This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
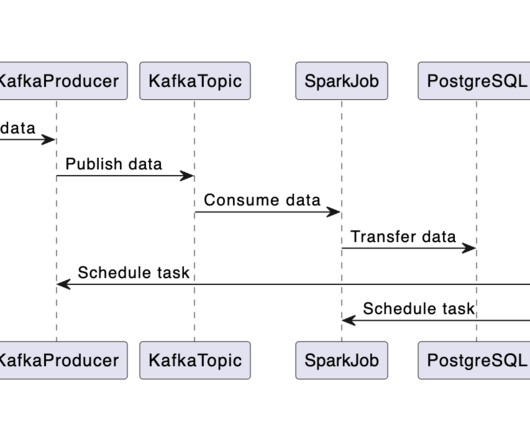
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. Serving a web page.
Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. Check out the agenda and register today at Neo4j.com/NODES.
In this episode Lukas Fittl shares some hard-won wisdom about the causes and solution of many performance bottlenecks and the work that he is doing to shine some light on PostgreSQL to make it easier to understand how to keep it running smoothly. Go to [materialize.com]([link] today and get 2 weeks free! Datafold : , m.
This blog will demonstrate to you how Hasura and PostgreSQL can help you accelerate app development and easily launch backends. In this blog, we will cover: GraphQL Hasura PostgreSQL Hands-on Conclusion GraphQL GraphQL is an API query language and runtime for answering queries with existing data. Why Hasura is Fast?
From governance processes to costly tools to dbt implementationdata quality projects never seem to want to besmall. And would you believe all of this was available to us since the release of PostgreSQL 6.5 Set up a development and testing process e.g. development environment, version control,CI/CD. Precise decimal handling.
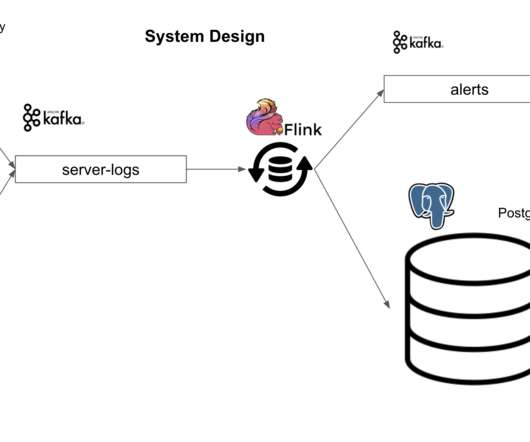
Cloudera has a strong track record of providing a comprehensive solution for stream processing. Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. Cloudera Stream Processing Community Edition.
The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing. The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Optimizing the server initialization process for Atlas is vital for maintaining the high availability and performance of the ThoughtSpot system.
Many organizations are drawn to PostgreSQL’s robust features, open-source nature, and cost-effectiveness, and hence they look to migrate their data from their existing database to PostgreSQL. In this guide, we’ll discuss the Oracle to PostgreSQL migration process.
PostgreSQL and MySQL are among the most popular open-source relational database management systems (RDMS) worldwide. For all of their similarities, PostgreSQL and MySQL differ from one another in many ways. That’s because MySQL isn’t fully SQL-compliant, while PostgreSQL is.
This blog post explains to you which tools to use to serve geospatial data from a database system (PostgreSQL) to your web browser. At Zalando, the open source database system PostgreSQL is used by many teams and it offers a geospatial component called PostGIS. CREATE OR REPLACE FUNCTION geodata. j , sum ( p. popcount ) * 0.
Let’s walk through how to build this system step by step, using PostgreSQL examples to make it real and actionable. Once youve got a good grip on whats in your database and what counts as sensitive, youre ready to start digging into PostgreSQL. Step 2: Hunt Down the Sensitive Stuff Now its time to play detective in your database.
In the database ecosystem, Postgres is one of the top open-source databases, and one of the most widely used PSQL tools for managing PostgreSQL is pgAdmin. To run PostgreSQL instances on the Azure cloud, Azure offers Azure Database for PostgreSQL. What are PostgreSQL Tools? Why Use a GUI Tool?
MongoDB Atlas excels at storing and processing unstructured and semi-structured data, while PostgreSQL offers scalability and advanced analytics. MongoDB Atlas to PostgreSQL integration forms a robust ecosystem that addresses the technical challenges associated with data management and analysis.
