This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew. The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. Entity extraction : Extracting key entities (names, dates, locations, financial figures) from contracts, invoices or medical records to transform unstructured text into structureddata.
Data Silos: Breaking down barriers between data sources. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., S3 Tables: A New Player?
AI agents, autonomous systems that perform tasks using AI, can enhance business productivity by handling complex, multi-step operations in minutes. Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. text, audio) and structured (e.g.,
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structureddata (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
Kirk Marple has spent years working with datasystems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable. The data you’re looking for is already in your data warehouse and BI tools. No more scripts, just SQL.
Learn practical strategies to optimize Airflow performance and streamline operations: - Fine-tune configurations to enhance workflow efficiency - Automate Airflow deployments and manage users seamlessly - Monitor system health with advanced observability tools and alerts Join this live session and learn how to scale Airflow efficiently.
To give customers flexibility for how they fit Snowflake into their architecture, Iceberg Tables can be configured to use either Snowflake or an external service like AWS Glue as the tables’s catalog to track metadata, with an easy one-line SQL command to convert to Snowflake in a metadata-only operation.
You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Personalization and recommender systems in a nutshell. Primarily developed to help users deal with a large range of choices they encounter, recommender systems come into play. Amazon, Booking.com) and.
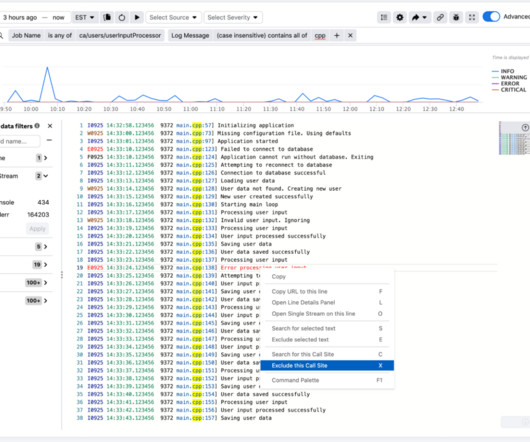
Systems and application logs play a key role in operations, observability, and debugging workflows at Meta. We designed the system to support service-level guarantees on log freshness, completeness, durability, query latency, and query result completeness. Each log line can have zero or more metadata key-value pairs attached to it.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline you’ll need somewhere to deploy it, so check out Linode. When doing data collection from various sources, how do you ensure that intellectual property rights are respected?
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
You don’t need to archive or clean data before loading. The system automatically replicates information to prevent data loss in the case of a node failure. To understand how the entire mechanism works, we need to get familiar with Hadoop structure and key parts. A file stored in the system ?an’t fail-safety.
DotSlash handles transparently fetching, decompressing, and verifying the appropriate remote artifact for the current operating system and CPU. Our continuous integration (CI) system supports special configuration for DotSlash jobs where a user must specify: A set of builds to run (these can span multiple platforms).
Open Context is an open access data publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports. What are your protocols for determining which data sets you will work with?
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability best practices, and a vast amount of informal knowledge about the cloud infrastructure.
For this reason, a new data management for ML framework has emerged to help manage this complexity: the “feature store.” Feature store As described in Tecton’s blog , a feature store is a data management system for managing ML feature pipelines, including the management of feature engineering code and data.
By enabling their event analysts to monitor and analyze events in real time, as well as directly in their data visualization tool, and also rate and give feedback to the system interactively, they increased their data to insight productivity by a factor of 10. .
Cyber defenders struggle with: Too much data: Cybersecurity tools generate an overwhelming volume of log data, including Domain Name Service (DNS) records, firewall logs, and more. All of this data is essential for investigations and threat hunting, but existing systems often struggle to manage it efficiently.
This blog will guide you through the best data modeling methodologies and processes for your data lake, helping you make informed decisions and optimize your data management practices. What is a Data Lake? What are Data Modeling Methodologies, and Why Are They Important for a Data Lake?
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. truncate or drop a table) this allows us to cheaply recycle old versions of the data.
In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes. At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , data lakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
the Media Timeline Data Model In the previous post in this series, we described some important Netflix business needs as well as traits of the media datasystem?—?called The curious reader might have noticed that a majority of these characteristics relate to properties of the data managed by NMDB.
And crucially, what does the future hold for data engineering in an AI-driven world? While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-quality data.
