This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From driver and rider locations and destinations, to restaurant orders and payment transactions, every interaction on Uber’s transportation platform is driven by data.
The sidecar has been implemented by leveraging the highly performant eBPF along with carefully chosen transport protocols to consume less than 1% of CPU and memory on any instance in our fleet. The choice of transport protocols like GRPC, HTTPS & UDP is runtime dependent on characteristics of the instance placement.
how long it takes to execute an operation) and additional metadata like annotations and tags. For the translation service to correlate its spans with the caller service traces, it receives tracing metadata via context propagation (i.e., reading metadata injected into HTTP headers). Let’s imagine a “Hello, World!”
The Platform Integration Data Store Transformation Orchestration Presentation Transportation Observability Closing What’s changed? The future of the transportation layer seems destined to intersect with APIs, creating a scenario where API endpoints generated via SQL queries become as common as exporting .csv
In this model, we scan system logs and metadata generated by various compute engines to collect corresponding lineage data. In addition, we derive lineage information from scheduled ETL jobs by extracting workflow definitions and runtime metadata using Meson scheduler APIs. push or pull.
People need to get to work, go to the doctor, and get groceries, and it’s up to their local transportation department to ensure they make it to their destinations reliably. Similarly, transportation agencies reduce downtime through innovations like automatic inflating tire systems; so it’s about time we innovate too.
This multi-tenant service isolates the tenant metadata index, authorizing and filtering the search answer requests from every tenant. All communication across tenant-specific compute instances, the common services, and external interaction with your cloud data warehouse are secured over the transport layer security (TLS) channel.
Distributed Tracing: the missing context in troubleshooting services at scale Prior to Edgar, our engineers had to sift through a mountain of metadata and logs pulled from various Netflix microservices in order to understand a specific streaming failure experienced by any of our members.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
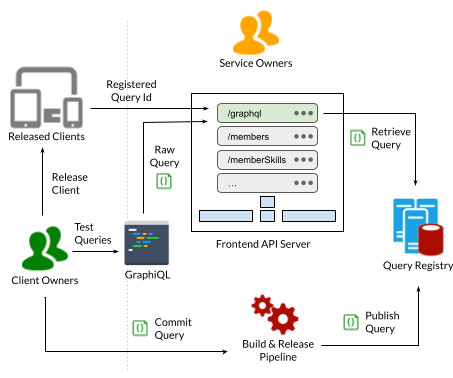
These data fetchers are written in a way to use the metadata available on our type system to self-configure and wire appropriately during the service startup. We achieved this by including routing metadata with each registered query. Before making any downstream call, the client inspects whether the target Rest.li
These apps may silently harvest personal data or metadata and, in some cases, install malware onto the device. While stealing a desktop computer in an office might be difficult, a smartphone can be easily snatched from a crowded restaurant or public transport.
In a nutshell you have: text based formats (CSV, JSON and raw stuff), columnar file formats (Parquet, ORC), memory format ( Arrow ), transport protocols and format (Protobuf, Thrift, gRPC, Avro), table formats ( Hudi, Iceberg, Delta ), database and vendor formats (Postgres, Snowflake, BigQuery, etc.). Is it really modern?
Multi-dimensional data model Similar to how Kubernetes labels infrastructure metadata, the model's structure is built on key-value pairs. Metrics are published via a standard HTTP transport, are readable by humans, and have formats that are self-explanatory. Kubernetes-pods: If the pod metadata is marked with prometheus.io/scrape
Data Encryption: Snowflake encrypts data at rest using AES 256-bit (or better) encryption and leverages Transport Layer Security (TLS) 1.2 (or When leveraged appropriately, Snowflake can and will empower FEs’ abilities to safeguard their sensitive financial data in compliance with their legal obligations. or better) for data in transit.
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. The major pieces, as shown in Fig.
System metadata is reviewed and updated regularly. Services in each zone use a combination of kerberos and transport layer security (TLS) to authenticate connections and APIs calls between the respective host roles, this allows authorization policies to be enforced and audit events to be captured. Sensitive data is encrypted.
Jeff Xiang | Software Engineer, Logging Platform Vahid Hashemian | Software Engineer, Logging Platform Jesus Zuniga | Software Engineer, Logging Platform At Pinterest, data is ingested and transported at petabyte scale every day, bringing inspiration for our users to create a life they love.
Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. AWS Glue then creates data profiles in the catalog, a repository for all data assets' metadata, including table definitions, locations, and other features. Why Use AWS Glue? being data exactly matches the classifier, and 0.0 doesn't match the classifier.
Youll use the Rasterio Python library to create functions that extract the GeoTIFF metadata, evaluate the bands present in the GeoTIFF and ultimately read and convert the centroid of each pixel into vector data (points). Then evaluate the metadata and convert the points to a data type in the proper SRID. Load the GeoTIFF file.
In this article we will cover gRPC which is a modern Open Source RPC framework designed by Google that uses Protocol Buffers for data serialization and HTTP/2 as a transport layer. Metadata provides access to read and write metadata values to be exchanged during a call. import cats.effect. import io.grpc. import fs2.Stream
Dynamic Workflow Executions For use cases where the need arises to execute a large/arbitrary number of varying workflow definitions or to run a one-time ad hoc workflow for testing or analytical purposes, registering definitions first with the metadata store in order to then execute them only once, adds a lot of additional overhead.
This process also creates a sqlite database for storing the metadata of the pipeline process. Initializing the InteractiveContext # This will create an sqlite db for storing the metadata context = InteractiveContext(pipeline_root=_pipeline_root) Next, we start with data ingestion.
