka ®. In this case, that means a command is created for a particular action, which will be assigned to a Kafka topic specific for that action. On May 15, 2015, the Core Kafka team released version 1.0
Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. With tools like KSQL and Kafka Connect, the concept of streaming ETL is made accessible to a much wider audience of developers and data engineers. Ingesting the data.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Here, I’m going to dig into one of the options available—the JDBC connector for Kafka Connect. Introduction.
The record in the “outbox” table contains information about the event that happened inside the application, as well as some metadata that is required for further processing or routing. InventoryService) or processing a payment (eg. After the transaction commits, the record will be available for external consumers. PaymentService).
Summary Processing high velocity time-series data in real-time is a complex challenge. Given the fact that it is a plugin for PostgreSQL, what level of compatibility exists between PipelineDB and other plugins such as Timescale and Citus? Can you start by explaining what PipelineDB is and the motivation for creating it?
Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL. With other ingestion improvements and our new database connectors, we are smoothing out the data ingestion process, making it radically simple and efficient to bring data to Snowflake.
release of PostGreSQL had on the design of the project? release of PostGreSQL had on the design of the project? Can you start by explaining what Timescale is and how the project got started? The landscape of time series databases is extensive and oftentimes difficult to navigate. What impact has the 10.0 What impact has the 10.0
release, how the use cases for timeseries data have proliferated, and how they are continuing to simplify the task of processing your time oriented events. How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product?
Astronomer is a platform that lets you skip straight to processing your valuable business data. Regulatory challenges of processing other people’s data What does your data pipelining architecture look like? Astronomer is a platform that lets you skip straight to processing your valuable business data.
In this episode ThreatStack’s director of operations, Pete Cheslock, and senior infrastructure security engineer, Patrick Cable, discuss the data infrastructure that supports their platform, how they capture and process the data from client systems, and how that information can be used to keep your systems safe from attackers.
This was an interesting inside look at building a business on top of open source stream processing frameworks and how to reduce the burden on end users. What are some of the most interesting, unexpected, or challenging lessons that you have learned in the process of building and scaling Eventador?
Disclaimer: There are nice projects around like PostgreSQL full-text search that might be enough for your use case, and you should certainly consider them. Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®. Scaling indexing.
For someone who is adopting Yellowbrick, what is the process for getting it integrated into their data systems? For someone who is adopting Yellowbrick, what is the process for getting it integrated into their data systems? What are some data modeling strategies that users should consider when designing their deployment of Yellowbrick?
In this episode James Cunningham and Ted Kaemming describe the process of rearchitecting a production system, what they learned in the process, and some useful tips for anyone else evaluating Clickhouse. What did the previous system look like? What was your design criteria for building a new platform?
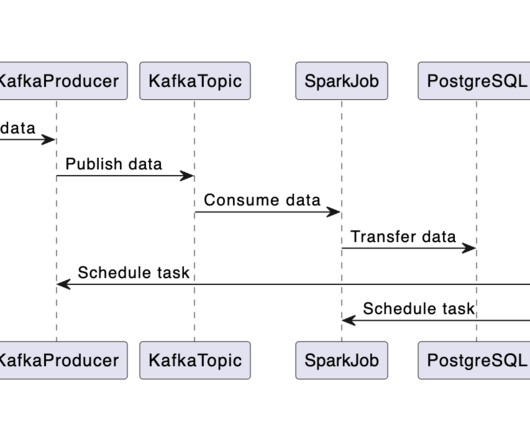
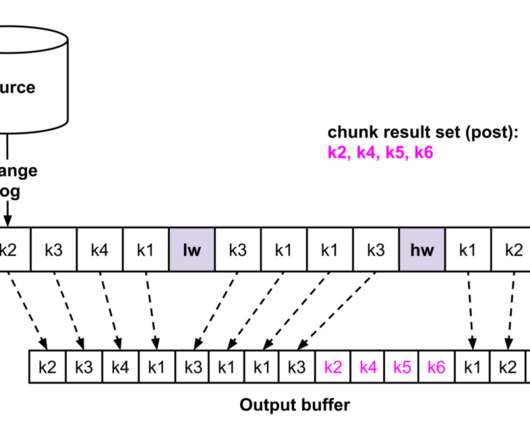
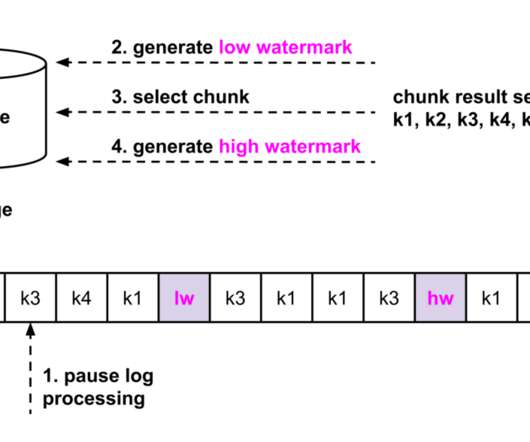
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. This motivated the development of DBLog , which offers log and dump processing under a generic framework. Some of DBLog’s features are: Processes captured log events in-order. This way log processing can progress alongside dump processing.
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. This motivated the development of DBLog , which offers log and dump processing under a generic framework. Some of DBLog’s features are: Processes captured log events in-order. This way log processing can progress alongside dump processing.
How much processing overhead is involved in the conversion from the column oriented data stored on disk to the row oriented data stored in memory? How much processing overhead is involved in the conversion from the column oriented data stored on disk to the row oriented data stored in memory?