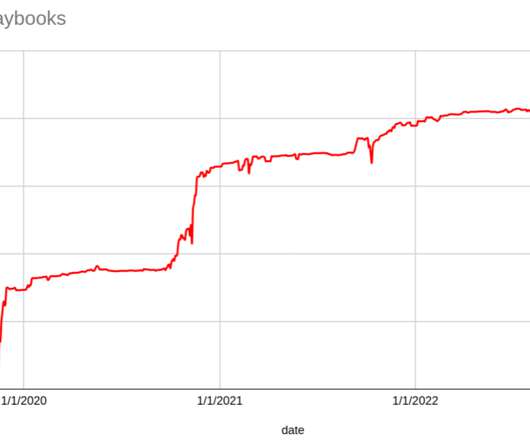
Our Incident Playbooks cover emergency procedures to initiate in case a certain set of conditions is met, for example when one of our systems is overloaded and the existing resiliency measures (e.g. When the bigger system context is considered, there are more options available to mitigate issues. processing of price updates).
The Data Lake architecture was proposed in a period of great growth in the data volume, especially in non-structured and semi-structureddata, when traditional Data Warehouse systems start to become incapable of dealing with this demand. The data became useless. delta_table.history().select("version",
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. depending on location) BigQuery maintains a lot of valuable metadata about tables, columns and partitions.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. AWS Glue has a central metadata repository called the Glue catalog.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structureddata.
Snapshot testing augments debugging capabilities by recording past table states, facilitating the identification of unforeseen spikes, declines, or abnormalities before their effect on production systems. Data freshness propagation: No automatic tracking of data propagation delays across multiplemodels.
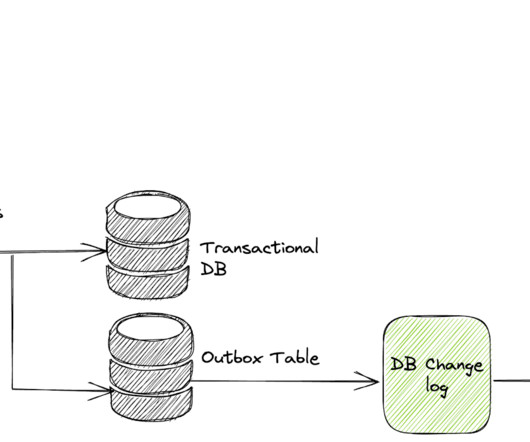
Data creation is often the differentiator between the success & the failure of a data team. A business process or workflow engine is a software system that enables businesses to execute well-defined steps to complete a user’s intention. Event Sourcing Change Data Capture [CDC] Outbox pattern 1.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Data Lake vs Data Warehouse - The Differences Before we closely analyse some of the key differences between a data lake and a data warehouse, it is important to have an in depth understanding of what a data warehouse and data lake is. Data Lake vs Data Warehouse - The Introduction What is a Data warehouse?
Here’s the final architecture: I’ve been doing some flavour of systems integration for the past 15 years, and usually I finish a project and think “it shouldn’t have taken that much effort”. For those unfamiliar, DynamoDB makes database scalability a breeze, but with some major caveats.
Parquet vs ORC vs Avro vs Delta Lake Photo by Viktor Talashuk on Unsplash The big data world is full of various storage systems, heavily influenced by different file formats. These are key in nearly all data pipelines, allowing for efficient data storage and easier querying and information extraction.
A Hadoop cluster is a group of computers called nodes that act as a single centralized system working on the same task. a client or edge node serves as a gateway between a Hadoop cluster and outer systems and applications. It loads data and grabs the results of the processing staying outside the master-slave hierarchy.
Key features Hadoop RDBMS Overview Hadoop is an open-source software collection that links several computers to solve problems requiring large quantities of data and processing. RDBMS is a part of system software used to create and manage databases based on the relational model. RDBMS stores structureddata.
Hive- Performance Benchmarking Hive vs Pig Pig vs Hive - Differences Pig Hive Procedural Data Flow Language Declarative SQLish Language For Programming For creating reports Mainly used by Researchers and Programmers Mainly used by Data Analysts Operates on the client side of a cluster. Does not have a dedicated metadata database.
The larger the company, the more data it has to generate actionable insights. Because it is scattered across disparate systems, hardly available for analytical apps. Evidently, common storage solutions fail to provide a unified data view and meet the needs of companies for seamless data flow. Data lake vs data hub.
” Artificial Intelligence AI is a broad term used to describe engineered systems that have been taught to do a task that typically requires human intelligence. BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content