Data analysts create reports that are used by the business to understand and direct the business, but the process is very labor and time intensive. Materialize’s PostgreSQL-compatible interface lets users leverage the tools they already use, with unsurpassed simplicity enabled by full ANSI SQL support.
Amazon RDS, with its support for the PostgreSQL database, is a popular choice for businesses looking for reliable relational database services. However, the increasing need for advanced analytics and large-scale data processing requires migrating data to more efficient platforms like Databricks.
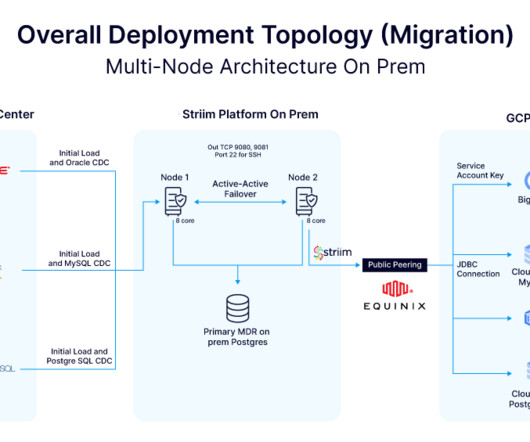
Also, for other industries like retail, telecom or public sector that deal with large amounts of customer data and operate multi-tenant environments, sometimes with end users who are outside of their company, securing all the data may be a very time intensive process. CDW uses various Azure services to provide the infrastructure it requires.
We knew we’d be deploying a Docker container to Fargate as well as using an Amazon Aurora PostgreSQL database and Terraform to model our infrastructure as code. Set up a locally running containerized PostgreSQL database. This isn’t necessary for your application, but it definitely speeds up the development process.
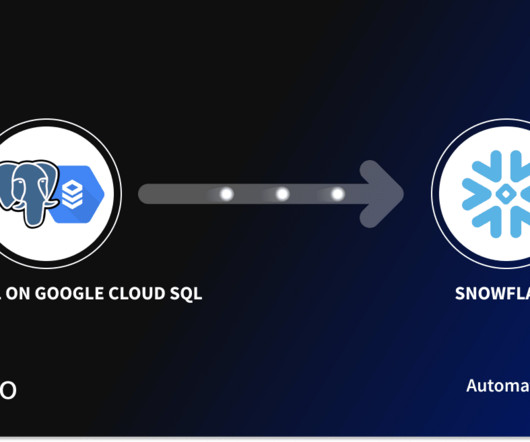
Google Cloud SQL for PostgreSQL, a part of Google’s robust cloud ecosystem, offers businesses a dependable solution for managing relational data. However, with the expanding need for advanced data analytics, it is required to integrate data storage and processing platforms like Snowflake.
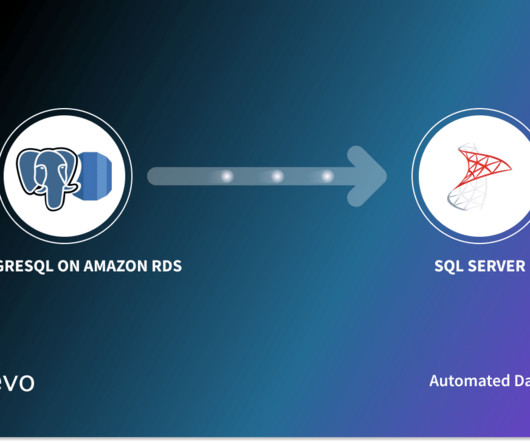
There are several reasons why data replication from PostgreSQL on Amazon RDS to SQL Server may become necessary. These reasons include changes in business processes, increased data volumes, and enhanced performance requirements.
Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL. With other ingestion improvements and our new database connectors, we are smoothing out the data ingestion process, making it radically simple and efficient to bring data to Snowflake.
