This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Benchmarking: for new server types identified – or ones that need an updated benchmark executed to avoid data becoming stale – those instances have a benchmark started on them. Results are stored in git and their database, together with benchmarking metadata. Then we wait for the actual data and/or final metadata (e.g.
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. Once we know what to query for a specific table, we create a task for each partition that executes a job in Dataswarm (our data pipeline system).
Not only is this data looked at by individual engineers to understand what the hottest functions and call paths are, but this data is also fed into monitoring and testing tools to identify regressions; ideally before they hit production. Did someone say Metadata? To add to that enchilada (hungry yet?),
Setting the Stage: We need E&L practices, because “copying rawdata” is more complex than it sounds. For instance, how would you know which orders got “canceled”, an operation that usually takes place in the same data record and just “modifies” it in place. But not at the ingestion level.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming rawdata into valuable insights. This is what managing data without metadata feels like.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
The fact tables then feed downstream intraday pipelines that process the data hourly. Rawdata for hours 3 and 6 arrive. Hour 6 data flows through the various workflows, while hour 3 triggers a late data audit alert. It leverages Iceberg metadata to facilitate processing incremental and batch-based data pipelines.
Metadata and evolution support : We’ve added structured-type schema evolution for flexibility as source systems or business reporting needs change. Get better Iceberg ecosystem interoperability with Primary Key information added to Iceberg table metadata.
Typically, the metadata around data lineage is usually incomplete or is buried in code that only a select few will have the capacity and patience to read. Downstream nodes like derived datasets, reports, dashboards, services and machine learning models may then need to be altered and/or re-computed to reflect upstream changes.
Data Ingestion. The rawdata is in a series of CSV files. We will firstly convert this to parquet format as most data lakes exist as object stores full of parquet files. Parquet also stores type metadata which makes reading back and processing the files later slightly easier. P2 GPU instances are not supported.
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. Why Use AWS Glue?
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
Data teams can use uniqueness tests to measure their data uniqueness. Uniqueness tests enable data teams to programmatically identify duplicate records to clean and normalize rawdata before entering the production warehouse.
Selecting the right data store solution for each aspect of the Data Lake is crucial, but the overarching technology decision involves tying together and exploring these stores to transform rawdata into downstream insights. This metadata is then utilized to manage, monitor, and foster the growth of the platform.
As organizations seek to leverage data more effectively, the focus has shifted from temporary datasets to well-defined, reusable data assets. Data products transform rawdata into actionable insights, integrating metadata and business logic to meet specific needs and drive strategic decision-making.
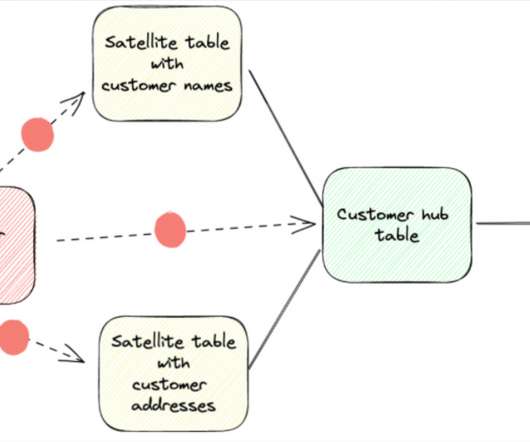
For those unfamiliar, data vault is a data warehouse modeling methodology created by Dan Linstedt (you may be familiar with Kimball or Imon models ) created in 2000 and updated in 2013. Data vault collects and organizes rawdata as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
While business rules evolve constantly, and while corrections and adjustments to the process are more the rule than the exception, it’s important to insulate compute logic changes from data changes and have control over all of the moving parts.
How many tables and views will be migrated, and how much rawdata? Are there redundant, unused, temporary or other types of data assets that can be removed to reduce the load? What is the best time to extract the data so it has minimal impact on business operations?
As we mentioned in our previous blog , we began with a ‘Bring Your Own SQL’ method, in which data scientists checked in ad-hoc Snowflake (our primary data warehouse) SQL files to create metrics for experiments, and metrics metadata was provided as JSON configs for each experiment.
To mitigate bias, organizations must take steps to ensure data quality and data governance: Data profiling is a data quality capability that helps you gain insight into the data select appropriate data subsets for training. Data discoverability is a key part of data governance.
