This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this guide, we’ll explore the patterns that can help you design data pipelines that actually work. Table of Contents Common Data Pipeline Design Patterns Explained 1. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5. Data Mesh Pattern 8. The data lakehouse has got you covered!
That meant a system that was sufficiently nimble and powerful to execute fast SQL queries on rawdata, essentially performing any needed transformations as part of the query step, and not as part of a complex data pipeline. Most processing in the Lambdaarchitecture happens in the pipeline and not at query time.
You can find a comprehensive guide on how data ingestion impacts a data science project with any Data Science course. Why Data Ingestion is Important? Data ingestion provides certain benefits to the business: The rawdata coming from various sources is highly complex. Why Data Ingestion is Important?
Data streamed in is queryable immediately, in an optimal manner. Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. Data Model. Conventional enterprise data types. Figure 1 below shows a standard architecture for a Real-Time Data Warehouse.
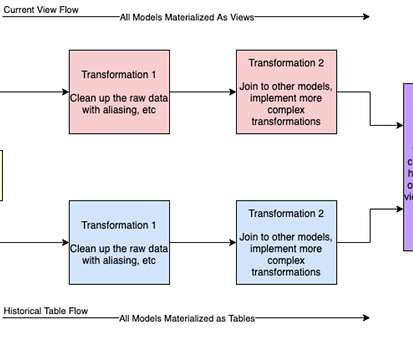
Lambda views are a simple and readily available solution that is tool agnostic and SQL based. What are lambda views? The idea of lambda views comes from lambdaarchitecture. This enables handling a lot of data in a very performant manner. This is what I implemented at JetBlue.
Ingestion: Your data pipeline architecture should anticipate a wide variety of rawdata sources to be incorporated into the pipeline. These include internal sources, operational systems, the databases and files provided by business partners, and third-party sources from regulators, agencies, and data aggregators.
Some data teams will leverage micro-batch strategies for time sensitive use cases. These involve data pipelines that will ingest data every few hours or even minutes. Also worth noting is lambdaarchitecture-based data ingestion which is a hybrid model that combines features of both streaming and batch data ingestion.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content