This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Python, Angular, SSR, SQLite, DuckDB, Cockroach DB, and many others. Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There Tech stack.
Get ready to supercharge your data processing capabilities with Python Ray! Our tutorial teaches you how to unlock the power of parallelism and optimize your Python code for optimal performance. ​​Imagine This is where Python Ray comes in. Table of Contents What is Python Ray?
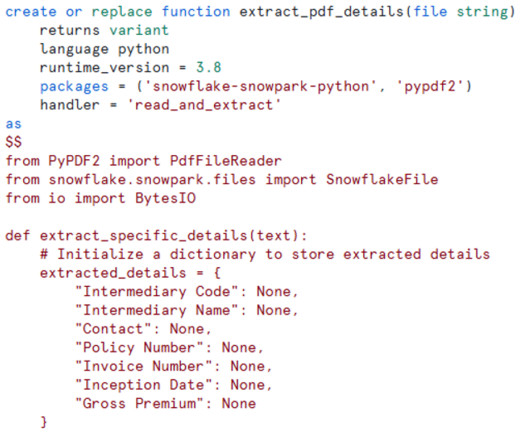
Snowflake provides powerful tools such as directory tables , streams , and Python UDFs to seamlessly process these files, making it easy to extract actionable insights. Pipeline Overview The pipeline consists of the following components: Stage : Stores PDF files and tracks their metadata using directory tables. newly added files).
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. After experiencing the impacts of fragmented metadata and previous attempts at building a solution Suresh Srinivas and Sriharsha Chintalapani created the OpenMetadata project.
Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. AWS Glue then creates data profiles in the catalog, a repository for all data assets' metadata, including table definitions, locations, and other features. For analyzing huge datasets, they want to employ familiar Python primitive types.
In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis. In this blog, you’ll learn how to build ETL pipeline in Python, the language most loved by data engineers worldwide. Python fits that role perfectly.
Avoid Python Data Types Like Dictionaries Python dictionaries and lists aren't distributable across nodes, which can hinder distributed processing. The distributed execution engine in the Spark core provides APIs in Java, Python, and Scala for constructing distributed ETL applications. dump- saves all of the profiles to a path.
Understanding DataSchema requires grasping schematization , which defines the logical structure and relationships of data assets, specifying field names, types, metadata, and policies. JSON) into fields and sub-fields, and extracting features using APIs available in multiple languages (C++, Python, Hack).
yato, is a small Python library that I've developed, yato stands for yet another transformation orchestrator. Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. This is Croissant.
Hack, C++, Python, etc.) We overcame this by developing reliable, computationally efficient, and widely applicable PAI libraries with built-in lineage collection logic in various programming languages (Hack, C++, Python, etc.). For simplicity, we will demonstrate these for the web, the data warehouse, and AI, per the diagram below.
You can also add metadata on models (in YAML). Jinja templating — Jinja is a templating engine that seems to exist forever in Python. You should also know that model are defined in.sql files and that the filename is the name of the model by default. You have to define sources in YAML files.
It uses low-cost, highly scalable data lakes for storage and introduces a metadata layer to manage data processing. It includes features such as metadata, caching, and indexing, and is compatible with processing engines like Apache Spark , Apache Hive, and Presto. This results in a fast and scalable metadata handling system.
The components are as follows: Data Analysis : The analysis component of the MLOps flow can be implemented using various tools and programming languages like Python and R. Focus on performing a preliminary analysis of the data using Python, leveraging pandas profiling and sweetviz. The source code for inspiration can be found here.
Python, Java, and Erlang). Did someone say Metadata? There are even folks who create dashboards from this metadata to help other engineers identify expensive copying, use of inefficient or inappropriate C++ containers, overuse of smart pointers, and much more. Function call count profilers. AI/GPU profilers.
Instagram has introduced Immortal Objects – PEP-683 – to Python. At Meta, we use Python (Django) for our frontend server within Instagram. Immortal Objects for Python This problem of state mutation of shared objects is at the heart of how the Python runtime works.
Youll use the Rasterio Python library to create functions that extract the GeoTIFF metadata, evaluate the bands present in the GeoTIFF and ultimately read and convert the centroid of each pixel into vector data (points). Then evaluate the metadata and convert the points to a data type in the proper SRID. Load the GeoTIFF file.
DEED In this post, we’ll cover how Lyft upgrades Python at scale — 1500+ repos spanning 150+ teams — and the latest iteration of the tools and strategy we’ve built to optimize both the overall time to upgrade and the work required from our engineers. linters) and libraries as they drop old Pythons or only work on the newest Pythons (e.g.
what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? __init__ covers the Python language, its community, and the innovative ways it is being used. Closing Announcements Thank you for listening!
Airflow DAG Python Apache Airflow DAG Dependencies Apache Airflow DAG Arguments How to Test Airflow DAGs? It is a Python script that defines and organizes tasks in a workflow. It is represented as a node in DAG and is written in Python. Core Concepts of Airflow DAGs Airflow DAGs Architecture How To Create Airflow DAGs?
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. __init__ covers the Python language, its community, and the innovative ways it is being used. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
Canva writes about its custom solution using dbt and metadata capturing to attribute costs, monitor performance, and enable data-driven decision-making, significantly enhancing its Snowflake environment management. link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure.
It even allows you to build a program that defines the data pipeline using open-source Beam SDKs (Software Development Kits) in any three programming languages: Java, Python, and Go. It uses NVIDIA CUDA primitives for basic compute optimization, while user-friendly Python interfaces exhibit GPU parallelism and great bandwidth memory speed.
