This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric. They work in and on these pipelines.
Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly data pipeline maintenance. By implementing data replication from the IBM Z, the team was able to build data pipelines to distributed targets, ensuring that each application use case could be supported.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. meeting recordings and videos), which contrasts with traditional SQL-centric systems for structured data. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g.,
How does the focus on data assets/data products shift your approach to observability as compared to a table/pipelinecentric approach? How does the focus on data assets/data products shift your approach to observability as compared to a table/pipelinecentric approach?
Ideal for: Business-centric workflows involving fabric Snowflake = environments with a lot of developers and data engineers 2. Ideal for: Fabric: Microsoft-centric organizations Snowflake: Multi-cloud flexibility seekers 3. Cloud support Microsoft Fabric: Works only on Microsoft Azure.
This traditional SQL-centric approach often challenged data engineers working in a Python environment, requiring context-switching and limiting the full potential of Python’s rich libraries and frameworks. The post Snowflake’s New Python API Empowers Data Engineers to Build Modern Data Pipelines with Ease appeared first on Snowflake.
We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. However, this architecture is not without its challenges.
CDP Data Engineering offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual profiling, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. . A key aspect of ETL or ELT pipelines is automation.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team.
The list of Top 10 semi-finalists is a perfect example: we have use cases for cybersecurity, gen AI, food safety, restaurant chain pricing, quantitative trading analytics, geospatial data, sales pipeline measurement, marketing tech and healthcare. Our sincere thanks go out to everyone who participated in this year’s competition.
One thing that stands out to me is As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches.
However, that's also something we're re-thinking with our warehouse-centric strategy. Rudderstack]([link] RudderStack provides all your customer data pipelines in one platform. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
Although I wasn’t aware of all the hype, the Data-Centric AI Community promptly came to the rescue: The 2.0 There is nothing worst for a data flow than wrong typesets , especially within a data-centric AI paradigm. In the new release, users can rest to sure that their pipelines won’t break if they’re using pandas 2.0,
At EVOLVE in Singapore, the Manila Electric Company, Meralco , won the Cloudera 2024 Data Impact Award in the Leadership and Transformation category for its customer-centric and data-driven transformation. But, what is the ultimate impact of all this effort and investment on each of us in our daily lives?
Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Pipeline breakpoint feature. I like testing people on their practical knowledge rather than artificial coding challenges. Swiggy recently wrote about its internal platform, Hermes, a text-to-SQL solution.
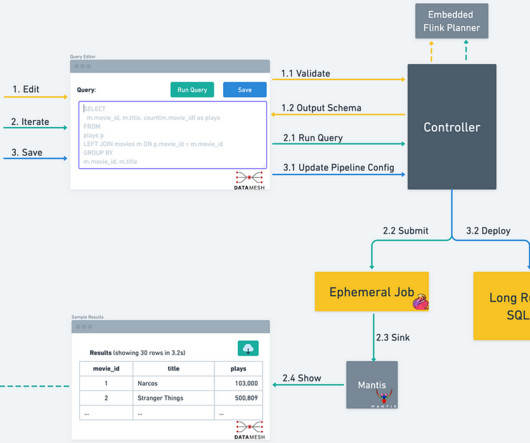
When a user wants to leverage Data Mesh to move and transform data, they start by creating a new Data Mesh pipeline. The pipeline is composed of individual “Processors” that are connected by Kafka topics. Furthermore, many pipelines needed to be composed of multiple Processors. Overview of the SQL Processor workflow.
Summary How much time do you spend maintaining your data pipeline? How does the data-centric approach of DataCoral differ from the way that other platforms think about processing information? How does the data-centric approach of DataCoral differ from the way that other platforms think about processing information?
The first response has been frustration because of the chaos a breach like this causes: At a scaleup I talked with, infrastructure teams shut down all pipelines in order to replace secrets. Our customers are some of the most innovative, engineering-centric businesses on the planet, and helping them do great work will continue to be our focus.”
You are starting to be an operation or technology centric data team. How to build Data Products or never call me Data Pipeline any more You have this interesting schema in her second article on Data Mesh by Zhamak Dehghani : “Data mesh introduces the concept of data product as its architectural quantum.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. Data stacks are becoming more and more complex.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams. Job Deployment Made Simple.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing.
The resulting solution was SnowPatrol, an OSS app that alerts on anomalous Snowflake usage, powered by ML Airflow pipelines. link] Adevinta: How we moved from local scripts and spreadsheets shared by email to Data Products Data Product Thinking Shaping the data management to build a reliable, customer-centric data application.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. I hope he will fill the gaps. In the first part he treats about the history of modeling and the main concepts. When it comes to modeling it's hard not to mention dbt.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. I hope he will fill the gaps. In the first part he treats about the history of modeling and the main concepts. When it comes to modeling it's hard not to mention dbt.
Next, it needed to enhance the company’s customer-centric approach for a needs-based alignment of products and services. We are positive that our continuing partnership with Cloudera and Blutech Consulting will be foundational to our customer-centric approach, considerably improving our customer responsiveness,” he said.
Sometimes they need feedback on touchpoints very quickly, while other pipelines don’t need as much acceleration. Acadia, a digital media agency, wanted to accelerate end-to-end pipeline for its clients while also enhancing security for clients’ PII. One conversation quickly coming to the forefront is first-party data.