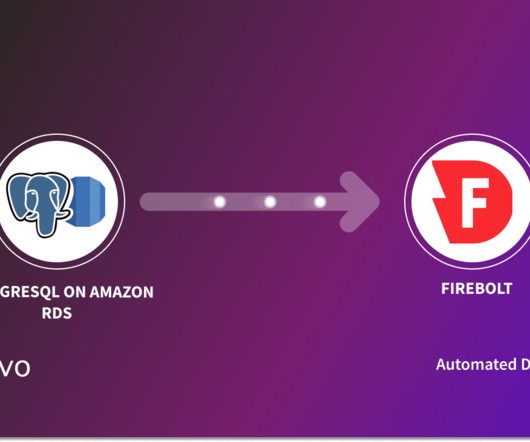
Migrating data between two platforms is a critical process for organizations to leverage the power of advanced analytics. The migration from PostgreSQL on Amazon RDS to Firebolt is one such example of how businesses can unlock the full potential of their data.
It’s hosted in the PostgreSQL and used to serve item metadata to the Dasher, our name for delivery drivers, during order fulfillment. As part of the first phase of migration, we worked with our customers to migrate to Retail Fulfillment Data Service (RFDS) as we continue to work the rest of the migration process.
Summary Processing high velocity time-series data in real-time is a complex challenge. Given the fact that it is a plugin for PostgreSQL, what level of compatibility exists between PipelineDB and other plugins such as Timescale and Citus? Can you start by explaining what PipelineDB is and the motivation for creating it?
In this episode Vignesh Ravichandran explains how his team at Cloudflare provides PostgreSQL as a service to their developers for low latency and high uptime services at global scale. In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? Datafold : . To find answers, we tested how different configurations of PostgreSQL influenced the results of the query planner. PostgreSQL also addresses non-uniform distributions.
Close alignment with actual business processes : Business processes and metrics are modeled and calculated as part of dimensional modeling. Part 1: Setup dbt project and database Step 1: Install project dependencies Before you can get started: You must have either DuckDB or PostgreSQL installed.
release, how the use cases for timeseries data have proliferated, and how they are continuing to simplify the task of processing your time oriented events. How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product?
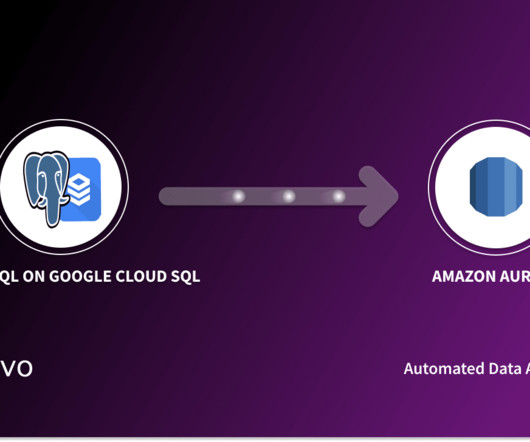
To unlock the full potential of your data in PostgreSQL on Google Cloud SQL necessitates data integration with Amazon Aurora. This migration offers several advantages, such as enhanced data processing speed and availability, enabling data-driven […]
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. SQL has traditionally been challenging to compose.
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. What are the platform capabilities that are required to make it possible?
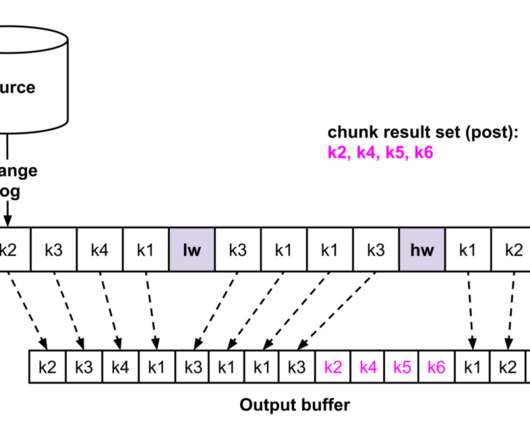
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. This motivated the development of DBLog , which offers log and dump processing under a generic framework. Some of DBLog’s features are: Processes captured log events in-order. This way log processing can progress alongside dump processing.
Complexity in Data Replication : Moving data between platforms, particularly from legacy systems to newer ones, was a time-consuming and resource-intensive process. Multiple Teams Using Different Tools : Various departments, including migration and supply chain teams, used different tools and processes to manage their data.
This was an interesting inside look at building a business on top of open source stream processing frameworks and how to reduce the burden on end users. What are some of the most interesting, unexpected, or challenging lessons that you have learned in the process of building and scaling Eventador?
When it comes to migrating data from MongoDB to PostgreSQL, I’ve had my fair share of trying different methods and even making rookie mistakes, only to learn from them.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content