This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. Hence, the metadata files record schema and partition changes, enabling systems to process data with the correct schema and partition structure for each relevant historical dataset.
To illustrate that, let’s take Cloud SQL from the Google Cloud Platform that is a “Fully managed relationaldatabase service for MySQL, PostgreSQL, and SQL Server” It looks like this when you want to create an instance. You can choose your parameters like the region, the version or the number of CPUs.
SnowConvert is an easy-to-use code conversion tool that accelerates legacy relationaldatabase management system (RDBMS) migrations to Snowflake. In addition to free assessments and free table conversions, SnowConvert now supports accurate conversion of database views from Teradata, Oracle or SQL Server for free.
Business transactions captured in relationaldatabases are critical to understanding the state of business operations. To avoid disruptions to operational databases, companies typically replicate data to data warehouses for analysis.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription TimescaleDB, from your friends at Timescale, is the leading open-source relationaldatabase with support for time-series data. Time-series data is relentless and requires a database like TimescaleDB with speed and petabyte-scale.
The way it works is that Monte Carlo feeds the LLM sample data, query log data, and other table metadata to build a deeper contextual understanding of the asset. GenAI Monitor Recommendations Lior announced, for the first time, new Monte Carlo capabilities, powered by GenAI models, that will automatically recommend data quality monitors.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) For every data unit, the NameNode has to store metadata with names, access rights, locations, and so on. HDFS master-slave structure. Complex programming environment.
Iceberg supports many catalog implementations: Hive, AWS Glue, Hadoop, Nessie, Dell ECS, any relationaldatabase via JDBC, REST, and now Snowflake. After making an initial connection to Snowflake via the Iceberg Catalog SDK, Spark can read Iceberg metadata and Parquet files directly from the customer-managed storage account.
Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. Furthermore, Glue supports databases hosted on Amazon Elastic Compute Cloud (EC2) instances on an Amazon Virtual Private Cloud, including MySQL, Oracle, Microsoft SQL Server, and PostgreSQL. Why Use AWS Glue? being data exactly matches the classifier, and 0.0
It frequently also means moving operational data from native mainframe databases to modern relationaldatabases. Typically, a mainframe to cloud migration includes re-factoring code to a modern object-oriented language such as Java or C# and moving to a modern relationaldatabase. Best Practice 2. Best Practice 3.
The original SKU catalog is a logic-heavy client library packaged with complex metadata configuration files and consumed by various services. Operational Efficiency: The majority of the changes require metadata configuration files and library code changes, usually taking days of testing and service release to adopt the updates.
What is Cloudera Operational Database (COD)? Operational Database is a relational and non-relationaldatabase built on Apache HBase and is designed to support OLTP applications, which use big data. The operational database in Cloudera Data Platform has the following components: .
Lineage metadata is the thread that connects it all together. However, there is more than one way to capture lineage metadata. How lineage metadata has traditionally been captured For most of us, lineage metadata is collected when we need it most: during an active investigation.
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. In NMDB we think of the media metadata universe in units of “DataStores”. A specific media analysis that has been performed on various media assets (e.g.,
It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. The data from your existing data warehouse is migrated to the storage option you choose, and all the metadata is migrated into SDX (Shared Data Experiences) layer of Cloudera Data Platform.
This guide will teach you the process of exporting data from a relationaldatabase (MySQL) and importing it into a graph database (Neo4j). You will learn how to take data from the relational system and to the graph by translating the schema and using Apache Hop as import tools.
Hands-on experience with a wide range of data-related technologies The daily tasks and duties of a data architect include close coordination with data engineers and data scientists. This means a data architect should have a good grasp on the data lifecycle management (DLM) and understand the way metadata is used during each step of DLM.
For governance and security teams, the questions revolve around chain of custody, audit, metadata, access control, and lineage. She needs to measure the streaming telemetry metadata from multiple manufacturing sites for capacity planning to prevent disruptions. Meet Laila, a very opinionated practitioner of Cloudera Stream Processing.
The author writes an overview of the performance implication of disaggregated systems compared to traditional monolithic databases. The author did an amazing job of describing how Parquet stores the data and compression and metadata strategies. link] All rights reserved ProtoGrowth Inc, India.
Photo by Shubham Dhage on Unsplash While data normalization holds merit in traditional relationaldatabases, the paradigm shifts when dealing with modern analytics platforms like BigQuery. If the keys are not enforced and this is not a relationaldatabase as we know it, what is the point?
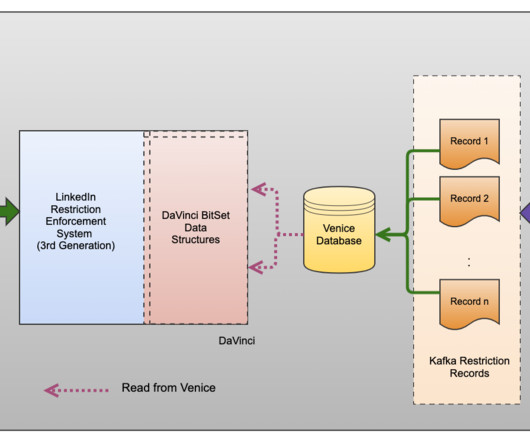
At the heart of this system was a reliance on a relationaldatabase, Oracle, which served as the repository for all member restrictions data. These records held vital metadata linked to the restriction, including essential timestamps.