Key Themes Data-Driven Decision-Making : Learn how to build a data-centric culture that drives better outcomes. If youre attending, be sure to stop by Booth #219 to learn more about how data observability can enable your team to build AI-ready pipelines. Its a unique blend of business and technical expertise under one roof.
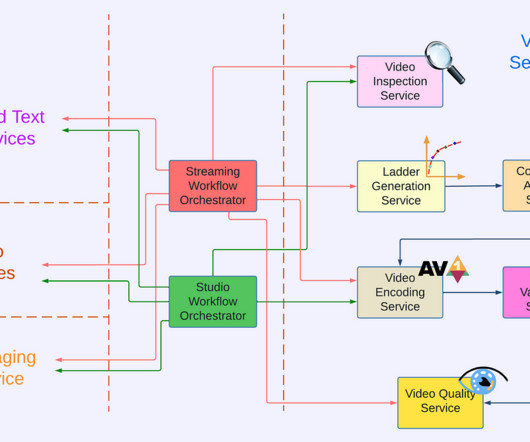
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Look at details of volumes/buckets/keys/containers/pipelines/datanodes. Given a file, find out what nodes/pipeline is it part of. Seamlessly scale the architecture to thousands of nodes with a single pane of glass management using Cisco Application Centric Infrastructure (ACI).
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced data pipelines. To realize this cohesive data vision, LGIM adopted Cloudera Data Platform (CDP) Public Cloud.
Since it’s all part of Snowflake’s single platform, data engineers and developers can also perform inference by programmatically calling the built-in or fine-tuned models, like in pipelines with Streams and Tasks or in applications. Learn More: Learn more about how Snowflake is building a data-centric platform for generative AI and LLM.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
The data pipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. Perhaps more importantly, data engineers and scientists may change any part of the automated pipelines related to data at any time. That’s the power of DataOps automation.
2) Why High-Quality Data Products Beats Complexity in Building LLM Apps - Ananth Packildurai I will walk through the evolution of model-centric to data-centric AI and how data products and DPLM (Data Product Lifecycle Management) systems are vital for an organization's system.
It involves many moving parts, from data preparation to building indexing and query pipelines. Building an indexing pipeline at scale with Kafka Connect. Always keep an eye on their performance and make sure they run in the expected time to allow your pipeline to function properly. Scaling indexing. Interested in more?
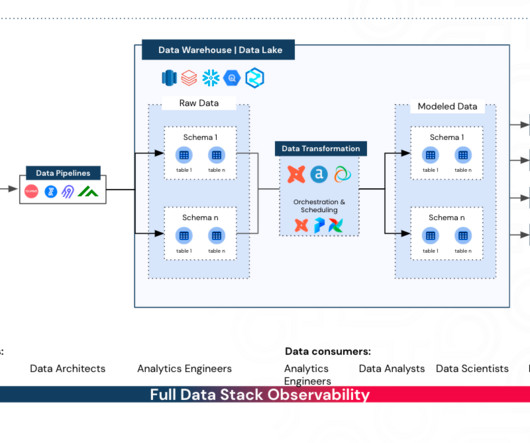
This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use. Roughly, the operations in a data pipeline consist of the following phases: Ingestion — this involves gathering in the needed data. A data scientist is only as good as the data they have access to.
Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets. Data Cascades are said to be pervasive, to lack immediate visibility, but to eventually impact the world in a negative manner. Conclusions.
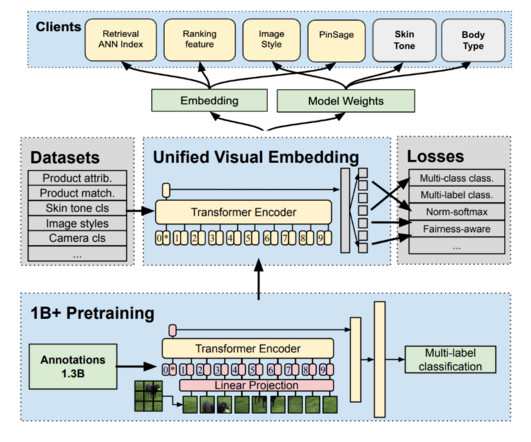
These external partnerships along with our internal fashion specialists and labellers were fundamental in helping us design the experience from both a technical and human-centric perspective. The resulting structured dataset becomes the foundation to train and evaluate the machine learning model known as the body type signal.
But this article is not about the pricing which can be very subjective depending on the context—what is 1200$ for dev tooling when you pay them more than $150k per year, yes it's US-centric but relevant. But before sending your code to production you still want to validate some stuff, static or not, in the CI/CD pipelines.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization.
These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The data pipelines must contend with a high level of complexity – over seventy data sources and various cadences, including daily/weekly updates and builds.
Data engineers spend countless hours troubleshooting broken pipelines. Data plays a central role in modern organisations; the centricity here is not just a figure of speech, as data teams often sit between traditional IT and different business functions. Every “minor” change upstream results in mayhem. trillion to the U.S.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. The author writes about integrating uwheel with DataFusion (a query engine for building high-quality data-centric systems in Rust , using the Apache Arrow in-memory format).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content