I created a very basic dashboard that highlighted metadata by revenue source and date for the last 14 days. Thanks to Python, this can be achieved using a script with as few as 100 lines ofcode. If you know a bit of Python and LLM prompting you should be able to hack the code in an hour. Enter Tableau. The row count of thedata.
Last time I wrote about how we can use Python’s 1 abstract base classes to express useful concepts and primitives that are common in functional programming languages. In this final episode, I’ll cover testing strategies that can be learnt from functional programming and applied to your Python code. in functional programming ecosystems.
Getting Started with ChromaDB in Python How to Use Chroma DB? Along with the embeddings, you can also store metadata like the movie's title, genre, or release year. Collection: A container for storing embeddings and their associated metadata. Table of Contents What is Chroma DB? What is Chroma DB Used For?
Infrastructure layout Diagram illustrating the data flow between each component of the infrastructure Prerequisites Before you embark on this integration, ensure you have the following set up: Access to a Vantage instance: If you need a test instance of Vantage, you can provision one for free Python 3.10 dbt-core dagster==1.7.9 toml │ setup.
We have been making it easier and faster to build and manage ML models with Snowpark ML , the Python library and underlying infrastructure for end-to-end ML workflows in Snowflake. Many developers and enterprises looking to use machine learning (ML) to generate insights from data get bogged down by operational complexity.
Is python suitable for machine learning pipeline design patterns? Neptune Neptune is a machine learning metadata repository designed for monitoring various experiments by research and production teams. It comes with a customizable metadata format that lets you organize training and production info any way you desire.
REST Catalog Value Proposition It provides open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg client and metastore/engine integration. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore. spark.sql(SELECT * FROM airlines_data.carriers).show()
Management and Storage of Metadata 2. Experience Hands-on Learning with the Best Course for MLOps Management and Storage of MetadataMetadata refers to the details about the dataset you will use in a machine learning project. It automatically searches for the best hyperparameters by implementing algorithms in Python.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with —with Databricks you buy an engine.
Linked data technologies provide a means of tightly coupling metadata with raw information. If you’re a data person, you probably have to jump between different tools to run queries, build visualizations, write Python, and send around a lot of spreadsheets and CSV files. Hex brings everything together. Hex brings everything together.
Metadata Layer 3. Efficient Metadata Management uses a manifest and snapshot system to reduce query planning time and I/O overhead. Its architecture is centered around immutability and versioned metadata, enabling scalable operations with consistency and speed. It maintains references to the latest metadata file for each table.
Standardization of file formats, encodings, and metadata ensures consistency and smooth downstream processing. These databases employ indexing techniques like HNSW and FAISS , ensuring optimized search capabilities while preserving metadata and relationships between modalities.
__init__ covers the Python language, its community, and the innovative ways it is being used. __init__ covers the Python language, its community, and the innovative ways it is being used. Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
Setting up Python with Amazon Redshift Cluster 10. Using Apache Airflow with Python programming language, you can build a reusable and parameterizable ETL process that will digest data from the S3 bucket into Redshift. With this project, you can create a state machine that will start the series of the AWS Glue Python Shell jobs.
In this post, we describe a design for a Python monorepo: how we structure it; which tools we favor; alternatives that were considered; and some possible improvements. Python environments: one global vs many local Working on a Python project requires a Python environment (a.k.a. venv) > which python /some/path/.venv/bin/python
Scheduler Executors DAGs (Directed Acyclic Graphs) Web Server Metadata Database List of the Best Resources to Learn About Apache Airflow in 2025 Get Your Hands-On Learning Apache Airflow with ProjectPro! How to Learn about Metadata Database? How to Learn Airflow from Scratch? FAQs on How to Learn Airflow?
We’ll cover its setup, features, and architecture and show you how to implement a simple, scalable AI-powered similarity search solution using Python. Metadata is nothing but the contextual information associated with each vector embedding. tags or labels) to perform hybrid queries. tags or labels) to perform hybrid queries.
It works together with a LakeHouse architecture that combines the features of data warehouses and data lakes for metadata management and data governance. Databricks vs. Azure Synapse: Programming Language Support Azure Synapse supports programming languages such as Python, SQL, and Scala. Databricks supports Python, R, and SQL.
__init__ covers the Python language, its community, and the innovative ways it is being used. Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl Data’s vision is to bring clarity to your data through its next generation multi-cloud metadata management platform.
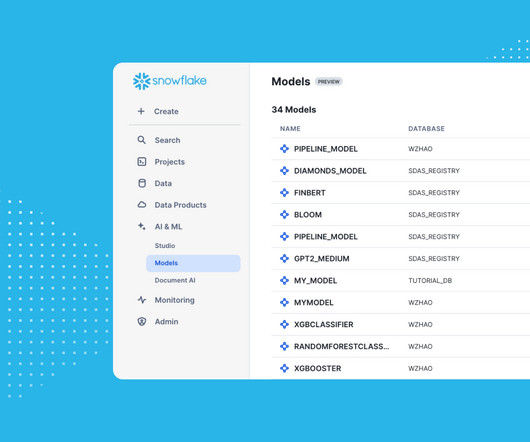
Teams can interact and manage these objects using Snowflake’s unified UI or from any notebook or IDE, using intuitive Python APIs. The Snowflake Model Registry , in general availability, provides a centralized repository to manage all models and their related artifacts and metadata.
PySpark User Defined Functions (UDFs) are custom functions created by users to extend the functionality of PySpark, a Python library for Apache Spark. Expressive Python Syntax: Leveraging PySpark UDFs allows you to use the concise and expressive syntax of Python, enhancing readability and ease of development for complex data processing tasks.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content