This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase.
__init__ Episode Kubernetes Operator Scala Kafka Abstract Syntax Tree Language Server Protocol Amazon Deequ dbt Tecton Podcast Episode Informatica The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Support Data Engineering Podcast
ScalaScala has become one of the most popular languages for AI and data science use cases. Because it is statically typed and object-oriented, Scala has often been considered a hybrid language used for data science between object-oriented languages like Java and functional ones like Haskell or Lisp.
MongoDB Certified Developer Associate Exam MongoDB is a NoSQL, document-based high-volume heterogeneous database system. It requires prerequisite knowledge of Scala and Python. It has different courses on Big Data Analytics, Apache Storm, Hadoop Administration, Apache Spark & Scala, Big Data with Hadoop, and more.
Apache HBase , a noSQL database on top of HDFS, is designed to store huge tables, with millions of columns and billions of rows. Alternatively, you can opt for Apache Cassandra — one more noSQL database in the family. Written in Scala, the framework also supports Java, Python, and R. Some components of the Hadoop ecosystem.
ScalaScala has become one of the most popular languages for AI and data science use cases. Because it is statically typed and object-oriented, Scala has often been considered a hybrid language used for data science between object-oriented languages like Java and functional ones like Haskell or Lisp.
They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase. They need deep expertise in technologies like SQL, Python, Scala, Java, or C++. In other words, they develop, maintain, and test Big Data solutions.
This specialist supervises data engineers’ work and thus, must be closely familiar with a wide range of data-related technologies like SQL/NoSQL databases, ETL/ELT tools, and so on. Also, they must have in-depth knowledge of data processing languages like Python, Scala, or SQL.
Handling databases, both SQL and NoSQL. Proficiency in programming languages, including Python, Java, C++, LISP, Scala, etc. Databases and tools: AI engineers must be adept at working with different forms of data and know how to handle SQL and NoSQL databases. Helped create various APIs, respond to payload requests, etc.
Data engineers are well-versed in Java, Scala, and C++, since these languages are often used in data architecture frameworks such as Hadoop, Apache Spark, and Kafka. noSQL storages, cloud warehouses, and other data implementations are handled via tools such as Informatica, Redshift, and Talend. Let’s go through the main areas.
MongoDB NoSQL database is used in the big data stack for storing and retrieving one item at a time from large datasets whereas Hadoop is used for processing these large data sets. Image Credit : compassitesinc.com Another aftermath of the above problems was the parallel advent of “Not Only SQL” or NoSQL databases.
Java Big Data requires you to be proficient in multiple programming languages, and besides Python and Scala, Java is another popular language that you should be proficient in. Kafka, which is written in Scala and Java, helps you scale your performance in today’s data-driven and disruptive enterprises.
Learn Key Technologies Programming Languages: Language skills, either in Python, Java, or Scala. Databases: Knowledgeable about SQL and NoSQL databases. Projects: Engage in projects with a component that involves data collection, processing, and analysis. Big Data Technologies: Aware of Hadoop, Spark, and other platforms for big data.
Other Competencies You should have proficiency in coding languages like SQL, NoSQL, Python, Java, R, and Scala. Creating NoSQL Database with MongoDB and Compass or Database Design with SQL Server Management Studio (SSMS) You should have the expertise to enter Database Creation and Modeling using MYSQL Workbench.
Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering. Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential.
An open-spurce NoSQL database management program, MongoDB architecture, is used as an alternative to traditional RDMS. Since MongoDB does not store or retrieve data in the form of columns, it is referred to as a NoSQL (Not Just SQL) database. js, Perl, PHP, Python, Motor, Ruby, Scala, Swift, and Mongoid. Introduction.
Java, JavaScript, and Python are examples, as are upcoming languages like Go and Scala. SQL, NoSQL, and Linux knowledge are required for database programming. Certain widely used programming languages lend themselves well to cloud-based technologies.
While the exact AI engineer responsibilities depend on where you work and what you work on, some fundamental ones include Working on the application backend with programming languages like Python, Lisp, JavaScript, Scala, etc. Working with LLMs (large language models) to solve real-world problems, etc.
NoSQL is a distributed data storage that is becoming increasingly popular. Some of NoSQL examples are Apache River, BaseX, Ignite, Hazelcast, Coherence, etc. As a Data engineer, you need to be quite proficient in SQL and NoSQL. They are experts in coding in programming languages like Python, Java, Scala, C++.
Skills: Develop your skill set by learning new programming languages (Java, Python, Scala), as well as by mastering Apache Spark, HBase, and Hive, three big data tools and technologies. How to Improve Hadoop Developer Salary? Think about the following tactics to increase your Hadoop Developer salary: 1.
A competent candidate will also be able to demonstrate familiarity and proficiency with a range of coding languages and tools, such as JavaScript, Java, and Scala, as well as Git, another popular coding tool. Besides, it would help if you also had a grasp on non-relational databases (NoSQL) and relational databases (SQL).
Querying and data extraction language HQL SQL Speed Slower in comparison with Spark as Hive runs on top of Hadoop Faster operational and computational speeds Implementation language It is possible to implement the tool on Java Implementation is possible on multiple languages, such as Python, R, Scala, and Java Server Operating Systems All OSs with (..)
