This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution. This guarantees data quality and automates the laborious, manual processes required to maintain data reliability.
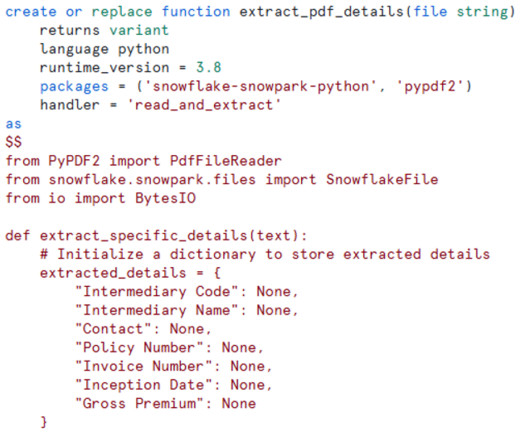
It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). It will be used to process and organize the text properly.
Its static snapshot and lack of detailed metadata limit modern applicability. While impressive in volume, it offers minimal metadata and prioritizes click-through rate (CTR) over recommendation logic. Netflix Prize A landmark dataset in recommendеr history (~100M ratings), though now dated. Yelp Open Dataset Contains 8.6M
Results are stored in git and their database, together with benchmarking metadata. Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
Snowflake provides powerful tools such as directory tables , streams , and Python UDFs to seamlessly process these files, making it easy to extract actionable insights. Pipeline Overview The pipeline consists of the following components: Stage : Stores PDF files and tracks their metadata using directory tables. PDF Extract Process 3.Automating
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. Recognize that artificial intelligence is a data governance accelerator and a process that must be governed to monitor ethical considerations and risk. Tools are important, but they need to complement your strategy.
Specifically, we have adopted a “shift-left” approach, integrating data schematization and annotations early in the product development process. However, conducting these processes outside of developer workflows presented challenges in terms of accuracy and timeliness.
Instead, to save space, the column values are implied until materialized through a read query and only then are the values propagated through the metadata layer (Metadata.json → Snapshot → Manifest → Datafile → Row). Entire tables can be encrypted with a single key, or access can be controlled at the snapshot level.
At Netflix, we embarked on a journey to build a robust event processing platform that not only meets the current demands but also scales for future needs. This blog post delves into the architectural evolution and technical decisions that underpin our Ads event processing pipeline.
While data products may have different definitions in different organizations, in general it is seen as data entity that contains data and metadata that has been curated for a specific business purpose. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used. Hack, C++, Python, etc.)
Managing application state and metadata Use Hybrid Tables as the system of record for application configuration, user profiles, workflow state and other metadata that needs to be accessed with high concurrency. Customers such as Siemens and PowerSchool are leveraging Hybrid Tables to track state for a wide variety of use cases.
For e.g., Finaccel, a leading tech company in Indonesia, leverages AWS Glue to easily load, process, and transform their enterprise data for further processing. It offers a simple and efficient solution for data processing in organizations. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog.
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Arroyo, a stream-processing platform, rebuilt their engine using DataFusion. This is Croissant. Starting today it will be supported by 3 majors platforms: Kaggle, HuggingFace and OpenML.
Strobelight is also not a single profiler but an orchestrator of many different profilers (even ad-hoc ones) that runs on all production hosts at Meta, collecting detailed information about CPU usage, memory allocations, and other performance metrics from running processes. Did someone say Metadata?
The manual process of switching between tools slows down their work, often leaving them reliant on rudimentary methods of keeping track of their findings. The metadata-driven approach ensures quick query planning so defenders don’t have to deal with slow processes when they need fast answers.
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. And how did we arrive at thispoint?
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Any delays in metadata retrieval can negatively impact user experience, resulting in decreased productivity and satisfaction.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Some of the major advantages of using PySpark are- Writing code for parallel processing is effortless.
Dynamic Tables updates Dynamic Tables provides a declarative processing framework for batch and streaming pipelines. This approach simplifies pipeline configuration, offering automatic orchestration and continuous, incremental data processing. The resulting data can be queried by any Iceberg engine.
You can also add metadata on models (in YAML). docs — in dbt you can add metadata on everything, some of the metadata is already expected by the framework and thank to it you can generate a small web page with your light catalog inside: you only need to do dbt docs generate and dbt docs serve.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. This results in a fast and scalable metadata handling system.
