This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IT industries rely heavily on real-time insights derived from streaming data sources. Handling and processing the streaming data is the hardest work for Data Analysis.
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. Here’s a closer look.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Challenges Faced by AI Data Engineers Just because “AI” involved doesn’t mean all the challenges go away!
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
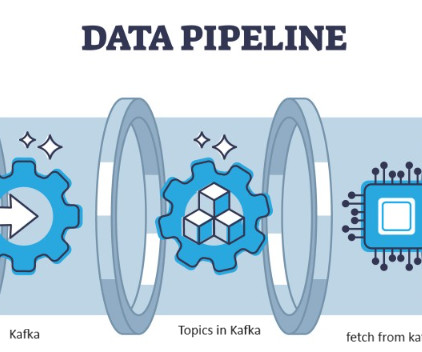
A trend often seen in organizations around the world is the adoption of Apache Kafka ® as the backbone for data storage and delivery. Different data problems have arisen in the last two decades, and we ought to address them with the appropriate technology. more data per server) and constant retrieval time.
In today’s demand for more business and customer intelligence, companies collect more varieties of data — clickstream logs, geospatial data, social media messages, telemetry, and other mostly unstructureddata.
CDF offers key capabilities such as Edge and Flow Management, Streams Messaging, and Stream Processing & Analytics, by leveraging open source projects such as Apache NiFi, Apache Kafka, and Apache Flink, to build edge-to-cloud streaming applications easily. The Value Proposition of CDF in Data Mesh Implementations.
Lineage and chain of custody, advanced data discovery and business glossary. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. Cluster management and replication support for Kafka clusters. Relevance-based text search over unstructureddata (text, pdf,jpg, …). Virtual private clusters.
With support for more than 400 processors, CDF-PC makes it easy to collect and transform the data into the format that your lakehouse of choice requires. Addressing the hybrid data collection and distribution requirements with a data distribution service. Release : Supports the latest Apache NiFi Release 1.16
Bringing in batch and streaming data efficiently and cost-effectively Ingest and transform batch or streaming data in <10 seconds: Use COPY for batch ingestion, Snowpipe to auto-ingest files, or bring in row-set data with single-digit latency using Snowpipe Streaming.
We’ll build a data architecture to support our racing team starting from the three canonical layers : Data Lake, Data Warehouse, and Data Mart. Data Lake A data lake would serve as a repository for raw and unstructureddata generated from various sources within the Formula 1 ecosystem: telemetry data from the cars (e.g.
Vector Search and UnstructuredData Processing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
If you are struggling with Data Engineering projects for beginners, then Data Engineer Bootcamp is for you. Some simple beginner Data Engineer projects that might help you go forward professionally are provided below. Source Code: Stock and Twitter Data Extraction Using Python, Kafka, and Spark 2.
Amsterdam service utilizes various solutions such as Cassandra , Kafka , Zookeeper , EvCache etc. Elasticsearch Integration Elasticsearch is one of the best and widely adopted distributed, open source search and analytics engines for all types of data, including textual, numerical, geospatial, structured or unstructureddata.
Analyzing and organizing raw data Raw data is unstructureddata consisting of texts, images, audio, and videos such as PDFs and voice transcripts. The job of a data engineer is to develop models using machine learning to scan, label and organize this unstructureddata.
Lambda or Kappa architectures) and implementing reliable streaming capabilities at scale by leveraging technologies such as Apache NiFi and Apache Kafka, has made possible the ability to harness and commercialize an ever-increasing volume of real-time data such as time-series or clickstream data.
Intro In recent years, Kafka has become synonymous with “streaming,” and with features like Kafka Streams, KSQL, joins, and integrations into sinks like Elasticsearch and Druid, there are more ways than ever to build a real-time analytics application around streaming data in Kafka.
It allows you to process real-time streams like Apache Kafka using Python with incredible simplicity. We collect hundreds of petabytes of data on this platform and use Apache Spark to analyze these enormous amounts of data. Alibaba: Alibaba Taobao operates one of the world’s largest e-commerce platforms.
