This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NoSQL databases are the new-age solutions to distributed unstructured data storage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies. Table of Contents HBase vs. Cassandra - What’s the Difference?
Data contracts and schema enforcement with dbt — It comes with dbt Mesh and gives a lot of new metadata over your models to bring more software engineering practices to dbt development. It's NoSQL database that is compliant with Apache Cassandra interfaces, and open-source. ScyllaDB raises $43M Series C.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. number of chunks).
Integration, metadata and governance capabilities glue the individual components together.”. In addition, we offer features for data and workload migration, and metadata management to meet the most stringent demands of our customers, across all environments. Forrester ).
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) For every data unit, the NameNode has to store metadata with names, access rights, locations, and so on. HDFS master-slave structure. Data storage options.
Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets. Although the HBase architecture is a NoSQL database, it eases the process of maintaining data by distributing it evenly across the cluster. Learn more about Apache HBase.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
Sentinel and Sherlocks Unified Approach to Data Governance The process kicks off with Sherlock AI, which scans both structured and unstructured data across SQL, NoSQL, SaaS, and cloud databases. Regulatory Alignment: Assists organizations in navigating compliance requirements such as GDPR, CCPA, HIPAA, and beyond.
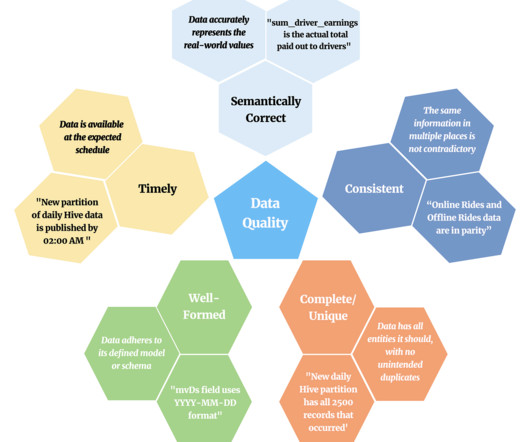
Check Result— The numeric measurement of data quality at a point in time, a boolean pass/fail value, and metadata about this run. Metadata — This includes a human-readable name, a universally unique identifier (UUID), ownership information, and tags (arbitrary semantic aggregations like ‘ML-feature’ or ‘business-reporting’).
It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. The data from your existing data warehouse is migrated to the storage option you choose, and all the metadata is migrated into SDX (Shared Data Experiences) layer of Cloudera Data Platform.
In this article, we’ll peel back the 5 layers that make up data lakehouse architecture: data ingestion, data storage, metadata, API, and data consumption, understand the expanded opportunities a data lakehouse opens up for generative AI, and how to maintain data quality throughout the pipeline with data observability. Metadata layer 4.
In this article, we’ll peel back the 5 layers that make up data lakehouse architecture: data ingestion, data storage, metadata, API, and data consumption, understand the expanded opportunities a data lakehouse opens up for generative AI, and how to maintain data quality throughout the pipeline with data observability. Metadata layer 4.
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. System Requirements Support for Structured Data The growth of NoSQL databases has broadly been accompanied with the trend of data “schemalessness” (e.g.,
This specialist supervises data engineers’ work and thus, must be closely familiar with a wide range of data-related technologies like SQL/NoSQL databases, ETL/ELT tools, and so on. This means a data architect should have a good grasp on the data lifecycle management (DLM) and understand the way metadata is used during each step of DLM.
DynamoDB is a popular NoSQL database available in AWS. However, DynamoDB, like many other NoSQL databases, is great for scalable data storage and single row retrieval but leaves a lot to be desired when it comes to analytics. A Flexible and Future-Proofed Solution It is clear that AWS DynamoDB is a great NoSQL database offering.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
There are databases, document stores, data files, NoSQL and ETL processes involved. They are at the intersection of the way we develop software, the way we manage data, metadata and the interactions between teams. If you evaluate architectures by how easy they are to extend, then this architecture gets an A+.
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Metadata layer. The schemas of structured and semi-structured datasets are kept in the metadata layer for the components to apply them to data while reading it.
When connecting, data virtualization loads metadata (details of the source data) and physical views if available. It maps metadata and semantically similar data assets from different autonomous databases to a common virtual data model or schema of the abstraction layer. The essential components of the virtual layer are. Informatica.
As a key-value NoSQL database, storing and retrieving individual records are its bread and butter. For those unfamiliar, DynamoDB makes database scalability a breeze, but with some major caveats.
Database Software- Other NoSQL: NoSQL databases cover a variety of database software that differs from typical relational databases. NoSQL is an abbreviation for "Not Only SQL," and it refers to non-relational databases that provide flexible data formats, horizontal scaling, and high performance for certain use cases.
NoSQL This database management system has been designed in a way that it can store and handle huge amounts of semi-structured or unstructured data. NoSQL databases can handle node failures. Pros: NoSQL can be used for real-time applications due to its ability to handle lots of reads and writes. It is also horizontally scalable.
NoSQL Stores: As source systems, Cassandra and MongoDB (including MongoDB Atlas), NoSQL databases are supported to make the integration of the unstructured data easy. Preserve Metadata Along with Data When copying data, you can also choose to preserve metadata such as column names, data types, and file properties.
Managing data and metadata. noSQL storages, cloud warehouses, and other data implementations are handled via tools such as Informatica, Redshift, and Talend. They set up resources required by the model, create pipelines to connect them with data, manage computer resources, and monitor and configure the model’s performance.
