This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Considering how most industries have rapidly evolved thanks to technology, upgrading grids has been of utmost importance for utility companies out there. The application of Artificial Intelligence (AI) technology into grid structures is now a game changer for utility managers.
The energy and utility industry is being transformed by AI technology, and it is powered by the digital revolution. One of its newest forms, Generative AI, is bolstering utility operations reliability, efficiency, and resilience. Its place in modern utilities is most evident in real-time fault detection.
How will generative AI shape the tools and processes Data Engineers rely on today? GenAI is already transforming how data is managed, analyzed, and utilized, paving the way for […] The post Top 11 GenAI Powered Data Engineering Tools to Follow in 2025 appeared first on Analytics Vidhya.
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used. Hack, C++, Python, etc.)
What is Real-Time Stream Processing? To access real-time data, organizations are turning to stream processing. To access real-time data, organizations are turning to stream processing. There are two main data processing paradigms: batch processing and stream processing.
The name comes from the concept of “spare cores:” machines currently unused, which can be reclaimed at any time, that cloud providers tend to offer at a steep discount to keep server utilization high. Spare Cores attempts to make it easier to compare prices across cloud providers. Source: Spare Cores. Tech stack.
How to Stream and Apply Real-Time Prediction Models on High-Throughput Time-Series Data Photo by JJ Ying on Unsplash Most of the stream processing libraries are not python friendly while the majority of machine learning and data mining libraries are python based. This design enables the re-reading of old messages.
Strobelight combines several technologies, many open source, into a single service that helps engineers at Meta improve efficiency and utilization across our fleet. Engineers and developers can use this information to identify performance and resource bottlenecks, optimize their code, and improve utilization. Python, Java, and Erlang).
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Balancing correctness, latency, and cost in unbounded data processing Image created by the author. Intro Google Dataflow is a fully managed data processing service that provides serverless unified stream and batch data processing. It is the first choice Google would recommend when dealing with a stream processing workload.
Specifically, we have adopted a “shift-left” approach, integrating data schematization and annotations early in the product development process. However, conducting these processes outside of developer workflows presented challenges in terms of accuracy and timeliness.
The change control process is a crucial aspect of project management intended to manage and regulate changes made to the project plan, schedule, and budget. These change control process steps are planning, analyzing, approval, testing, implementing, and closing. The change request kickstarts the process of change control.
KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts. By enabling advanced analytics and centralized document management, Digityze AI helps pharmaceutical manufacturers eliminate data silos and accelerate data sharing.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
The product development process is just as vital as product management; both seem similar but have subtle variances. Product development focuses on the creation of a product, whereas The entire process is overseen by product management. What Is the Product Development Process? It involves seven product development process steps.
Introducing sufficient jitter to the flush process can further reduce contention. By creating multiple topic partitions and hashing the counter key to a specific partition, we ensure that the same set of counters are processed by the same set of consumers. This process can also be used to track the provenance of increments.
If country_iso_code doesnt already exist in the fact table, the metric owner only needs to tell DJ that account_id is the foreign key to an `users_dimension_table` (we call this process dimension linking ). DJ then can perform the joins to bring in any requested dimensions from `users_dimension_table`.
The company utilizes Google Cloud to some extent, and my understanding from talking with Twitter engineers is that this was for machine learning (ML) use cases. It surely helped the Threads team that they could utilize the infrastructure of Instagram. Twitter runs its infrastructure on three of its own data centers.
Avoiding downtime was nerve-wracking, and the notion of a 'rollback' was as much a relief as a technical process. After this zero-byte file was deployed to prod, the Apache web server processes slowly picked up the empty configuration file. Our deployments were initially manual. Apache started to log like a maniac.
Managing and utilizing data effectively is crucial for organizational success in today's fast-paced technological landscape. Manual processes can be time-consuming and error-prone. Agentic AI automates these processes, helping ensure data integrity and offering real-time insights.
But when data processes fail to match the increased demand for insights, organizations face bottlenecks and missed opportunities. This elasticity allows data pipelines to scale up or down as needed, optimizing resource utilization and cost efficiency. Regularly review usage patterns and adjust cloud resource allocation as needed.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. You can read this here. Serving a web page.
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for data pipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
Fluss is a compelling new project in the realm of real-time data processing. It works with streaming processing like Flink and Lakehouse formats like Iceberg and Paimon. Fluss focuses on storing streaming data and does not offer streaming processing capabilities. It excels in event-driven architectures and data pipelines.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
We are still working on processing the backlog of asynchronous Lambda invocations that accumulated during the event, including invocations from other AWS services (such as SQS and EventBridge). As of 3:37 PM PDT, the backlog was fully processed. We are continuing to work to fully recover all services.
Leap second smearing a solution past its time Leap second smearing is a process of adjusting the speeds of clocks to accommodate the correction that has been a common method for handling leap seconds. The service continues to utilize TAI timestamps but can return UTC timestamps to clients via the API. microseconds.
