This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This can be done by finding regularities in the data, such as correlations or trends, or by identifying specific features in the data. Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection. What Is Pattern Recognition?
Today, we have AI and machinelearning to extract insights, inaudible to human beings, from speech, voices, snoring, music, industrial and traffic noise, and other types of acoustic signals. At the same time, keep in mind that neither of those and other audio files can be fed directly to machinelearning models.
Datasets play a crucial role and are at the heart of all MachineLearning models. MachineLearning without data sets will not exist because ML depends on data sets to bring out relevant insights and solve real-world problems. In the real world, data sets are huge.
So businesses employ machinelearning (ML) and Artificial Intelligence (AI) technologies for classification tasks. Namely, we’ll look at how rule-based systems and machinelearning models work in this context. It requires extracting rawdata from claims automatically and applying NLP for analysis.
On that note, let's understand the difference between MachineLearning and Deep Learning. Below is a thorough article on MachineLearning vs Deep Learning. We will see how the two technologies differ or overlap and will answer the question - What is the difference between machinelearning and deep learning?
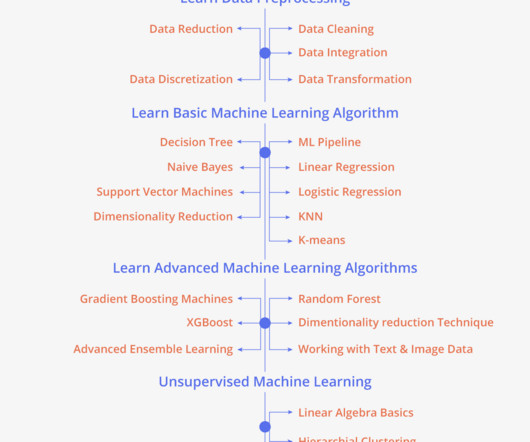
What is a MachineLearning Pipeline? A machinelearning pipeline helps automate machinelearning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. Table of Contents What is a MachineLearning Pipeline?
We use imputation because lost data can cause these problems: Distorts Dataset When there is a lot of missing data, it can cause unusual patterns in how the data is distributed, which may affect the value of different categories in the dataset. Several factors can affect the chances of having lost data.
Among various such implementations, two of the most prominent subsets that have garnered enough attention are Generative AI and MachineLearning. Both Generative AI and MachineLearning share the common goal of enabling machines to learn and make predictions.
Machinelearning evangelizes the idea of automation. On the surface, ML algorithms take the data, develop their own understanding of it, and generate valuable business insights and predictions — all without human intervention. In truth, ML involves an enormous amount of repetitive manual operations, all hidden behind the scenes.
Understanding what defines data in the modern world is the first step toward the Data Science self-learning path. There is a much broader spectrum of things out there which can be classified as data. You should also think about what kind of Data is interesting for you.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore data collection approaches and tools for analytics and machinelearning projects. What is data collection?
MachineLearning Projects are the key to understanding the real-world implementation of machinelearning algorithms in the industry. It is because these apps render machinelearning models that try to understand the customer's taste. can help you model such machinelearning projects.
Wondering how to implement machinelearning in finance effectively and gain valuable insights? This blog presents the topmost useful machinelearning applications in finance to help you understand how financial markets thrive by adopting AI and ML solutions.
To anticipate maintenance requirements, manufacturers can use SLMs as tools that collect data from sensors mounted in machinery and equipment and analyze that data in real-time. This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata.
The Challenges of MedicalData In recent times, there have been several developments in applications of machinelearning to the medical industry. The incentives of the medical practitioners are sometimes misaligned with the incentives of the patients/clients.
Enter the world of data clean rooms – the super secure havens where you can mix and mingle data from different sources to get insights without getting your hands dirty with the rawdata. How data clean rooms work Data clean rooms combine and analyze different data sources without directly accessing the rawdata.
Sending out the exact old traditional style data science or machinelearning resume might not be doing any favours in your machinelearning job search. With cut-throat competition in the industry for high-paying machinelearning jobs, a boring cookie-cutter resume might not just be enough.
Professionals from a variety of disciplines use data in their day-to-day operations and feel the need to understand cutting-edge technology to get maximum insights from the data, therefore contributing to the growth of the organization.
The use of data by companies to understand business patterns and predict future occurrences has been on the rise. With the availability of new technologies like machinelearning, it has become easy for experts to analyse vast quantities of information to find patterns that will help establishments make better decisions.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machinelearning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of rawdata.