Mongo DB is a popular NoSQL and open-source document-oriented database which allows a highly scalable and flexible document structure. As a NoSQL solution, MongoDB is specifically designed to adeptly handle substantial volumes of data.
Step 3) Gain knowledge about databases Learn about databases and their management systems, like SQL and NoSQL databases. Step 6) Metadata Management Understand the importance of metadata (data about data) and how to manage it effectively. Proper metadata management helps in understanding, grouping, and sorting data.
Semi-structured data is typically stored in NoSQL databases, such as MongoDB, Cassandra, and Couchbase, following hierarchical or graph data models. Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage), NoSQL databases (e.g., A loose schema allows for some data structure flexibility while maintaining a general organization.
Skills Required Data architects must be proficient in programming languages such as Python, Java, and C++, Hadoop and NoSQL databases, predictive modeling, and data mining, and experience with data modeling tools like Visio and ERWin. Average Annual Salary of Data Architect On average, a data architect makes $165,583 annually.
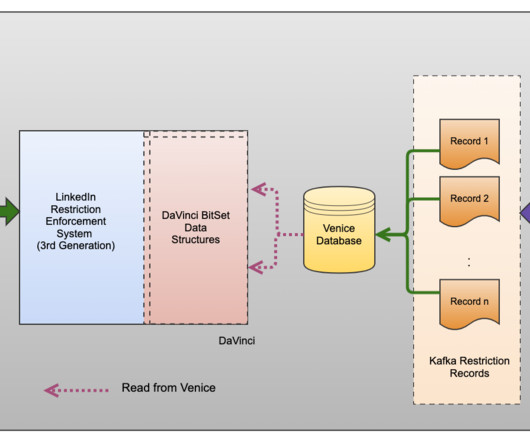
These records held vital metadata linked to the restriction, including essential timestamps. LinkedIn restriction enforcement system (2nd generation) First, we migrated all member restrictions data to Espresso , LinkedIn’s custom-built NoSQL distributed document storage solution. This strategic move streamlined our data management.
Forrester describes Big Data Fabric as, “A unified, trusted, and comprehensive view of business data produced by orchestrating data sources automatically, intelligently, and securely, then preparing and processing them in big data platforms such as Hadoop and Apache Spark, data lakes, in-memory, and NoSQL.”. Data processing and persistence.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. NoSQL, for example, may not be appropriate for message queues. NameNode is often given a large space to contain metadata for large-scale files. As you may know, the NameNode keeps metadata about the file system in RAM.
Data Catalog An organized inventory of data assets relying on metadata to help with data management. MapReduce MapReduce is a component of the Hadoop framework that’s used to access big data stored within the Hadoop File System Metadata A set of data that describes and gives information about other data.
First publicly introduced in 2010, Elasticsearch is an advanced, open-source search and analytics engine that also functions as a NoSQL database. Each document has unique metadata fields like index , type , and id that help identify its storage location and nature. What is Elasticsearch?
The NOSQL column oriented database has experienced incredible popularity in the last few years. HBase is a NoSQL , column oriented database built on top of hadoop to overcome the drawbacks of HDFS as it allows fast random writes and reads in an optimized way. HBase helps perform fast read/writes.
This requires implementing robust data integration tools and practices, such as data validation, data cleansing, and metadata management. Data storage platforms can include traditional relational databases, NoSQL databases, data lakes, or cloud-based storage services.
The system stores metadata about data which makes it easier to find and retrieve data. In a DBMS, once a set of metadata is stored in the database, it is difficult to change or update the metadata. Over time, the company decides to migrate its data to a more scalable and efficient NoSQL database system.
For storing data, use NoSQL databases as they are an excellent choice for keeping massive amounts of rapidly evolving organized/unorganized data. Neptune Neptune is a machine learning metadata repository designed for monitoring various experiments by research and production teams.
On top of existing data lakes like S3, ADLS, GCS, and HDFS, Delta Lake enables ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Furthermore, Cassandra is a NoSQL database in which all nodes are peers, rather than master-slave architecture.
NoSQL If you think that Hadoop doesn't matter as you have moved to the cloud, you must think again. Data Mining Tools Metadata adds business context to your data and helps transform it into understandable knowledge. Big resources still manage file data hierarchically using Hadoop's open-source ecosystem.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. You must have good knowledge of the SQL and NoSQL database systems.
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloud storage services — Amazon S3, Azure Blob, and Google Cloud Storage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Data processing systems like Hadoop ; and. You can find off-the-shelf links for.
They can be accumulated in NoSQL databases like MongoDB or Cassandra. Depending on the data format supported, NoSQL repositories can be document-based for JSON-like and JSON files (MongoDB, Amazon Document DB, and Elasticsearch); key-value, representing each data element as a pair of an attribute name or key (gender, color, price, etc.)
Does not have a dedicated metadata database. 9) Hive makes use of exact variation of the SQL DLL language by defining the tables beforehand and storing the schema details in any local database whereas in case of Pig there is no dedicated metadata database and the schemas or data types will be defined in the script itself.
Content-based systems largely depend on the metadata of items. This can be a standard SQL database for structured data, a NoSQL database for unstructured data, a cloud data warehouse for both, or even a data lake for Big Data projects. Users get limited to items similar to those they have previously consumed.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content