This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional relationaldatabase systems are ubiquitous in software systems. They are surrounded by a strong ecosystem of tools, such as object-relational mappers and schema migration helpers. A tomicity in relationaldatabases ensures that a transaction either succeeds or fails as a whole.
How to use Kafka Streams to aggregate change data capture (CDC) messages from a relationaldatabase into transactional messages, powering a scalable microservices architecture.
With Snowpipe for Apache Kafka (public preview soon in AWS and Microsoft Azure), a “pull” mechanism, rather than the existing “push” connector, allows you to extract and ingest Apache Kafka events into your Snowflake account directly without hosting your own Kafka Connect cluster.
Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. Microservices, Apache Kafka, and Domain-Driven Design (DDD) covers this in more detail. Example: Severstal.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. That is because relationaldatabases are a rich source of events. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. What we’ll cover.
One of the most common relationaldatabase systems that connects to Apache Kafka® is Oracle, which often holds highly critical enterprise transaction workloads. While Oracle Database (DB) excels at many […].
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. gradlew composeUp. The KSQL pipeline flow.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relationaldatabase might not be enough. Building an indexing pipeline at scale with Kafka Connect.
What’s forgotten is that the rise of this paradigm was driven by a particular type of human-facing application in which a user looks at a UI and initiates actions that are translated into database queries. This may seem far from the domain of a database, but I’ll argue that the common conception of databases is too narrow for what lies ahead.
Similar to how data modeling techniques emerged during the burst of relationdatabases, we started to see similar strategies for fine-tuning and prompt templates. And this is where DoubleCloud comes in: with our fully managed service for Apache Kafka, you can deploy production-ready clusters in just about 10 minutes.
Links Alooma Convert Media Data Integration ESB (Enterprise Service Bus) Tibco Mulesoft ETL (Extract, Transform, Load) Informatica Microsoft SSIS OLAP Cube S3 Azure Cloud Storage Snowflake DB Redshift BigQuery Salesforce Hubspot Zendesk Spark The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay (..)
How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? How does Flink compare to other streaming engines such as Spark, Kafka, Pulsar, and Storm? Can you start by describing what Flink is and how the project got started? What are some of the primary ways that Flink is used? How is Flink architected?
Summary Data warehouses have gone through many transformations, from standard relationaldatabases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines.
So they needed a data warehouse that could keep up with the scale of modern big data systems , but provide the semantics and query performance of a traditional relationaldatabase. Deep Dive into Time Series and Event Analytics Specialized RTDW , featuring Apache Druid, Apache Hive, Apache Kafka, and Cloudera DataViz.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
Data engineers who previously worked only with relationaldatabase management systems and SQL queries need training to take advantage of Hadoop. Another available schema — DataFrames — is used to organize information in the named columns, similar to tables in relationaldatabases. Complex programming environment.
Apache Kafka has seen broad adoption as the streaming platform of choice for building applications that react to streams of data in real time. In many organizations, Kafka is the foundational platform for real-time event analytics, acting as a central location for collecting event data and making it available in real time.
The new database connectors are built on top of Snowpipe Streaming, which means they also provide more cost-effective and lower latency pipelines for customers.
When people ask me the very top-level question “why do people use Kafka,” I usually lead with the story in my last post , where I talked about how Apache Kafka ® is helping us deliver on the promises the cloud made to us a decade ago. Industry heavyweights like Capital One use event streaming on Kafka for this very task.
Rockset continuously ingests data streams from Kafka, without the need for a fixed schema, and serves fast SQL queries on that data. We created the Kafka Connect Plugin for Rockset to export data from Kafka and send it to a collection of documents in Rockset. Implementing a working plugin What is Kafka Connect and Confluent Hub?
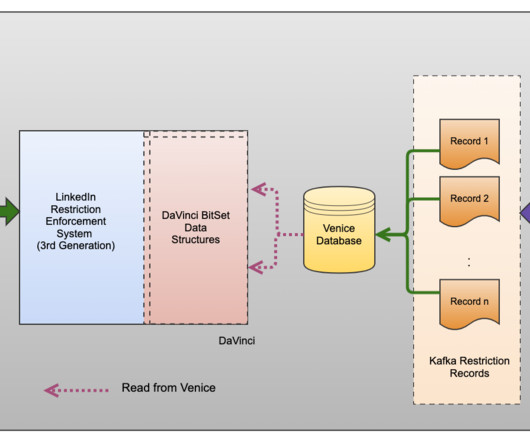
At the heart of this system was a reliance on a relationaldatabase, Oracle, which served as the repository for all member restrictions data. Figure 2: Relationaldatabase schema We adopted a pragmatic and scalable approach by distributing member restrictions across different Oracle tables.
Luckily, we have Kafka events that are emitted each time a piece of data changes. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?marketing Search Indexer.
Imagine, for instance, that we have a real-time Kafka stream containing plane data and we are working on an application that needs to download all planes in a certain area, above some altitude at any given time via REST. Primary key Every MV requires a primary key, as this will be our primary key in the underlying relationaldatabase as well.
