This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
SkyHive platform Challenges with MongoDB for Analytical Queries 16 TB of raw text data from our web crawlers and other data feeds is dumped daily into our S3 data lake. That data was processed and then loaded into our analytics and serving database, MongoDB.
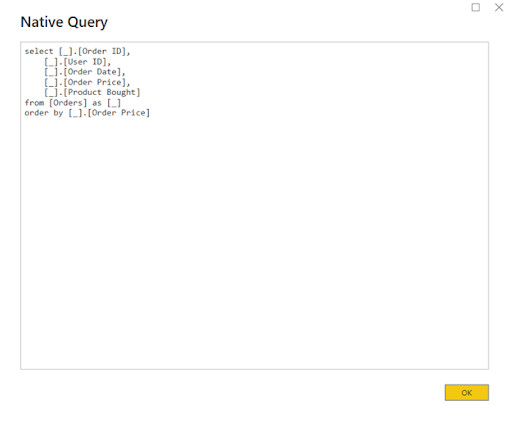
No Query Folding: It may occur when the Query has mappings that the language of the data source cannot overwrite. Hence, while using the Power Query, the rawdata is grabbed, and the work is done using the Power Query engine. Contents, Folder. Does Query Folding improve performance?
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains data architectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. Earlier we mentioned ETL or extract, transform, load.
A Quick Primer on Indexing in Rockset Rockset allows users to connect real-time data sources — data streams (Kafka, Kinesis), OLTP databases (DynamoDB, MongoDB, MySQL, PostgreSQL) and also data lakes (S3, GCS) — using built-in connectors. That is sufficient for some use cases.
A loose schema allows for some data structure flexibility while maintaining a general organization. Semi-structured data is typically stored in NoSQL databases, such as MongoDB, Cassandra, and Couchbase, following hierarchical or graph data models. MongoDB, Cassandra), and big data processing frameworks (e.g.,
Autonomous data warehouse from Oracle. . What is Data Lake? . Essentially, a data lake is a repository of rawdata from disparate sources. A data lake stores current and historical data similar to a data warehouse. Gen 2 Azure Data Lake Storage . Atlas Data Lake powered by MongoDB.
Once the data is tailored to your requirements, it then should be stored in a warehouse system, where it can be easily used by applying queries. Some of the most popular database management tools in the industry are NoSql, MongoDB and oracle. You will become accustomed to challenges that you will face in the industry.
Modern technologies allow gathering both structured (data that comes in tabular formats mostly) and unstructured data (all sorts of data formats) from an array of sources including websites, mobile applications, databases, flat files, customer relationship management systems (CRMs), IoT sensors, and so on.
Skills Required HTML, CSS, JavaScript or Python for Backend programming, Databases such as SQL, MongoDB, Git version control, JavaScript frameworks, etc. Albeit being extremely important, rawdata, in and of itself, can be time-consuming and subject to misinterpretation.
Data that is accessed together should be stored together Rick Houlihan Don’t muck with time series tables, just drop those things every day. Roll up the summary rawdata into summaries, maybe store the summary data in with your configuration data because that might be interesting depending on the access patterns.
That meant a system that was sufficiently nimble and powerful to execute fast SQL queries on rawdata, essentially performing any needed transformations as part of the query step, and not as part of a complex data pipeline. These pipelines implement windowing queries on new data and then update the serving layer.
The collection of meaningful market data has become a critical component of maintaining consistency in businesses today. A company can make the right decision by organizing a massive amount of rawdata with the right data analytic tool and a professional data analyst. Apache Spark. Apache Storm. Apache SAMOA.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn rawdata into formats that data consumers can use easily.
Also, there are NoSQL databases that can be home to all sorts of data, including unstructured and semi-structured (images, PDF files, audio, JSON, etc.) Some popular databases are Postgres and MongoDB. But this distinction has been blurred with the era of cloud data warehouses.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more. and its value (male, red, $100, etc.).
All of these assessments go back to the AI insights initiative that led Windward to re-examine its data stack. The steps Windward takes to create proprietary data and AI insights As Windward operated in a batch-based data stack, they stored rawdata in S3.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because rawdata is painful to read and work with.
Data science is a multidisciplinary field that combines computer programming, statistics, and business knowledge to solve problems and make decisions based on data rather than intuition or gut instinct. It requires mathematical modeling, machine learning, and other advanced statistical methods to extract useful insights from rawdata.
Python for Data Engineering Use Cases Data engineering, at its core, is about preparing “big data” for analytical processing. It’s an umbrella that covers everything from gathering rawdata to processing and storing it efficiently.
Exploratory Data Analysis (EDA Learn how to summarize and visualize data to identify trends and connections. Feature Engineering Examine techniques for handling categorical variables, transforming rawdata, and producing features to enhance model performance.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Big data technologies used: Microsoft Azure, Azure Data Factory, Azure Databricks, Spark Big Data Architecture: This sample Hadoop real-time project starts off by creating a resource group in azure. To this group, we add a storage account and move the rawdata.
It’s certainly no longer like 2000 when every startup picked Oracle to run their back-end store for whatever site they were building — in 2018 there’s a variety of different database or data store engines. There’s MongoDB for document stores. In the case of futures, where do you see things going?
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. MongoDB stores the processed and aggregated results.
E.g. Redis, MongoDB, Cassandra, HBase , Neo4j, CouchDB What is data modeling? Data modeling is a technique that defines and analyzes the data requirements needed to support business processes. Data engineers and data scientists work very closely together, but there are some differences in their roles and responsibilities.
Companies that were previously locked out of BEP and CEP began to harvest website user clickstreams, IoT sensor data, cybersecurity and fraud data, and more. Companies also started appending additional related time-stamped data to existing datasets, a process called data enrichment.
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for rawdata; a tool for large-scale data integration ; and. a suitable technology to implement data lake architecture.
Data transformation: Data Scientists carry out data transformation after collecting the data. For the computer to function effectively during the analysis process, this conversion involves changing the structure and content of the rawdata. Non-Technical Competencies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content