A quick recap of part i The evolution of a data pipeline In part I , we watched SmartGym grow into (version 2.1), an integrated health and fitness platform that streams , processes , and saves data from a range of gym equipment sensors and medical devices. With only one data source, consistency is implied.
The main techniques used here are data mining and data aggregation. Descriptive analytics involves using descriptive statistics such as arithmetic operations on existing data. These operations make rawdata understandable to investors, shareholders, and managers.
Next GEN Edge AI , also known as Edge Intelligence or next gen ai , combines Edge Computing and Artificial Intelligence to track and execute machinelearning. AI workflows at the edge use data originating from centralized data centers (cloud, devices) and data originating from human sources (edge).
To anticipate maintenance requirements, manufacturers can use SLMs as tools that collect data from sensors mounted in machinery and equipment and analyze that data in real-time. This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata.
This guide provides a comprehensive understanding of the essential skills and knowledge required to become a successful data scientist, covering data manipulation, programming, mathematics, big data, deep learning, and machinelearning technologies.
Data can be incomplete, inconsistent, or noizy, decreasing the accuracy of the analytics process. Due to this, data veracity is commonly classified as good, bad, and undefined. That’s quite a help when dealing with diverse data sets such as medical records, in which any inconsistencies or ambiguities may have harmful effects.
Introduction Explainable Artificial Intelligence (XAI) is a set of procedures and strategies that enables the output and consequences of MachineLearning algorithms to be understood and trusted by people. It can be a part of investigating problems with the model or the rawdata used to train it. When to Use What?
Data Scientist is a highly dynamic job and requires a person to be well-versed in AI, business intelligence, MachineLearning earning, etc. Learn more about it here. What Does a Data Scientist Do? You could receive ten different responses if you consult ten distinct Data Scientists with the same question.
Developed by the Google Brain Team, TensorFlow is an open-source platform that helps machinelearning engineers and data scientists build models and deploy applications easily. Deep Learning in Medical Imaging using TensorFlow 5. Now that we have emphasized (although perhaps not strongly enough!)
It offers data that makes it easier to comprehend how the company is doing on a global scale. Additionally, it is crucial to present the various stakeholders with the current rawdata. Drill-down, data mining, and other techniques are used to find the underlying cause of occurrences. Diagnostic Analytics.
What is the Role of Data Analytics? Data analytics is used to make sense of data and provide valuable insights to help organizations make better decisions. Data analytics aims to turn rawdata into meaningful insights that can be used to solve complex problems.
Big Data Use Cases in Industries You can go through this section and explore big data applications across multiple industries. Clinical Decision Support: By analyzing vast amounts of patient data and offering in-the-moment insights and suggestions, use cases for big data in healthcare helps workers make well-informed judgments.
It sits within the Apache Hadoop umbrella of solutions and facilitates the fast development of end-to-end Big Data applications. It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machinelearning that can be imported using Python or Scala.
Neural networks are a type of machine-learning model inspired by the human brain. They consist of interconnected layers of nodes (neurons) that process and learn from data by adjusting weights through training. Multiple levels: Rawdata is accepted by the input layer. What are neural networks?
Regression analysis is the favorite of data science and machinelearning practitioners as it provides a great level of flexibility and reliability making it an ideal choice for analyzing different situations like - Do educational degrees and IQ affect salary? Is consuming caffeine and smoking-related to mortality risk?
Patients can be given evidence-based treatment that has been identified and prescribed after reviewing previous medicaldata. In the healthcare industry, wearable gadgets and sensors have been launched that can transmit real-time data to a patient’s electronic health record. Apple is one such technology. Ingestion .
In this post, we’ll explain what deep learning is, how it works, how it’s different from traditional machinelearning, and what areas it can be applied within. Get ready because you’re about to go deep into deep learning. What is deep learning? Artificial intelligence vs machinelearning vs deep learning.
Classification is a prevalent supervised task of machinelearning. The algorithms are designed to classify the given data points into n number of different classes based on patterns observed within the data. How to Solve a Multi-Class Classification Problem on an Imbalanced Dataset?
Weather Tracker The weather tracker project involves visualizing historical weather data to provide insights into temperature trends, precipitation, and weather conditions. Weather data is abundant, and it offers unique variations and patterns. Grab info from a website using good APIs. Look for patterns in temperature.
Automation: Iterative tasks, such as creating, testing, and revising things, are automated with MachineLearning. In other words, it includes everything from the very first raw material to the development of the MachineLearning model that will be used. Data Wrangling.
Data augmentation is critical for boosting the performance of machinelearning models, particularly deep learning models. The quality, amount, and importance of training data are important for how well these models perform. One of the main problems with using machinelearning in real life is not having enough data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content