This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
HDFS master-slave structure. A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Data management and monitoring options.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
Want to learn more about data governance? Check out our Data Governance on Snowflake blog! Metadata Management Data modeling methodologies help in managing metadata within the data lake. Metadata describes the characteristics, attributes, and context of the data.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. This comes with the advantages of reduction of redundancy, data integrity and consequently, less storage usage.
In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes. At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store.
What is data fabric? A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relationaldatabases , data warehouses , data lakes, data marts , IoT , legacy systems, etc., How data fabric works.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Hadoop Sqoop and Hadoop Flume are the two tools in Hadoop which is used to gather data from different sources and load them into HDFS. Sqoop in Hadoop is mostly used to extract structureddata from databases like Teradata, Oracle, etc., They enable the connection of various data sources to the Hadoop environment.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
Data Architecture Data architecture is a composition of models, rules, and standards for all data systems and interactions between them. Data Catalog An organized inventory of data assets relying on metadata to help with data management. Database A collection of structureddata.
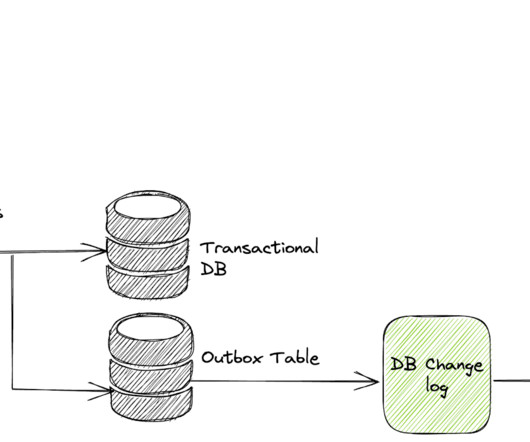
Drawback #1: Not Every Database Supports Transaction The relationaldatabase support transaction for multiple mutation statements. However, if you use systems like DynamoDB, the transaction support falls under the application or the Data Access Layer. However, Event sourcing comes with a few major limitations.
An ETL approach in the DW is considered slow, as it ships data in portions (batches.) The structure of data is usually predefined before it is loaded into a warehouse, since the DW is a relationaldatabase that uses a single data model for everything it stores.
DataFrames are used by Spark SQL to accommodate structured and semi-structureddata. You can also access data through non-relationaldatabases such as Apache Cassandra, Apache HBase, Apache Hive, and others like the Hadoop Distributed File System. However, Trino is not limited to HDFS access.
Hive- Performance Benchmarking Hive vs Pig Pig vs Hive - Differences Pig Hive Procedural Data Flow Language Declarative SQLish Language For Programming For creating reports Mainly used by Researchers and Programmers Mainly used by Data Analysts Operates on the client side of a cluster. Does not have a dedicated metadatadatabase.
From the perspective of data science, all miscellaneous forms of data fall into three large groups: structured, semi-structured, and unstructured. Key differences between structured, semi-structured, and unstructured data. Note, though, that not any type of web scraping is legal.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. Data is collected and stored in data warehouses from multiple sources to provide insights into business data. Data from data warehouses is queried using SQL.
But legacy systems and data silos prevent easy and secure data sharing. Snowflake can help life sciences companies query and analyze data easily, efficiently, and securely. Snowflake’s ability to scale compute resources easily and dynamically without limits, but only when needed, combines performance with cost-effectiveness.
NoSQL This database management system has been designed in a way that it can store and handle huge amounts of semi-structured or unstructured data. Avro creates binary data which can be both compressed as well as split. Avro creates a file that stores all the data and saves the schema in the metadata section.
This enrichment data has changing schemas and new data providers are constantly being added to enhance the insights, making it challenging for Windward to support using relationaldatabases with strict schemas. They used MongoDB as their metadata store to capture vessel and company data.
How HDFS master-slave structure works. A master node called NameNode maintains metadata with critical information, controls user access to the data blocks, makes decisions on replications, and manages slaves. You can change this parameter manually but the system won’t be able to effectively deal with myriads of tiny data pieces.
In the last few decades, we’ve seen a lot of architectural approaches to building data pipelines , changing one another and promising better and easier ways of deriving insights from information. There have been relationaldatabases, data warehouses, data lakes, and even a combination of the latter two.
Table of Contents Need for HBase HBase –Understanding the Basics HBase Architecture Explained Components of Apache HBase Architecture HMaster Region Server Zookeeper Need for HBase Apache Hadoop has gained popularity in the big data space for storing, managing and processing big data as it can handle high volume of multi-structureddata.
Sqoop is compatible with all JDBC compatible databases. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Apache Sqoop uses Hadoop MapReduce to get data from relationaldatabases and stores it on HDFS. It has a connector based architecture.
The prevailing part of users claim that it is quite easy to configure and manage data flows with Oracle’s graphical tools. Data profiling and cleansing. The tool supports all sorts of data loading and processing: real-time, batch, streaming (using Spark), etc. This works for both batch and real-time jobs. Pre-built connectors.
There is no guarantee that a company has a data-driven culture or is data-driven merely because it collects a great deal of data. In order to make informed decisions, organizations need to leverage data. . Types of Data in an Organization . A structureddata record consists of a very fixed field of data.
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. PySpark imports the StructType class from pyspark.sql.types to describe the DataFrame's structure. We can store the data and metadata in a checkpointing directory. appName('ProjectPro').getOrCreate()
Databases store key information that powers a company’s product, such as user data and product data. The ones that keep only relationaldata in a tabular format are called SQL or relationaldatabase management systems (RDBMSs). Data storage component in a modern data stack.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content