This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, multiple copies of the same data locked in proprietary systems contribute to version control issues, redundancies, staleness, and management headaches. It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. General multi-stage recommendation system design in Pinterest.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
Results are stored in git and their database, together with benchmarking metadata. We recently covered how CockroachDB joins the trend of moving from open source to proprietary and why Oxide decided to keep using it with self-support , regardless Web hosting: Netlify : chosen thanks to their super smooth preview system with SSR support.
Investment in an Agent Management System (AMS) is crucial, as it offers a framework for scaling, monitoring, and refining AI agents. AI engineers, in particular, will find their skills in high demand as they navigate managing and optimizing agents to ensure reliability within enterprise systems.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
In this episode Ian Schweer shares his experiences at Riot Games supporting player-focused features such as machine learning models and recommeder systems that are deployed as part of the game binary. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Not only could this recommendation system save time browsing through lists of movies, it can also give more personalized results so users don’t feel overwhelmed by too many options. What are Movie Recommendation Systems? Recommender systems have two main categories: content-based & collaborative filtering.
Because there are so many different things happening in these systems powered by so many different technologies. Strobelight also has concurrency rules and a profiler queuing system. This provides just the right amount of data without impacting the profiled services or overburdening the systems that store Strobelight data.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. What is Atlas?
This will allow a data office to implement access policies over metadata management assets like tags or classifications, business glossaries, and data catalog entities, laying the foundation for comprehensive data access control. First, a set of initial metadata objects are created by the data steward.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data. Does it sound familiar?
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., If not handled correctly, managing this metadata can become a bottleneck.
WhyLogs is a powerful library for flexibly instrumenting all of your data systems to understand the entire lifecycle of your data from source to productionized model. You have full control over your data and their plugin system lets you integrate with all of your other data tools, including data warehouses and SaaS platforms.
The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it. Sifflet also offers a 2-week free trial. Sifflet also offers a 2-week free trial.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in data lakes and lakehouses.
The system leverages a combination of an event-based storage model in its TimeSeries Abstraction and continuous background aggregation to calculate counts across millions of counters efficiently. Grab has enhanced its LLM-powered data classification system, Metasense, to improve accuracy and minimize manual workload.
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. As data volumes grow and AI automation expands, cost efficiency in processing with LLMs depends on both system architecture and model flexibility.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. We also considered caching data logs in an online system capable of supporting a range of indexed per-user queries. What are data logs?
With the surge of new tools, platforms, and data types, managing these systems effectively is an ongoing challenge. Focus on metadata management. As Yoğurtçu points out, “metadata is critical” for driving insights in AI and advanced analytics. And context also enhances the large language models.
What are the other systems that feed into and rely on the Trino/Iceberg service? what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? Email hosts@dataengineeringpodcast.com with your story.
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Many of our customers use multiple solutions—but want to consolidate data security, governance, lineage, and metadata management, so that they don’t have to work with multiple vendors.
A compute engine is a system that transforms data 3.1.2. Metadata catalog stores information about datasets 3.1.3. Analytical databases aggregate large amounts of data 3. Most platforms enable you to do the same thing but have different strengths 3.1. Understand how the platforms process data 3.1.1.
Automated metadata management – AI-generated catalog asset descriptions significantly reduce manual efforts and improve metadata quality – enabling teams to focus on more strategic tasks. With the ability to turn functionality on or off based on business requirements, you gain full control over when and how AI is applied.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. VP of Architecture, Healthcare Industry Organizations will focus more on metadata tagging of existing and new content in the coming years.
He also describes the considerations involved in bringing behavioral data into your systems, and the ways that he and the rest of the Snowplow team are working to make that an easy addition to your platforms. Atlan is the metadata hub for your data ecosystem. What are some of the unique characteristics of that information?
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. If you want to build OLAP systems for low-latency complex queries, use Pinot. When to use Fluss vs Apache Pinot?
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps.
The commonly-accepted best practice in database system design for years is to use an exhaustive search strategy to consider all the possible variations of specific database operations in a query plan. Metadata Caching. See the performance results below for an example of how metadata caching helps reduce latency.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
To represent each Pin, we use the following varied set of text features derived from metadata, the image itself, as well as user-curated data. A diagram of the search relevance system at Pinterest is shown in Figure 3. Figure 3: Diagram of the proposed search relevance system at Pinterest.
On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Create a Plan for Integration: Automation tools need to work seamlessly with existing systems to be effective. Instead of driving innovation, data engineers often find themselves bogged down with maintenance tasks.
Even after gaining access, one needed to deal with the challenges of homogeneity across different assets in terms of decoding performance, size, metadata, and general formatting. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













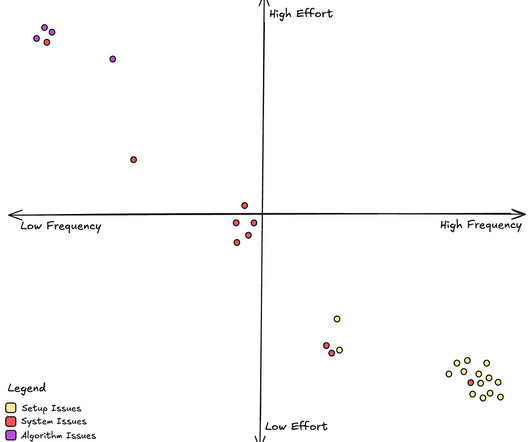



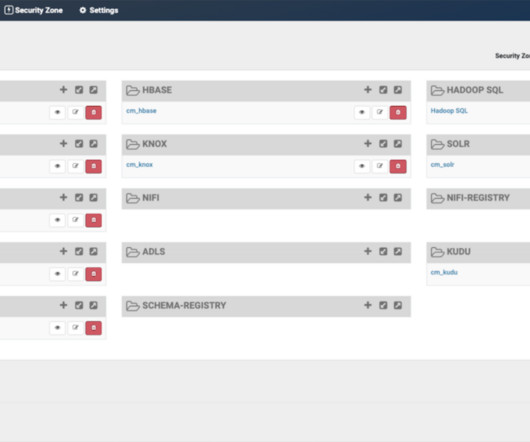













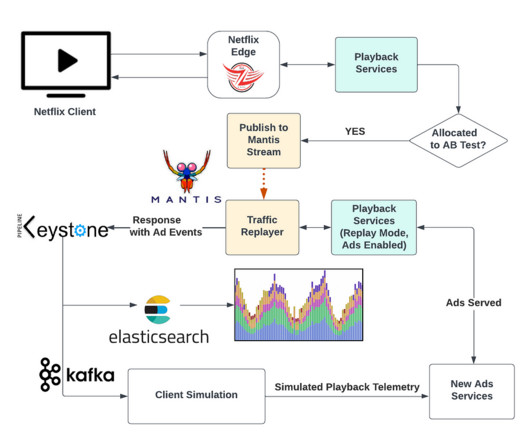



















Let's personalize your content