This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether tracking user behavior on a website, processing financial transactions, or monitoring smart devices, the need to make sense of this data is growing. But when it comes to handling this data, businesses must decide between two key processes - batch processing vs stream processing.
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. The greater the claim made using analytics, the greater the scrutiny on the process should be.
This blog aims to give you an overview of the data analysis process with a real-world business use case. Table of Contents The Motivation Behind Data Analysis Process What is Data Analysis? What is the goal of the analysis phase of the data analysis process? What is Data Analysis?
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
However, the sheer volume of tools and the complexity of leveraging their data effectively can be daunting. That’s where data-driven construction comes in. It integrates these digital solutions into everyday workflows, turning rawdata into actionable insights.
We created data logs as a solution to provide users who want more granular information with access to data stored in Hive. In this context, an individual data log entry is a formatted version of a single row of data from Hive that has been processed to make the underlying data transparent and easy to understand.
An important part of this journey is the data validation and enrichment process. Defining Data Validation and Enrichment Processes Before we explore the benefits of data validation and enrichment and how these processes support the data you need for powerful decision-making, let’s define each term.
From handling missing values to merging datasets and performing advanced transformations, our cheatsheet will equip you with the skills needed to unleash the full potential of the Pandas library in real-world data analysis projects. Loading data into a DataFrame Here, you will explore different methods to load external data into a DataFrame.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities.
At Netflix, we embarked on a journey to build a robust event processing platform that not only meets the current demands but also scales for future needs. This blog post delves into the architectural evolution and technical decisions that underpin our Ads event processing pipeline.
For years, Snowflake has been laser-focused on reducing these complexities, designing a platform that streamlines organizational workflows and empowers data teams to concentrate on what truly matters: driving innovation. This native integration streamlines development and accelerates the delivery of transformed data.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
Code and rawdata repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns. Internal comms: Chat: Slack Coordination / project management: Linear 3.
And this technology of Natural Language Processing is available to all businesses. Available methods for text processing and which one to choose. Specifics of data used in NLP. What is Natural Language Processing? Here are some big text processing types and how they can be applied in real life. Main NLP use cases.
For data analysts and engineers, the journey from rawdata to actionable business insights for business users is never as simple as it sounds. The semantic layer is a critical component in this process, serving as the bridge between complex data sources and the business logic required for informed decision-making.
Welcome to the world of Machine Learning, where we will discover how machines learn from data, make predictions and decisions like magic. From Python coding to real-world AI applications, let us dive in and demystify the machine learning process together. Table of Contents Machine Learning Process: How Does Machine Learning Work?
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
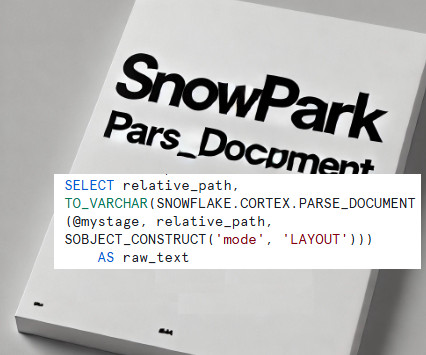
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. Why Use PARSE_DOC?
Today enterprises can leverage the combination of Cloudera and Snowflake—two best-of-breed tools for ingestion, processing and consumption of data—for a single source of truth across all data, analytics, and AI workloads.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. They need to: Consolidate rawdata from orders, customers, and products.
Cloud computing is the future, given that the data being produced and processed is increasing exponentially. As per the March 2022 report by statista.com, the volume for global data creation is likely to grow to more than 180 zettabytes over the next five years, whereas it was 64.2 zettabytes in 2020.
It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). It will be used to process and organize the text properly. View full parsed rawdata") print("2. View full parsed rawdata 2.
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for data pipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
Mohan Talla May 30, 2025 11 min read Building and orchestrating a new data pipeline can feel daunting. Fortunately, Teradata offers integrations to many modular tools that facilitate routine processes allowing data engineers to focus on high-value tasks such as governance, data quality, and efficiency. dagster-dbt==0.23.9
Today, data engineers are constantly dealing with a flood of information and the challenge of turning it into something useful. The journey from rawdata to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process.
All the data preparation steps for machine learning algorithms implementation will be covered along with tools. Table of Contents What is Data Preparation for Machine Learning? Data preparation is usually the first step when one tries to solve real-world problems using ML. csv", which is compatible with data analytics tools.
However, the modern data ecosystem encompasses a mix of unstructured and semi-structured data—spanning text, images, videos, IoT streams, and more—these legacy systems fall short in terms of scalability, flexibility, and cost efficiency. That’s where data lakes come in.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now.
Data preparation tools are very important in the analytics process. They transform rawdata into a clean and structured format ready for analysis. These tools simplify complex data-wrangling tasks like cleaning, merging, and formatting, thus saving precious time for analysts and data teams.
We will now describe the difference between these three different career titles, so you get a better understanding of them: Data Engineer A data engineer is a person who builds architecture for data storage. They can store large amounts of data in dataprocessing systems and convert rawdata into a usable format.
AI today involves ML, advanced analytics, computer vision, natural language processing, autonomous agents, and more. It means combining data engineering, model ops, governance, and collaboration in a single, streamlined environment. Beyond Buzzwords: Real Results We know AI can sound like hype.
Data engineering is the foundation for data science and analytics by integrating in-depth knowledge of data technology, reliable data governance and security, and a solid grasp of dataprocessing. Data engineers need to meet various requirements to build data pipelines.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
Would you like help maintaining high-quality data across every layer of your Medallion Architecture? Like an Olympic athlete training for the gold, your data needs a continuous, iterative process to maintain peak performance.
Strobelight is also not a single profiler but an orchestrator of many different profilers (even ad-hoc ones) that runs on all production hosts at Meta, collecting detailed information about CPU usage, memory allocations, and other performance metrics from running processes.
It starts with data selection from one or more data sources, then moves on to data transformation within a staging framework. Finally, you can store the collected and altered data in a warehouse for storage and analysis. It consists of extracting data and loading it into the target server/data warehouse in its raw form.
This combination streamlines ETL processes, increases flexibility, and reduces manual coding. In this blog, I walk you through a use case where DBT orchestrates an automated S3-to-Snowflake ingestion flow using Snowflake capabilities like file handling, schema inference, and data loading. But Isnt DBT Just for Transformations?
The architecture of Microsoft Fabric is based on several essential elements that work together to simplify dataprocesses: 1. OneLake Data Lake OneLake provides a centralized data repository and is the fundamental storage layer of Microsoft Fabric. Transform Your Data Analytics with Microsoft Fabric!
As she deals with vast amounts of data from multiple sources, Emily seeks a solution to transform this rawdata into valuable insights. Emily can efficiently process, clean, and transform data by seamlessly merging dbt's data transformation features with Snowflake's scalable cloud data warehouses. "dbt
Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. Store the data in in Google Cloud Storage to ensure scalability and reliability.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform rawdata into actionable insights. You’ll walk through each stage of the dataprocessing workflow, similar to what’s used in production-grade systems. Python fits that role perfectly.
Over the years, individuals and businesses have continuously become data-driven. The urge to implement data-driven insights into business processes has consequently increased the data volumes involved. Open source tools like Apache Airflow have been developed to cope with the challenges of handling voluminous data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content