A Data Engineer is someone proficient in a variety of programming languages and frameworks, such as Python, SQL, Scala, Hadoop, Spark, etc. NoSQL databases are often implemented as a component of data pipelines. Also, they need to be familiar with ETL. One of the primary focuses of a Data Engineer's work is on the Hadoop data lakes.
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Machine learning engineer: A machine learning engineer is an engineer who uses programming languages like Python, Java, Scala, etc. A machine learning engineer or ML engineer is an information technology professional.
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! Here’s what’s happening in data engineering right now. Cassandra 4.0
Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Release – The first major release of NoSQL database in five years! Here’s what’s happening in data engineering right now. Cassandra 4.0
This demand and supply gap has widened the big data and hadoop job market, creating a surging demand for big data skills like Hadoop, Spark, NoSQL, Data Mining, Machine Learning, etc. Knowledge of Hadoop, Spark, Scala, Python, R NoSQL and traditional RDBMS’s along with strong foundation in math and statistics.
As a result, several eLearning organizations like ProjectPro, Coursera, Edupristine and Udacity are helping professionals update their skills on the widely demanded big data certifications like Hadoop, Spark, NoSQL, etc. that organizations urgently need.
Another main aspect of this position is database design (RDBMS, NoSQL, and NewSQL), data warehousing, and setting up a data lake. The Data Scientist’s Toolbox Data scientists should be proficient with such programming languages such as Python, R, SQL, Java, Julia , Apache Spark and Scala, as computer programming is a huge part.
Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, data pipelines, and related database concepts.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. Apache Kafka is an open-source, distributed streaming platform for messaging, storing, processing, and integrating large data volumes in real time. You can find off-the-shelf links for.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. NoSQL, for example, may not be appropriate for message queues. When is it appropriate to use a NoSQL database? When working with large amounts of data, NoSQL databases are an excellent choice. may be used with it.
It helps organizations understand big data and helps in collecting, storing, and analyzing vast amounts of data, using technical skills related to NoSQL, SQL, and hybrid infrastructures. They are experts who have a thorough knowledge of SQL data storing and MongoDB NoSQL data warehousing.
Step 1) Learn Programming Language Start by choosing a programming language you’re comfortable with, such as Python, Java, Scala, or Ruby. Step 3) Gain knowledge about databases Learn about databases and their management systems, like SQL and NoSQL databases.
The most popular databases for which data analysts need to be proficient are SQL and NoSQL databases. Programming Languages: Data analysts should be fluent in programming languages like Scala and Java, which are frequently used for big data processing utilizing tools like Apache Hadoop and Apache Spark, as big data becomes more pervasive.
Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Develop working knowledge of NoSQL & Big Data using MongoDB, Cassandra, Cloudant, Hadoop, Apache Spark, Spark SQL, Spark ML, and Spark Streaming 18. Cost: $400 USD 4.
Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. To become a Microsoft Certified Azure Data Engineer, you must thoroughly understand data computation languages like SQL, Python, or Scala and parallel processing and data architecture concepts. What is the most popular Azure Certification?
The key to cost control with EMR is data processing and Apache Spark, a popular framework for handling cluster computing tasks in parallel mode that can provide high-level APIs written in Java, Scala, or Python enabling large dataset manipulation, helping you take your business process big data closer into a performant way of digital addressing.
To ensure that the data is reliable, consistent, and easily accessible, data engineers work with various data storage platforms, such as relational databases, NoSQL databases, and data warehouses. Data engineers must know about big data technologies like Hive, Spark, and Hadoop.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























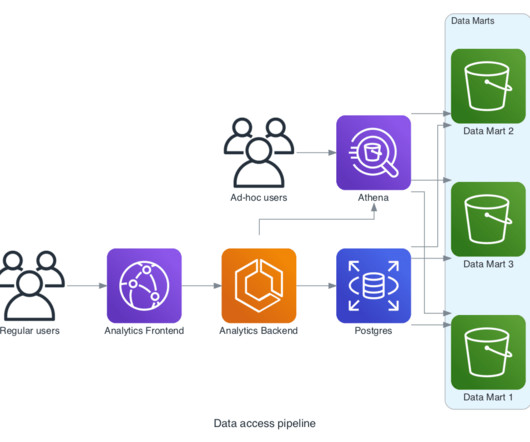
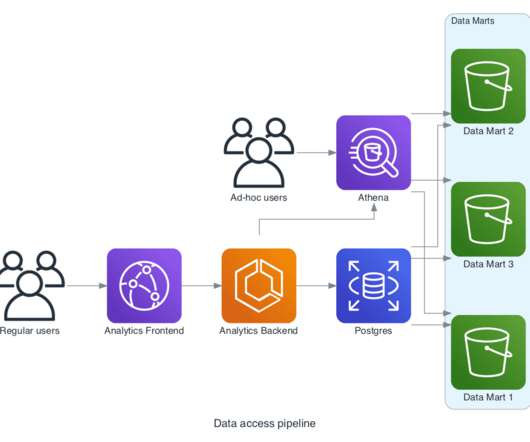



















Let's personalize your content