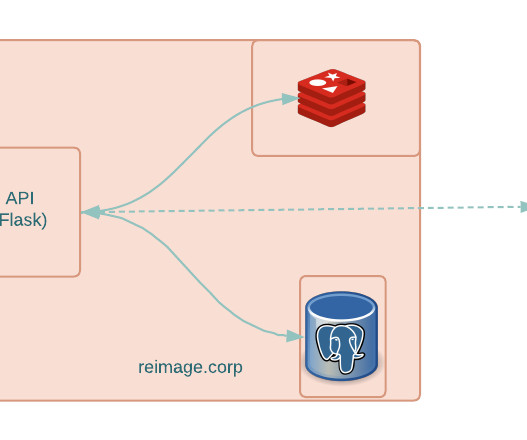
For MaaS, the starting point was co-hosting the web service, relationaldatabase ( Postgres ), and Redis -based caching layer on a server. We decided to leverage Kafka as a distributed messaging queue. The choice of Kafka mainly stemmed from its widespread use within LinkedIn and its dedicated support SLA.
Data Extraction with Apache Hadoop and Apache Sqoop : Hadoop’s distributed file system (HDFS) stores large data volumes; Sqoop transfers data between Hadoop and relationaldatabases. Data Loading with Apache Hadoop and Apache Sqoop : Hadoop stores processed data; Sqoop loads it back into relationaldatabases if needed.
Logstash offers a JDBC input plugin that polls a relationaldatabase, like PostgreSQL or MySQL, for inserts and updates periodically. Logstash offers a JDBC input plugin that polls a relationaldatabase, like PostgreSQL or MySQL, for inserts and updates periodically.
This data isn’t just about structured data that resides within relationaldatabases as rows and columns. NoSQL databases, also known as non-relational or non-tabular databases, use a range of data models for data to be accessed and managed. Cassandra is an open-source NoSQL database developed by Apache.
KafkaKafka is an open-source processing software platform. The applications developed by Kafka can help a data engineer discover and apply trends and react to user needs. You can refer to the following links to learn about Kafka: Apache Kafka Training by KnowledgeHut 6.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
It frequently also means moving operational data from native mainframe databases to modern relationaldatabases. Typically, a mainframe to cloud migration includes re-factoring code to a modern object-oriented language such as Java or C# and moving to a modern relationaldatabase.
Breaking Bad… Data Silos We haven’t quite figured out how to avoid using relationaldatabases. Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack.
NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase. In general, Hadoop and Spark are good choices for batch processing, while Kafka and Storm are better suited for streaming applications.
Classic relationaldatabase management systems (RDBMS) distribute and organize data in a relatively static storage layer. When queries are requested, they compute on the stored data and then return results […].
Knowing SQL means you are familiar with the different relationaldatabases available, their functions, and the syntax they use. For example, you can learn about how JSONs are integral to non-relationaldatabases – especially data schemas, and how to write queries using JSON.
The structure of data is usually predefined before it is loaded into a warehouse, since the DW is a relationaldatabase that uses a single data model for everything it stores. In a nutshell, a model is a specific data structure a database can ingest. Enrichment helps us increase the value of data by adding extra-context.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 PostgreSQL 14 – Sometimes I forget, but traditional relationaldatabases play a big role in the lives of data engineers. And of course, PostgreSQL is one of the most popular databases.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 PostgreSQL 14 – Sometimes I forget, but traditional relationaldatabases play a big role in the lives of data engineers. And of course, PostgreSQL is one of the most popular databases.
link] Percona: JSON and RelationalDatabases – Part One Whether we like it or not, most data engineering and modeling challenges will be handling semi-structured data in the coming years. The Percona blog walkthrough JSON support in the relationaldatabases. Streaming plus batch unified in a single platform.
Kafka Apache Kafka is the Apache Foundation’s open-source software platform for streaming. MySQL An open-source relational databse management system with a client-server model. PostgreSQL A free, open-source relationaldatabase management system, also known as Postgres.
The data flow is somewhat inverted: every photo or piece of text that enters Booking.com is broadcasted through the companys system for general use via Kafka. We then persist the results in a relational DB (the specific DB varies per use case) for each piece ofcontent. We use Apache Flink to implement our streaming pipeline.
Relationaldatabases today are widely known to be suboptimal for supporting high-scale analytical use cases, and are all but certain to run into issues as your production data size and query volume grow. Compute and storage are also separately scaled in Rockset, allowing you to cost-optimize for the desired performance of your choice.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. This collection of data is kept in Dataframe in rows with named columns, similar to relationaldatabase tables. Spark Streaming accepts a continuous data stream as input from Apache Flume, Kinesis, Kafka , TCP sockets, and others.
According to recent studies, the global database market will grow from USD 63.4 SQL is a powerful tool for managing and manipulating relationaldatabases, and it continues to be widely used in the industry today. billion in 2022 to $154.6 billion by 2030, at a CAGR of 11.8%. How is SQL Being Utilized?
Snowflake announced Snowpipe for streaming and refactored their Kafka connector, and Google announced Pub/Sub could now be streamed directly into the BigQuery. Increasingly, data warehouses and data lakes are moving toward each other in a general shift toward data lakehouse architecture.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content