With the overarching theme of enabling Site Reliability engineers (SREs) to take ownership of this entire process, we had to think outside the existing solution, which led to designing a tool that could allow direct access to SREs for managing server lifecycle. Managing data replication for data in PostgreSQL could have been more robust.
Can you give an overview of the collection process for that data? Can you give an overview of the collection process for that data? Can you describe the type(s) of data that you are working with? What are the primary sources of data that you collect? What secondary or third party sources of information do you rely on?
Your host is Tobias Macey and today I’m interviewing Lewis Hemens about DataForm, a platform that helps analysts manage all data processes in your cloud data warehouse Interview Introduction How did you get involved in the area of data management? Can you talk through some of the use cases that having an embedded runtime enables?
For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. For analytical systems there are decades of investment in data warehouses and various modeling techniques.
The user journey, sales process, marketing campaign, everything falls under a state machine. Data modeling is a collaborative process across business units to capture state changes in business activity. The solution centered around Notebook opens a Flink Session for the Kafka stream and continues the exploration.
We started with PostgreSQL, laying the foundation for structured analytics early on. On one hand, the growing volume of data significantly increased processing times, making it difficult to refresh the Data Warehouse overnight. The Turning Point: Year3 At Picnic we had a Data Warehouse from the start, from the very first order.
Cloudera SQL Stream Builder (SSB) gives the power of a unified stream processing engine to non-technical users so they can integrate, aggregate, query, and analyze both streaming and batch data sources in a single SQL interface. Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). What is a materialized view?
These consumers would subscribe, receive, and process the data appropriately for their own needs - essentially inverting the flow of data, from the traditional “pull” based architectures, to a “push” based approach. With this selection of Kafka as the outbound event platform, it was also a natural selection for the inbound data processing.
Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. PostgreSQL, MySQL, SQL Server, and even Oracle are popular choices, but there are many others that will work fine.
Supporting open storage architectures The AI Data Cloud is a single platform for processing and collaborating on data in a variety of formats, structures and storage locations, including data stored in open file and table formats. Getting data ingested now only takes a few clicks, and the data is encrypted.
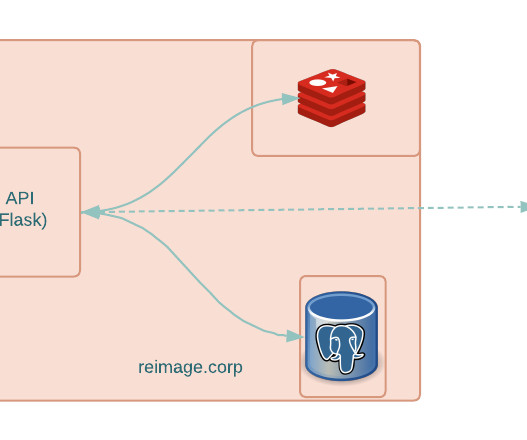
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka. This allowed us to enable direct pod-to-pod communication for Iguazu traffic, enabling zone-aware routing while simultaneously reducing the volume of traffic processed by the ELBs as shown in Figure 10.
Vector Search and Unstructured Data Processing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
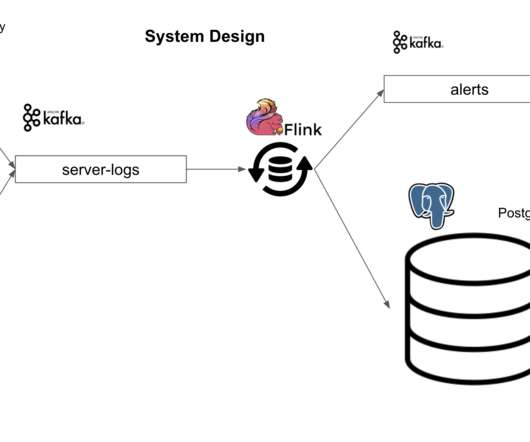
Introduction Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time analytics is a challenge for many teams. Logstash is an event processing pipeline that ingests and transforms data before sending it to Elasticsearch.
As part of our learning process, we recently designed and built Saiki : a scalable, cloud-based data integration infrastructure that makes data from our many microservices readily available for analytical teams. This approach allows for a non-intrusive and reliable Change Data Capture of PostgreSQL databases.
At the heart of data engineering lies the ETL process—a necessary, if sometimes tedious, set of operations to move data across pipelines for production. Now imagine having a co-pilot to streamline and supercharge the process. Tune the load process I'm using PostgreSQL to store my company's transactional data.
These tools help in various stages of data processing, storage, and analysis. Open Source Support: Many Azure services support popular open-source frameworks like Apache Spark, Kafka, and Hadoop, providing flexibility for data engineering tasks. Let’s read about them in the next section.
The overall upgrade follows a seven-step process illustrated below. PostgreSQL 10, 11 and 12 and OracleDB 12c, 19c and 19.9. Add Kafka Service – Required for Atlas if it’s not already installed. and will later be converted to Ranger policies and automatically imported during the Upgrade Wizard process.
Yet the “Modern Data Stack” is largely focussed on delivering batch processing and reporting on historical data with cloud-native platforms. You see real-time stock tickers on TV, you use real-time odometers when you’re driving to gauge your speed, when you check the weather in your app.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 PostgreSQL 14 – Sometimes I forget, but traditional relational databases play a big role in the lives of data engineers. And of course, PostgreSQL is one of the most popular databases. rc0 to the release of 3.0.0.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 PostgreSQL 14 – Sometimes I forget, but traditional relational databases play a big role in the lives of data engineers. And of course, PostgreSQL is one of the most popular databases. rc0 to the release of 3.0.0.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content