
End-to-End Data Engineering System on Real Data with Kafka, Spark, Airflow, Postgres, and Docker
Towards Data Science
FEBRUARY 9, 2024
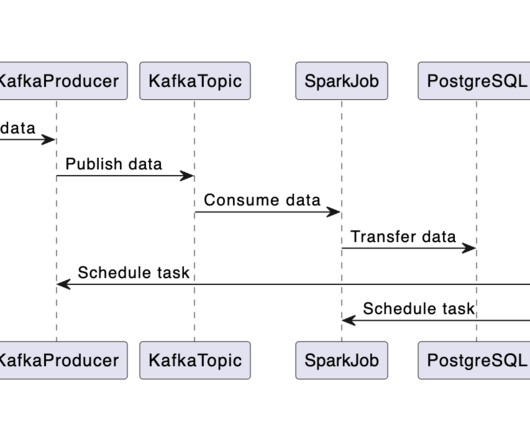
This involves getting data from an API and storing it in a PostgreSQL database. Overview Let’s break down the data pipeline process step-by-step: Data Streaming: Initially, data is streamed from the API into a Kafka topic. The data directory contains the last_processed.json file which is crucial for the Kafka streaming task.








































Let's personalize your content