This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. Entity extraction : Extracting key entities (names, dates, locations, financial figures) from contracts, invoices or medical records to transform unstructured text into structureddata.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
Yet organizations struggle to pave a path to production due to an AI and data mismatch. LLMs excel at unstructured data, but many organizations lack mature preparation practices for this type of data; meanwhile, structureddata is better managed, but challenges remain in enabling LLMs to understand rows and columns.
To give customers flexibility for how they fit Snowflake into their architecture, Iceberg Tables can be configured to use either Snowflake or an external service like AWS Glue as the tables’s catalog to track metadata, with an easy one-line SQL command to convert to Snowflake in a metadata-only operation.
Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable. Can you describe what Unstruk Data is and the story behind it? How do you manage data enrichment/integration with structureddata sources?
Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., meeting recordings and videos), which contrasts with traditional SQL-centric systems for structureddata. The fundamental shift from traditional SQL-centric to AI-centric data processing further widened the efficiency gap.
When doing data collection from various sources, how do you ensure that intellectual property rights are respected? How do you determine the taxonomies to be used for structuringdata sets that are collected, labeled or enriched for your customers? What kinds of metadata do you track and how is that recorded/transmitted?
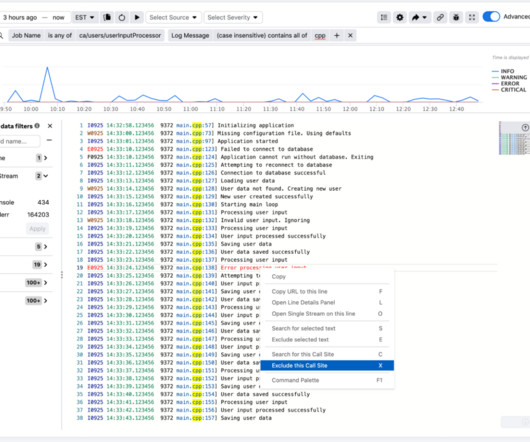
Users can query using regular expressions on log lines, arbitrary metadata fields attached to logs, and across log files of hosts and services. Logarithm’s data model Logarithm represents logs as a named log stream of (host-local) time-ordered sequences of immutable unstructured text, corresponding to a single log file. in PyTorch).
The script we use to generate DotSlash files injects metadata about the build job that makes it straightforward to trace the provenance of the underlying artifacts. The following is a hypothetical example of a generated DotSlash file for the CodeCompose LSP built from source at a specific commit in clang-opt mode.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
HDFS master-slave structure. A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Data management and monitoring options.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structureddata (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
Open Context is an open access data publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports. What are your protocols for determining which data sets you will work with?
Challenges & Opportunities in the Infra Data Space Security Events Platform for Anomaly Detection How can we develop a complex event processing system to ingest semi-structureddata predicated on schema contracts from hundreds of sources and transform it into event streams of structureddata for downstream analysis?
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform. Beyond there being a number of choices each with very different strengths, the parameters for your decision have also changed.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. Understanding the data sets to be replicated from the CDH Cluster.
The Unity Catalog is Databricks governance solution which integrates with Databricks workspaces and provides a centralized platform for managing metadata, data access, and security. Improved Data Discovery The tagging and documentation features in Unity Catalog facilitate better data discovery.
They were not able to quickly and easily query and analyze huge amounts of data as required. They also needed to combine text or other unstructured data with structureddata and visualize the results in the same dashboards. Events or time-series data served by our real-time events or time-series data store solutions.
Want to learn more about data governance? Check out our Data Governance on Snowflake blog! Metadata Management Data modeling methodologies help in managing metadata within the data lake. Metadata describes the characteristics, attributes, and context of the data.
To differentiate and expand the usefulness of these models, organizations must augment them with first-party data – typically via a process called RAG (retrieval augmented generation). Today, this first-party data mostly lives in two types of data repositories.
Understanding data warehouses A data warehouse is a consolidated storage unit and processing hub for your data. Teams using a data warehouse usually leverage SQL queries for analytics use cases. This same structure aids in maintaining data quality and simplifies how users interact with and understand the data.
Automation , because the same loader patterns are used for both and the same metadata tags are expected from both, meaning the applied date timestamp in the business vault will match up with the raw date timestamp where it came from. These methods can be applied to structured and semi-structureddata as well.
The curious reader might have noticed that a majority of these characteristics relate to properties of the data managed by NMDB. Specifically, structureddata that is modeled around the notion of a media timeline, with additional spatial properties. called “ N etflix M edia D ata B ase” (NMDB) that is used to address them.
The self-service functionally allows the entire organization to find relevant data faster and gain valuable insights. Support for different data types and use cases. A data fabric supports structured, unstructured, and semi-structureddata whether it comes in real-time or generated in batches. Data catalog.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structureddata.
With flexible schema and partitioning, Iceberg tables can scale to handle petabytes of data while compressing logs to save on storage costs. The metadata-driven approach ensures quick query planning so defenders don’t have to deal with slow processes when they need fast answers.
The field names should exactly match for Bulldozer to convert the structureddata entries into the key-value pairs. Users can use the protobuf schema KeyMessage and ValueMessage to deserialize data from Key-Value DAL as well. In this case, profile_id field is the key while email and age fields are included in the value schema.
In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes. At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store.
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. depending on location) BigQuery maintains a lot of valuable metadata about tables, columns and partitions.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. AWS Glue has a central metadata repository called the Glue catalog.
Managing structureddata in markdown is not ideal, despite the ability to use front matter for metadata. During the application review process it's indicated per application (from certain criticality tier onward) whether there are any playbooks defined for it and whether any of these are expired.
Instead of storing tables and columns, Neo4j represents all data as a graph, meaning that the data is a set of nodes with labels and relationships. Nodes are like our data entities (in this example, we use Person ). This approach to structuringdata is called the property graph model.
A combination of structured and semi structureddata can be used for analysis and loaded into the cloud database without the need of transforming into a fixed relational scheme first. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
Which is a great reason for Rockset to support SQL queries on PDF files, in our mission to make data more usable to everyone. Now add PDFs to the mix, and users can combine PDF data with data of other formats, from various sources, into their SQL analyses. . from the document along with the text.
Data Catalogs Can Drown in a Data Lake Although exceptionally flexible and scalable, data lakes lack the organization necessary to facilitate proper metadata management and data governance. Data discovery tools and platforms can help. Image courtesy of Adrian on Unsplash.
Hive- Performance Benchmarking Hive vs Pig Pig vs Hive - Differences Pig Hive Procedural Data Flow Language Declarative SQLish Language For Programming For creating reports Mainly used by Researchers and Programmers Mainly used by Data Analysts Operates on the client side of a cluster. Does not have a dedicated metadata database.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. AWS is one of the most popular data lake vendors.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content