StreamSets — The industry’s first data operations platform for full life-cycle management of data in motion. Infoworks — Use big data automation to simplify data engineering and DataOps. Lenses — The enterprise overlay for Apache Kafka R & Kubernetes. IBM – IBM renamed several of their products as DataOps.
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. The data lakehouse’s semantic layer also helps to simplify and open data access in an organization.
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. The data lakehouse’s semantic layer also helps to simplify and open data access in an organization.
Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. Historically these highly specialized platforms were deployed on-prem in private data centers to ensure greater control , security, and compliance. But the “elephant in the room” is NOT ‘Hadoop’.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
A data hub, in turn, is rather a terminal or distribution station: It collects information only to harmonize it, and sends it to the required end-point systems. Data lake vs data hub. A data lake is quite opposite of a DW, as it stores large amounts of both structured and unstructureddata.
Popular Data Ingestion Tools Choosing the right ingestion technology is key to a successful architecture. Common Tools Data Sources Identification with Apache NiFi : Automates data flow, handling structured and unstructureddata. Used for identifying and cataloging data sources.
It’s worth noting though that data collection commonly happens in real-time or near real-time to ensure immediate processing. Thanks to flexible schemas and great scalability, NoSQL databases are the best fit for massive sets of raw, unstructureddata and high user loads. Apache Kafka.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Image Credit: twitter.com There are hundreds of companies like Facebook, Twitter, and LinkedIn generating yottabytes of data. What is Big Data according to EMC? What is Hadoop?
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
RDD easily handles both structured and unstructureddata. The module can absorb live data streams from Apache Kafka , Apache Flume , Amazon Kinesis , Twitter, and other sources and process them as micro-batches. Just for reference, Spark Streaming and Kafka combo is used by.
As AI models become more advanced, LLMs and generative AI apps are liberating information that is typically locked up in unstructureddata. Using our previous serving infrastructure, the data would have to be sent through Confluent-hosted instances of Apache Kafka and ksqlDB and then denormalized and/or rolled up.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. However, it is not straightforward to create data pipelines.
Of course there are many other ways (Spark in the Data Engineering experience, Nifi in the Data Flow experience, Kafka in the Stream Management experience, and so on), but those will be covered in future blog posts. If you decide to try DDE in CDP out , please let us know how it all went!
Streaming Kafka/ Confluent is king when it comes to data streaming, but working with streaming data introduces a number of new considerations beyond topics, producers, consumers, and brokers, such as serialization, schema registries, stream processing/transformation and streaming analytics.
Testing Limitations: Both dbt Cloud and dbtCore dbt is designed for SQL-based transformations in data warehouses, meaning it is not well-suited for non-SQL, real-time, or highly complex unstructureddata transformations. The following categories of transformations pose significant limitations for dbt Cloud and dbtCore : 1.
Analytics databases ingest data in as near real time as possible, and allow fast analytical queries to be done on this data. However, with this data being streamed in real-time, it makes sense to also process and analyze it in real-time, especially if you have a genuine use case for up-to-date analytics. Which Should I Use?
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Concepts of IaaS, PaaS, and SaaS are the trend, and big companies expect data engineers to have the relevant knowledge.
Use Snowflake’s native Kafka Connector to configure Kafka topics into Snowflake tables. Snowflake’s support for unstructureddata also means you can annotate and process images, emails, PDFs, and more into semi-structured or structured data usable by your ML model running within Snowflake.
Its essential for fraud detection, live analytics dashboards, IoT data, and recommendation engines (think Netflix or Spotify adjusting recommendations instantly). Popular tools include Apache Kafka , Apache Flink , and AWS Kinesis. Data Lakes Data lakes store raw, unstructureddata.
In 2021, Vimeo moved from a process involving big complicated ETL pipelines and data warehouse transformations to one focused on data consumer defined schemas and managed self-service analytics.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with big data knowledge. They transform unstructureddata into scalable models for data science.
Just before we jump on to a detailed discussion on the key components of the Hadoop Ecosystem and try to understand the differences between them let us have an understanding on what is Hadoop and what is Big Data. What is Big Data and Hadoop?
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructureddata. Data pipelines can be automated and maintained so that consumers of the data always have reliable data to work with.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content