This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
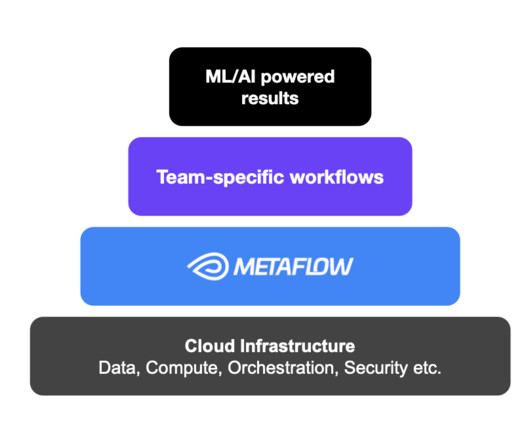
I’d like to share a story about an educational side project which could prove fruitful for a software engineer who’s seeking a new job. Juraj created a systems design explainer on how he built this project, and the technologies used: The systems design diagram for the Rides application The app uses: Node.js
Identify what tool to use to process data 3.3. Define what the output dataset will look like 3.1.3. Define SLAs so stakeholders know what to expect 3.1.4. Define checks to ensure the output dataset is usable 3.2. Data flow architecture 3.
Were thrilled to announce the release of a new Cloudera Accelerator for Machine Learning (ML) Projects (AMP): Summarization with Gemini from Vertex AI . Benchmark tests indicate that Gemini Pro demonstrates superior speed in token processing compared to its competitors like GPT-4.
Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams. How can you get the best results for your use case?
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Summary Streaming data processing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. If you've learned something or tried out a project from the show then tell us about it!
To solve this, we’ll apply Projection Policies to ensure that only certain roles can see sensitive columns like Customer numbers. Snowflake provides several layers of data security, including Projection Policies , Masking Policies , and Row Access Policies , that work together to restrict access based on roles.
Summary The dbt project has become overwhelmingly popular across analytics and data engineering teams. Dustin Dorsey and Cameron Cyr co-authored a practical guide to building your dbt project. In this episode they share their hard-won wisdom about how to build and scale your dbt projects. What was your path to adoption of dbt?
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
In today’s construction market, owners, construction managers, and contractors must navigate increasing challenges, from cost management to project delays. Fortunately, digital tools now offer valuable insights to help mitigate these risks. That’s where data-driven construction comes in.
Summary Data processing technologies have dramatically improved in their sophistication and raw throughput. When performing research and building prototypes of the projects, what is your process for incorporating user experience into the implementation of the product? Email hosts@dataengineeringpodcast.com ) with your story.
Explore how the Skeleton-of-Thought prompt engineering technique enhances generative AI by reducing latency, offering structured output, and optimizing projects.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Assumptions mapping is the process of identifying and testing your riskiest ideas. You'll learn: Why every product leader goes into a new project with untested, hidden assumptions. You'll learn: Why every product leader goes into a new project with untested, hidden assumptions.
In particular, we expect both Business Intelligence and Data Engineering will be driven by AI operating on top of the context defined in your dbt Projects. Weve known for a while that the combination of structured data from your dbt project + LLMs is a potent combo (particularly when using the dbt Semantic Layer).
Natural Language Processing (NLP) has transformed technology by allowing machines to understand, decode, and generate human language. NLP plays a crucial role in multiple domains and NLP projects ranging from its automating customer service, improving search engines, or analyzing social media sentiments.
Summary Working with data is a complicated process, with numerous chances for something to go wrong. To bring observability to dbt projects the team at Elementary embedded themselves into the workflow. Can you start by outlining what elements of observability are most relevant for dbt projects?
This project helped onboard me to the software, its structure, its build, and our issue tracking and version control workflows. My first project was supporting i18n (internationalization) in the app. My goal was to fix the debt of hardcoded strings, but I learned a lot about the codebase and our process as I did it.
Introduction Data is fuel for the IT industry and the Data Science Project in today’s online world. Handling and processing the streaming data is the hardest work for Data Analysis. IT industries rely heavily on real-time insights derived from streaming data sources.
Tommy has built his own video games, consulted on a wide variety of game projects, and for a decade has taught game development at various universities. Each project typically takes several years to create, with shifting hardware specifications and emerging competitors and trends to anticipate and react to, during the process.
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
Project demo 3. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Introduction 2. Building efficient data pipelines with DuckDB 4.1. Use DuckDB 4.4.
Avoiding downtime was nerve-wracking, and the notion of a 'rollback' was as much a relief as a technical process. After this zero-byte file was deployed to prod, the Apache web server processes slowly picked up the empty configuration file. Our deployments were initially manual. Apache started to log like a maniac.