For example, McKesson has been able to share near real-time data through Snowflake’s direct sharing capabilities with transportation partners. . “And Snowflake provides an avenue for collaboration through data interoperability.” Having a multi-cloud approach has many advantages beyond just BCDR,” said Potu.
This call includes metadata, such as the user’s information and details about the command, such as the specific show to play. Push Registry For most of its life, Pushy has used Dynomite for keeping track of device connection metadata in its Push Registry. This generalization paid off in terms of investment and operational support.
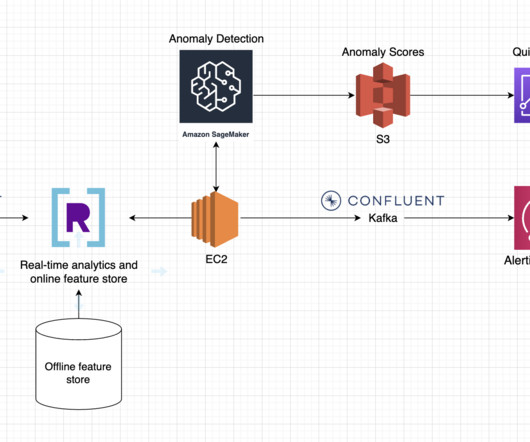
This architecture has a few key components: Streaming data : Streaming data is generated by website activity and transported to Rockset via Confluent Cloud. Polling : An EC2 instance periodically executes queries on the RTA database for features, feeds them into a machine learning model, and transports model results via Confluent Cloud.
The mechanisms by which the data is retrieved may not be inherently reliable (in the case of SNMP’s UDP transport) and always require active polling by the collector?—?which, The underlying transport for gNMI is, like most gRPC connections, HTTP/2 over TLS?—?so which, for time series data, must be driven by a strict clock.
It contains a detailed description of each operation performed, including all the metadata about the operation. View the history (logs) of the Delta Table The Log of the Delta Table is a record of all the operations that have been performed on the table. show() The history object is a Spark Data Frame. delta_table.history().select("version",
Take a look at the following diagram, which details the life-cycle of oil: Image taken from: [link] We have crude oil on the ground, which gets extracted by the oil rig; it then gets transported to the refinery, where it is modified according to the needs of different final consumers. Then, you have the oil tanker transporters.
With 90% of trade being transported via sea , this data is crucial to keeping the global supply chain on track but can be difficult to disentangle and take action on. They used MongoDB as their metadata store to capture vessel and company data. As a result, Windward wanted an underlying data stack that took an API first approach.
It houses metadata and both the desired and current state for each resource. So, if any other component needs to access information about the metadata or state of resources stored in the etcd, they have to go through the kube-apiserver. This ensures that all of the configurations are set correctly before being stored in the etcd.
The journal of records is usually an HTTP server that transports to further downstream consumers to process. Schemata combine a set of standard metadata definitions for each schema & data field and a scoring algorithm to provide a feedback loop on how efficient the data modeling of your data warehouse is.
In today’s data-driven world, machine learning models play a huge role in developing sectors like healthcare, finance, transport, e-commerce, and so on. Step 6) Metadata Management Understand the importance of metadata (data about data) and how to manage it effectively.
Data Catalog An organized inventory of data assets relying on metadata to help with data management. JSON JavaScript Object Notation – a data-interchange format for storing and transporting data. Data Engineering Data engineering is a process by which data engineers make data useful.
When it involves data transportation tasks within Azure Data Factory, Azure Integration Runtime is that the default choice. You’ll ensure dependable data transport and safeguard critical data by properly setting up the network environment. It offers scalable and effective means of transferring data between cloud data storage.
Precisely works with more than 130 data suppliers, and we hold all to the same high standards in relation to data quality, data structure, documentation and metadata, effective issue resolution, and product timing. Addresses : verified and validated property and address data for map display and analytics.
Cross-Cloud Snowgrid Account Replication expands replication beyond databases – general availability Account Replication, now generally available, expands replication beyond databases to account metadata and integrations, making business continuity truly turnkey.
CDC leverages streaming in order to track and transport changes from one system to another. Incremental updates (aka CDC) – as records change in A, emit a stream of changes that can be applied efficiently downstream in B. This method offers a few enormous advantages over batch updates.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
With wide applications in various sectors like healthcare, education, retail, transportation, media, and banking -data science applications are at the core of pretty much every industry out there. It also has to decide on the shipping method to minimize transportation costs while meeting the promised delivery date.
The diverse amplification of big data in all spheres of life, from commerce to transportation makes us realize how indispensable it is in our daily lives. Mutation profiling and the metadata of the patients are used to develop compounds that address the statistical correlation between the attributes.
They are responsible for the crucial tasks of gathering, transporting, storing, and configuring data infrastructure, which data scientists rely on for analysis and insights. Data engineers serve as the architects, laying the foundation upon which data scientists construct their projects.
BlaBlaCar is the largest transportation marketplace in Europe and Latin America for ride-sharing. The company started as a core app that connected drivers and passengers for carpooling, but today, they support multiple modes of transportation—and immense volumes of complex, peer-to-peer, geographic data. Here’s their story.
The Federation Gateway Instead of one service resolving and mapping all the requested data by calling downstream services via their transport method of choice, we let the services themselves define their own GraphQL endpoint and let them function as their own data resolvers. Schema fetching happens every 10 seconds by default.
Data integration Data integration is the process of transporting data from multiple disparate internal and external sources (including databases, server logs, third-party applications, and more) and putting it in a single location (e.g., Okay, data lives everywhere, and that’s the problem the second component solves.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content