This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
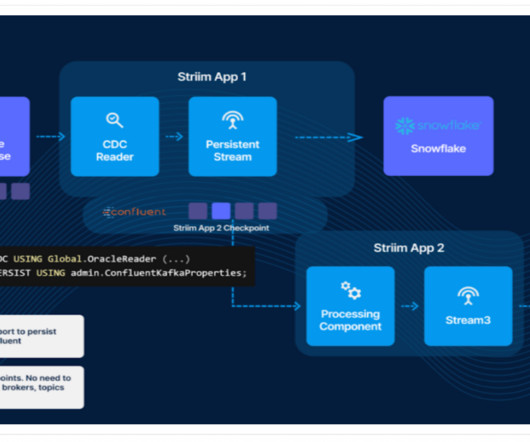
Native CDC for Postgres and MySQL — Snowflake will be able to connect to Postgres and MySQL to natively move data from your databases to the warehouse. This enables easier data management and query operations, making it possible to perform SQL-like operations and transactions directly on data files.
System Architecture Overview Setup We wanted to build a single data processing pipeline that would be efficient and scalable as more metrics are added. The data needed to compute our metrics came from various sources including MySQL databases, Kafka topics and Hadoop (HDFS). from the metric’s processing logic (i.e.
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Informatica Informatica is a leading industry tool used for extracting, transforming, and cleaning up rawdata. Features: Gives accurate insights and transforms rawdata Good data maintenance and monitoring Automated deployments Can execute multiple processes simultaneously 7.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
Data Engineer Data Engineers' responsibility is to process rawdata and extract useful information, such as market insights and trend details, from the data. Education requirements: Bachelor's degrees in computer science or a related field are common among data engineers.
Transform RawData into AI-generated Actions and Insights in Seconds In today’s fast-paced business environment, the ability to quickly transform rawdata into actionable insights is crucial. POS transactions training data span 79 days starting from (2024-02-01 to 2024-04-20).
A Quick Primer on Indexing in Rockset Rockset allows users to connect real-time data sources — data streams (Kafka, Kinesis), OLTP databases (DynamoDB, MongoDB, MySQL, PostgreSQL) and also data lakes (S3, GCS) — using built-in connectors. That is sufficient for some use cases.
While the numbers are impressive (and a little intimidating), what would we do with the rawdata without context? The tool will sort and aggregate these rawdata and transport them into actionable, intelligent insights. csv) – They are simplified text fields with rows of data. Comma-separated values (.csv)
Workspace is the platform where power BI developers create reports, dashboards, data sets, etc. Dataset is the collection of rawdata imported from various data sources for the purpose of analysis. Kmowledge on loading data from Excel, CSV, JSON, and other file formats.
Amazon Web Services (AWS) Databases such as MYSQL and Hadoop Programming languages, Linux web servers and APIs Application programming and Data security Networking. Albeit being extremely important, rawdata, in and of itself, can be time-consuming and subject to misinterpretation.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Semi-structured data sources. Rawdata store section.
Data warehousing emerged in the 1990s, and open-source databases, such as MySQL and PostgreSQL , came into play in the late 90s and 2000s. Let’s not gloss over the fact that SQL, as a language, remains incredibly popular, the lingua franca of the data world. Different flavors of SQL databases have been added over time.
SQL and SQL Server BAs must deal with the organization's structured data. They ought to be familiar with databases like Oracle DB, NoSQL, Microsoft SQL, and MySQL. BAs can store and process massive volumes of data with the use of these databases.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because rawdata is painful to read and work with. Below, we mention a few popular databases and the different softwares used for them.
Levels of Data Aggregation Now lets look at the levels of data aggregation Level 1: At this level, unprocessed data are collected from various sources and put in one source. Level 2: At this stage, the rawdata is processed and cleaned to get rid of inconsistent data, duplicates values, and error in datatype.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Python for Data Engineering Use Cases Data engineering, at its core, is about preparing “big data” for analytical processing. It’s an umbrella that covers everything from gathering rawdata to processing and storing it efficiently.
Analyzing data with statistical and computational methods to conclude any information is known as data analytics. Finding patterns, trends, and insights, entails cleaning and translating rawdata into a format that can be easily analyzed. These insights can be applied to drive company outcomes and make educated decisions.
A fixed schema means the structure and organization of the data are predetermined and consistent. It is commonly stored in relational database management systems (DBMSs) such as SQL Server, Oracle, and MySQL, and is managed by data analysts and database administrators.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Entry-level data engineers make about $77,000 annually when they start, rising to about $115,000 as they become experienced. Roles and Responsibilities of Data Engineer Analyze and organize rawdata. Build data systems and pipelines. Conduct complex data analysis and report on results.
Power BI shines as the preferred choice among professionals for converting rawdata into useful knowledge because of its user-friendly interface and comprehensive features. This is one of the most important best practices for effective Power BI usage.
Your SQL skills as a data engineer are crucial for data modeling and analytics tasks. Making data accessible for querying is a common task for data engineers. Collecting the rawdata, cleaning it, modeling it, and letting their end users access the clean data are all part of this process.
The collection of meaningful market data has become a critical component of maintaining consistency in businesses today. A company can make the right decision by organizing a massive amount of rawdata with the right data analytic tool and a professional data analyst.
Big data technologies used: Microsoft Azure, Azure Data Factory, Azure Databricks, Spark Big Data Architecture: This sample Hadoop real-time project starts off by creating a resource group in azure. To this group, we add a storage account and move the rawdata.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role.
Non-relational databases are ideal if you need flexibility for storing the data since you cannot create documents without having a fixed schema. E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server. E.g. Redis, MongoDB, Cassandra, HBase , Neo4j, CouchDB What is data modeling? Hadoop is a user-friendly open source framework.
Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. Data that can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi-structured data.
You may learn to work with the following RDBMS': MySQL SQL Server PostgreSQL Step 4: Learn to handle series data It is important that you learn how to handle large sets of data, especially from financial streams. Organization of rawdata is another important factor that you should learn as a financial data scientist.
The issue is how the downstream database stores updates and late-arriving data. Traditional transactional databases, such as Oracle or MySQL, were designed with the assumption that data would need to be continuously updated to maintain accuracy. It also prevents data bloat that would hamper storage efficiency and query speeds.
Data transformation: Data Scientists carry out data transformation after collecting the data. For the computer to function effectively during the analysis process, this conversion involves changing the structure and content of the rawdata. Data Scientist Skills. Non-Technical Competencies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


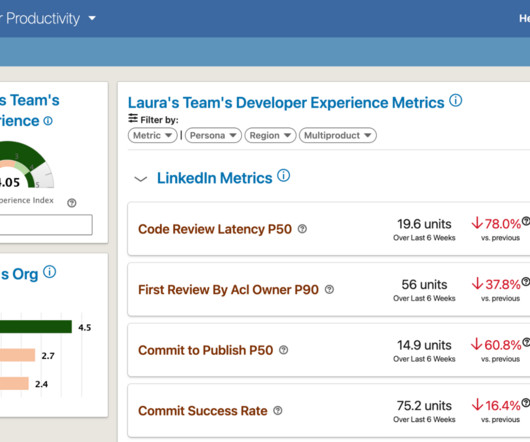



































Let's personalize your content