With an increasing amount of big data, there is a need for a service like ADF that can orchestrate and operationalize processes to refine the enormous stores of raw business data into actionable business insights. Activities: Activities represent a processing step in a pipeline. What are the steps involved in an ETL process?
The world of geospatial data processing is vast and complex, and were here to simplify it for you. While you can do time-series forecasting across any time-based data, enriching that forecasting with location data provides another value dimension in the forecasting process. Load the GeoTIFF file. Load the shapefile.
A key consideration for customers who find themselves in this scenario is to simplify as much as possible: choose platforms that provide a consistent experience, leverage tools that span multiple environments, and invest in open standards, technologies, and processes to ensure maximum flexibility now and in the future.
Customer intelligence teams analyze reviews and forum comments to identify sentiment trends, while support teams process tickets to uncover product issues and inform gaps in a product roadmap. Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. Cost: Reducing storage and processing expenses. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). Speed: Accelerating data insights.
REST Catalog Value Proposition It provides open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg client and metastore/engine integration. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore. spark.sql(SELECT * FROM airlines_data.carriers).show()
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
In this context, an individual data log entry is a formatted version of a single row of data from Hive that has been processed to make the underlying data transparent and easy to understand. Once the batch has been queued for processing, we copy the list of user IDs who have made requests in that batch into a new Hive table.
Then, a custom Apache Beam consumer processed these events, transforming and writing them to CRDB. link] Vimeo: Behind Viewer Retention Analytics at Scale Vimeo outlines its architecture for delivering viewer retention analytics at scale, leveraging ClickHouse and AI to process data from over a billion videos. and Lite 2.0)
Compaction is a process that rewrites small files into larger ones to improve performance. Users may want to perform table maintenance functions, like expiring snapshots, removing old metadata files, and deleting orphan files, to optimize storage utilization and improve performance.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in data lakes and lakehouses.
Challenge: Manual data quality processes don’t scale for AI and analytics The impact You’re dealing with more data – and complexity – than ever. If you’re still relying on manual processes to match, merge, and resolve data issues, then you’re spending too much time fixing errors and not enough time acting on insights.
A machine learning pipeline helps automate machine learning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. Increased Adaptability and Scope Although you require different models for different purposes, you can use the same functions/processes to build those models.
To address this, Dynamic CSV Column Mapping with Stored Procedures can be used to create a flexible, automated process that maps additional columns in the CSV to the correct fields in the Snowflake table, making the data loading process smoother and more adaptable. Metadata Proc Step 4: Execute the Stored Procedure.
These tools can be called by LLM systems to learn about your data and metadata. For AI agent workflows : Autonomously run dbt processes in response to events. The dbt MCP server provides access to a set of tools that operate on top of your dbt project. Consider starting in a sandbox environment or only granting read permissions.
Metadata Layer 3. Built to overcome the limitations of other table formats, such as Hive and Parquet , Iceberg offers powerful schema evolution, efficient data processing, ACID compliance, hidden partitioning, and optimized query performance across various compute engines, including Spark, Trino, Flink, and Presto. Iceberg Catalog 2.
An efficient data warehouse schema design can help organizations simplify their decision-making processes, identify growth opportunities, and better understand their business needs or preferences. Plan the ETL process for the data warehouse design. Identify relevant data sources. Define the data destination schema.
Moreover, since no actual data is copied or transferred between accounts — only Snowflake’s services layer and metadata store are used — sharing models reduces the risk of data exposure. Snowflake’s patented cross-cloud technology uses a replication-based approach to enable access to data in remote regions.
It derives its name “Beam” which is from “Batch” + “Stream” from its functionalities for both batch and streaming the parallel processing pipelines for data. It serves as a distributed processing engine for both categories of data streams: unbounded and bounded.
Conceptual data modeling refers to the process of creating conceptual data models. Physical data modeling is the process of creating physical data models. This is the process of putting a conceptual data model into action and extending it. The process of creating logical data models is known as logical data modeling.
The two most popular AWS data engineering services for processing data at scale for analytics operations are Amazon EMR and AWS Glue. EMR is a more powerful big data processing solution to provide real-time data streaming for machine learning applications. Executing ETL tasks in the cloud is fast and simple with AWS Glue.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content