Metadata Management Data modeling methodologies help in managing metadata within the data lake. Metadata describes the characteristics, attributes, and context of the data. By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake.
In this article, we’ll peel back the 5 layers that make up data lakehouse architecture: data ingestion, data storage, metadata, API, and data consumption, understand the expanded opportunities a data lakehouse opens up for generative AI, and how to maintain data quality throughout the pipeline with data observability. Metadata layer 4.
In this article, we’ll peel back the 5 layers that make up data lakehouse architecture: data ingestion, data storage, metadata, API, and data consumption, understand the expanded opportunities a data lakehouse opens up for generative AI, and how to maintain data quality throughout the pipeline with data observability. Metadata layer 4.
When connecting, data virtualization loads metadata (details of the source data) and physical views if available. It maps metadata and semantically similar data assets from different autonomous databases to a common virtual data model or schema of the abstraction layer. The essential components of the virtual layer are.
A Unified View for Operational Data We kept most of our operational data in relationaldatabases, like MySQL. For structured and hierarchical data, this feature lets us place related data close together, maximizing spatial locality. Fig 2: An overview of BigQuery’s disaggregation of storage, memory, and compute[13].
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. A data warehouse (DW) is a centralized repository for data accumulated from an array of corporate sources like CRMs, relationaldatabases , flat files, etc.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relationaldatabases , data warehouses , data lakes, data marts , IoT , legacy systems, etc., Data and metadata. Basic metadata can be structural, descriptive, and administrative.
It allows changes to be made at various levels of a database system without causing disruptions or requiring extensive modifications to the applications that rely on the data. In addition to data entered by users, database systems typically store large amounts of data. What is Data Independence of DBMS?
Database Software- Other NoSQL: NoSQL databases cover a variety of database software that differs from typical relationaldatabases. Key-value stores, columnar stores, graph-based databases, and wide-column stores are common classifications for NoSQL databases. Columnar Database (e.g.-
The structure of data is usually predefined before it is loaded into a warehouse, since the DW is a relationaldatabase that uses a single data model for everything it stores. In a nutshell, a model is a specific data structure a database can ingest. Enrichment with metadata is another important thing. Stambia data hub.
Data Catalog An organized inventory of data assets relying on metadata to help with data management. MapReduce MapReduce is a component of the Hadoop framework that’s used to access big data stored within the Hadoop File System Metadata A set of data that describes and gives information about other data.
You can also access data through non-relationaldatabases such as Apache Cassandra, Apache HBase, Apache Hive, and others like the Hadoop Distributed File System. Presto allows you to query data stored in Hive, Cassandra, relationaldatabases, and even bespoke data storage. However, Trino is not limited to HDFS access.
Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data. NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit.
The major difference between Sqoop and Flume is that Sqoop is used for loading data from relationaldatabases into HDFS while Flume is used to capture a stream of moving data. The data sources can refer to databases, machine data, web APIs, relationaldatabases, flat files, log files, and RSS (RDF Site Summary) feeds, to name a few.
Such an object storage model allows metadata tagging and incorporating unique identifiers, streamlining data retrieval and enhancing performance. These are the most organized forms of data, often originating from relationaldatabases and tables where the structure is clearly defined. This will simplify further reading.
The logical basis of RDF is extended by related standards RDFS (RDF Schema) and OWL (Web Ontology Language). They allow for representing various types of data and content (data schema, taxonomies, vocabularies, and metadata) and making them understandable for computing systems. A knowledge graph example. The future of knowledge graphs.
Databases: The most used relationaldatabase platforms, such as SQL Server, Oracle, MySQL, and PostgreSQL databases, are recognized both as source and sink platforms. Also integrated are the cloud-based databases, such as the Amazon RDS for Oracle and SQL Server and Google Big Query, to name but a few.
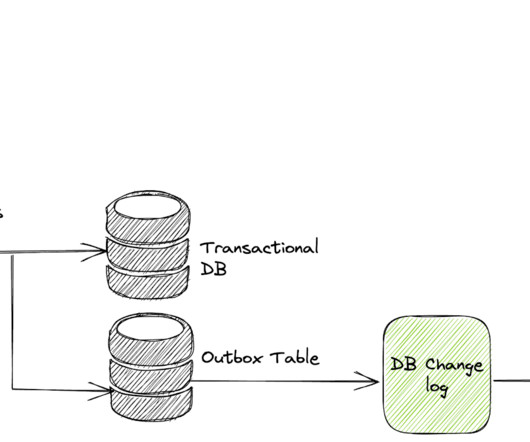
Drawback #1: Not Every Database Supports Transaction The relationaldatabase support transaction for multiple mutation statements. A typical outbox table will look like the following. As with any other system, the outbox pattern has its problems too. You can find more information about it by visiting [link].
Developed by the famous tech giant Microsoft, SQL Server is a durable DBMS that offers a vast range of features for the management of relationaldatabases. DML statements provide the means to interact with the database, perform data analysis, generate reports, and modify data as per the application requirements.
Instead of relying on time-consuming integrations, complicated pipelines, and hefty relationaldatabases, data consumers can tap into easily accessible and visualized data. Key components of a data fabric Metadata analysis Metadata is data about your data. Do you have quality metadata available to power your data fabric?
It offers a 360-degree view of your data, including data lineage, relationships, and rich metadata. It can connect to a broad range of source types, including relationaldatabases, file systems, and BI tools. Informatica’s data discovery tool also emphasizes collaboration, allowing teams to share data knowledge and insights.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content