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns. Internal comms: Chat: Slack Coordination / project management: Linear 3.
dbt Labs also develop dbt Cloud which is a cloud product that hosts and runs dbt Core projects. a dbt project — a dbt project is a folder that contains all the dbt objects needed to work. You can initialise a project with the CLI command: dbt init. In a dbt project you can define YAML file everywhere.
Our customers rely on NiFi as well as the associated sub-projects (Apache MiNiFi and Registry) to connect to structured, unstructured, and multi-modal data from a variety of data sources – from edge devices to SaaS tools to server logs and change data capture streams. Accelerating GenAI with Powerful New Capabilities Cloudera DataFlow 2.9
The project showed that smaller, empowered teams achieve higher impact than larger ones. These small, cross-functional teams ensured that members were deeply involved in the project operations, the technical setup, and the feedback cycle, leading to fewer delays, fewer bottlenecks, and faster decision-making.
Customer intelligence teams analyze reviews and forum comments to identify sentiment trends, while support teams process tickets to uncover product issues and inform gaps in a product roadmap. As data volumes grow and AI automation expands, cost efficiency in processing with LLMs depends on both system architecture and model flexibility.
This dampens confidence in the data and hampers access, in turn impacting the speed to launch new AI and analytic projects. This guarantees data quality and automates the laborious, manual processes required to maintain data reliability.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in data lakes and lakehouses. AI projects should not be about “the latest” or “the best.” Leadership will be the antidote to AI exhaustion.
These processes were costly and time-consuming and also introduced governance and security risks, as once data is moved, customers lose all control. We take care of planning, executing and verifying upgrades, and we do so using a rolling process without downtime. As a result, data often went underutilized.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent. ' "scikit-learn": '1.4.0'
So, why do so many automation projects fail to deliver? Let’s break down the practical steps to make automation and AI projects successful and discuss common pitfalls. Examples include “reduce data processing time by 30%” or “minimize manual data entry errors by 50%.”
In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Data projects are notoriously complex.
Enterprises are very security conscious when it comes to their data and their AI projects. Even with our own certifications, the security review process during deal cycles can be lengthy and really slow down momentum. How do security concerns impact the deployment of your platform?
We all know how it feels: staring at the terminal while your development server starts up, or watching your CI/CD pipeline crawl through yet another build process. Webpack processes everything through JavaScript, which is single-threaded by nature and slower at CPU-intensive tasks compared to lower-level languages like Go or Rust.
There are multiple ways to start a new year, either with new projects, new ideas, new resolutions or by just keeping doing the same music. HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. I hope you will enjoy 2025. Thank you so much for your support through the years.
Recognize that artificial intelligence is a data governance accelerator and a process that must be governed to monitor ethical considerations and risk. Align people, processes, and technology Successful data governance requires a holistic approach. Tools are important, but they need to complement your strategy.
Scrum is a quality-driven process for producing excellent business outcomes. This certification is not as well-known as the PSM (Professional Scrum Master™) I, but it is a fantastic choice if you are interested in product ownership (for example, if you are a business analyst who wants to start working on Scrum projects).
and Executive Chairman of LandingAI, Andrew Ng, has long been a leading proponent of AI agents and agentic workflows — the iterative processes of multiple AI agents collaborating to solve problems and ultimately carry out complex tasks automatically.
However, with the introduction of the Transformer architecture—initially successful in Natural Language Processing (NLP)—the landscape has shifted. Then, a linear projection on the flattened patches is introduced, and positional embeddings are added. Each flattened patch is passed through a learnable linear projection.
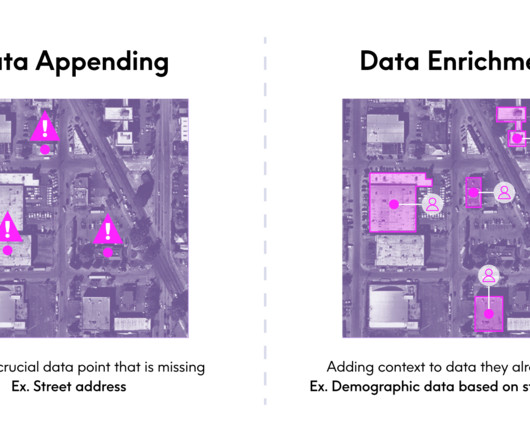
The solution: They use a data appending process to match their existing data with a third-party database that contains full street addresses. Our Chief Data Officer, Dave Shuman, recently walked through a data appending and enrichment project for our CRM data. Why does this matter?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content