Additionally, RxJS in Angular offers a full set of tools made to easily handle asynchronous processes and reactive programming. This blog post will talk about how RxJS in Angular helps developers handle data streams, handle complicated asynchronous processes, and make responsive and useful apps. Common RxJS Operations in Angular 1.
Before we start: plenty of people who subscribe to the newsletter utilize a learning and development budget their company provides. The period from April to mid-May was challenging: I found myself in hiring freezes and canceled processes. ’ How did you find the interview processes?
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). It employs a two-tower model approach to learn query and item embeddings from user engagement data.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Optimizing the server initialization process for Atlas is vital for maintaining the high availability and performance of the ThoughtSpot system.
AIOps, or artificial intelligence for IT operations, combines AI technologies like machine learning, natural language processing, and predictive analytics, with traditional IT operations. Understanding AI Operations (AIOps) in IT Environments What is AIOps? This empowers you to take a more proactive approach to protecting your systems.
Snowflake customers now have a unified platform for processing and retrieval of both structured and unstructured data with high accuracy out-of-the-box. Planning: Applications often switch between processing data from structured and unstructured sources. The workflow involves four key components: 1.
This article will cover the following topics: Performance improvement process Strategies to profile streaming pipelines Common performance problems General guidelines to improve performance Performance Improvement Process The performance improvement of any software system is not an independent and isolated task but an iterative process.
Liang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform | In today’s data-driven world, businesses need to process and analyze data in real-time to make informed decisions. Real-Time Data Processing : CDC enables real-time data processing by capturing changes as they happen.
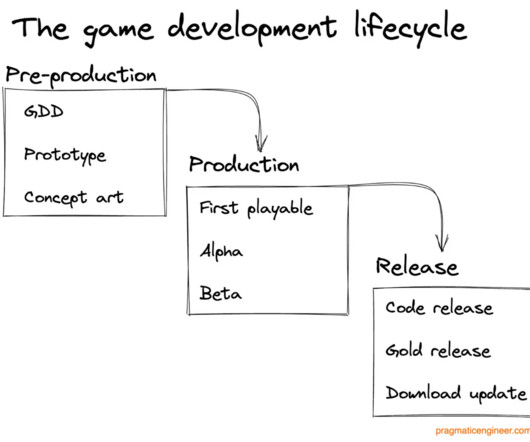
Over a week, participants build their own game utilizing AI in some form. Each project typically takes several years to create, with shifting hardware specifications and emerging competitors and trends to anticipate and react to, during the process. Learn more or sign up if you’re interested. Prototype vs final version.
These processes were costly and time-consuming and also introduced governance and security risks, as once data is moved, customers lose all control. We take care of planning, executing and verifying upgrades, and we do so using a rolling process without downtime. As a result, data often went underutilized.
Built on Timely Dataflow and Differential Dataflow, open source frameworks created by cofounder Frank McSherry at Microsoft Research, Materialize is trusted by data and engineering teams at Ramp, Pluralsight, Onward and more to build real-time data products without the cost, complexity, and development time of stream processing.
As this is rolled out, security-conscious users who utilize the verify security code page will notice this verification process occurs quickly and automatically. The private key is what you utilize to decrypt your messages sent from another party and never leaves your device. this needs to be redone for all participants.
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. The learning mostly involves understanding the data's nature, frequency of data processing, and awareness of the computing cost.
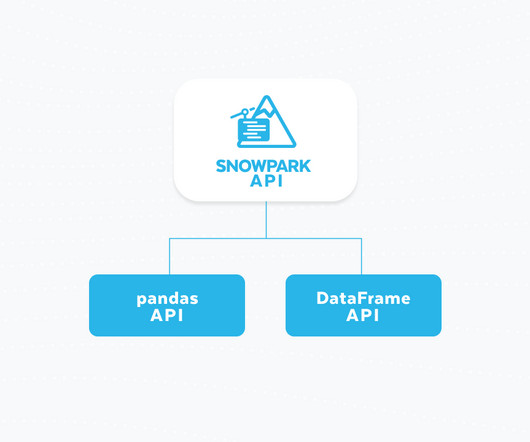
In April 2024, Snowflake customers ran approximately 55 million queries in Snowpark on average each day for a spectrum of large-scale data processing tasks in data engineering and data science. pandas is the go-to data processing library for millions worldwide, including countless Snowflake users.
This transition process will roll out gradually and is expected to take several months.” Why would a company like Google not utilize its status page to display the real status of the service? Google Domains will work with Squarespace to make the transition as seamless as possible for you.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling.
Data enrichment is the process of augmenting your organizations internal data with trusted, curated third-party datasets. And yet, there are inherent struggles with this process especially when integrating data from multiple providers. Well, those processes are now streamlined like never before. What is Data Enrichment?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content