


8 Essential Data Pipeline Design Patterns You Should Know
Monte Carlo
NOVEMBER 21, 2024
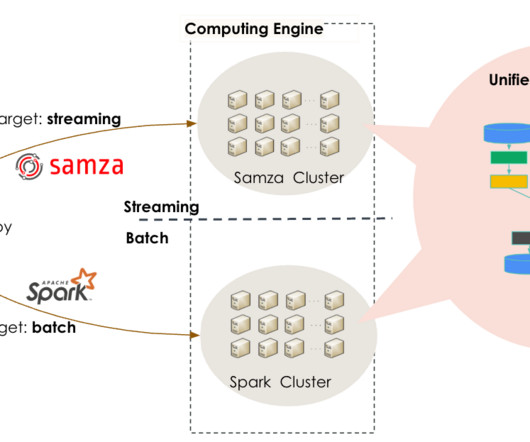
Lambda Architecture Pattern 4. Kappa Architecture Pattern 5. Lambda Architecture Pattern Here’s where things get interesting. Lambda architecture is like having both a regular washing machine for your weekly loads AND that magical instant-wash machine. Batch Processing Pattern 2.






























Let's personalize your content