According to the 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, 77% of data and analytics professionals say data-driven decision-making is the top goal of their data programs. That’s where data enrichment comes in.
dbt Explorer centralizes documentation, lineage, and execution metadata to reduce the work required to ship trusted data products faster. Knowing data lineage inherently increases your level of trust in the reporting you use to make the right decisions. Enter dbt Explorer ! Look at that lineage!
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance. Architecture overview. Separate storage.
Integration Layer : Where your data transformations and business logic are applied. Stage Layer: The Foundation The Stage Layer serves as the foundation of a data warehouse. Its primary purpose is to ingest and store rawdata with minimal modifications, preserving the original format and content of incoming data.
In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes. At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. I think it’s safe to say it’s getting pretty cold in here. Image courtesy of Dremio. So, is Iceberg right for you?
This could just as easily have been Snowflake or Redshift, but I chose BigQuery because one of my data sources is already there as a public dataset. dbt seeds data from offline sources and performs necessary transformations on data after it's been loaded into BigQuery. Let's dig into each data source one at a time.
One advantage of data warehouses is their integrated nature. As fully managed solutions, data warehouses are designed to offer ease of construction and operation. A warehouse can be a one-stop solution, where metadata, storage, and compute components come from the same place and are under the orchestration of a single vendor.
It’s designed to improve upon the performance and usability challenges of older data storage formats such as Apache Hive and Apache Parquet. For example, Monte Carlo can monitor Apache Iceberg tables for data quality incidents, where other data observability platforms may be more limited.
This can save time and effort for data engineers, and it can also help to ensure that ETL pipelines are more accurate and reliable. Generative AI with Data Lineage: By automating the process of collecting lineage metadata, generating visualizations of data lineage, and identifying and troubleshooting data lineage problems.
Most data governance tools today start with the slow, waterfall building of metadata with data stewards and then hope to use that metadata to drive code that runs in production. In reality, the ‘active metadata’ is just a written specification for a data developer to write their code.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Watch our video explaining how data engineering works.
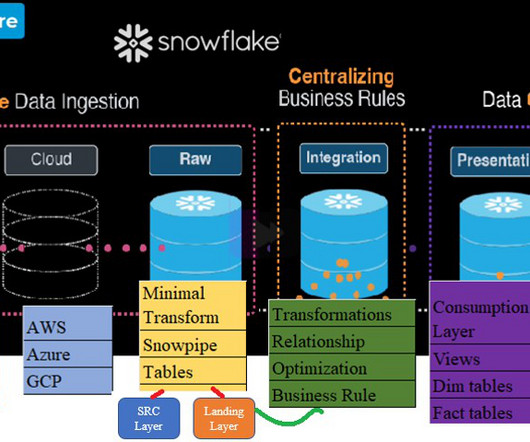
Secondly, Define Business Rules : Develop the transformation on RAWdata and include the Business logic. Develop the relationship among different sources table to produce meaningful data. Thirdly, Data Consumption: Develop the Views on Transformed or aggregated tables. Snowpipe to automate the ingestion process.
Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the data pipeline workload runs, like Databricks, BigQuery, and Snowflake.
Data Flow – is an individual data pipeline. Data Flows include the ingestion of rawdata, transformation via SQL and python, and sharing of finished data products. Data Plane – is the data cloud where the data pipeline workload runs, like Databricks, BigQuery, and Snowflake.
When the business intelligence needs change, they can go query the rawdata again. ELT: source Data Lake vs Data Warehouse Data lake stores rawdata. The purpose of the data is not determined. The data is easily accessible and is easy to update. x+ and set minimum memory to 5GB.
ETL Architecture on AWS: Examining the Scalable Architecture for Data Transformation ETL Architecture on AWS typically consists of three components - Source Data Store A Data Transformation Layer Target Data Store Source Data Store The source data store is where rawdata is stored before being transformed and loaded into the target data store.
Metadata Access: This level involves granting AI systems access to operational metadata, which includes information related to the day-to-day data operation. Learn how we use metadata to automate 90% of manual data pipeline maintenance.] [Learn how we use metadata to automate 90% of manual data pipeline maintenance.]
Source: Data Mesh Principles and Logical Architecture by Zhamak Dehghani What is a Data Fabric? Data fabric is a centralized platform architecture originating from a curated metadata layer that sits on top of an organization’s data infrastructure. Increasing speed.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content